Day05::300埋め+Janomeのインストール
Day5
- AtCoder 300点問題を5問解いた
- 形態素解析エンジンを入れた
令和時代
記念復習AC
ABC 070: C – Multiple Clocks
LCMを求めた.2数のLCMの計算量は$O(\log N)$らしいです.確かにそれはそうだった.
ABC 073: C – Write and Erase
おねえちゃんと数字を言い続けるゲームをしたかった.
mapで解いた.
ABC 075: C – Bridge
いい問題だった.UnionFindを使いました.多分これが一番早いと思います(ほんとうに?).
UnionFindのテンプレートは以下のような感じで
struct UF { public: ll tsize; ll mode; ll connect = 0; vll nodeSize; vll par; vll rank; UF(){}; UF(const UF &uf) {} UF(ll _size, ll _mode = 0) { tsize = _size; mode = _mode; par.assign(tsize, -1); if (!mode) rank.resize(tsize, 0); nodeSize.resize(tsize, 1); } ll root(ll x) { return par[x] < 0 ? x : par[x] = root(par[x]); } bool isRoot(ll x) { return root(x) == x; } void unite(ll x, ll y) { x = root(x); y = root(y); if (x == y) return; if (mode) { par[x] += par[y]; par[y] += x; } else { connect -= sumOfRange(nodeSize[x]) + sumOfRange(nodeSize[y]); connect += sumOfRange(nodeSize[x] + nodeSize[y]); if (rank[x] < rank[y]) { nodeSize[y] += nodeSize[x]; par[y] += par[x]; par[x] = y; } else { nodeSize[x] += nodeSize[y]; par[x] += par[y]; par[y] = x; if (rank[x] == rank[y]) rank[x]++; } } } bool same(ll x, ll y) { return root(x) == root(y); } ll size(ll x) { return -par[root(x)]; } };
テンプレートとして持ってたりするのですが,前は連結要素数を保持していなくて痛い目見ました.猛省.
ABC 076: C – Dubious Document 2
やってることは単純なんだけどミスりそうな点が色々ありそうな問題.
ABC 079: C – Train Ticket
車のナンバーで合計10にするのをやってたので秒でACできました.嘘です(エイプリルフール).
形態素解析エンジン
MeCabあたりの辞書がとても有名ですが,怠惰なので同様にNeologd辞書が使えるJanomeをインストールしました.
Neologd対応するためにはこちらを参照.
ビルド済みのものを入れることでとても簡単にインストールできます.
試しに実行します
from janome.tokenizer import Tokenizer tokenizer = Tokenizer(mmap=True) tokenizer.tokenize("はい,ひょっこりはん", wakati=True) # ['はい', ',', 'ひょっこりはん']
固有名詞をしっかり分類できています.やったね.これだけではつまらないのでワードクラウドを作ります.
$ pip install wordcloud twitter
import twitter import re consumer_key='hoge' consumer_secret='huga' access_token_key='piyo' access_token_secret='hogehoge' api = twitter.Twitter(auth=twitter.OAuth( access_token_key, access_token_secret, consumer_key, consumer_secret ))
app申請してもらったAPIトークンなどを入れます.
# TLのメッセージを形態素解析して名詞の頻度を表示 txts = " " for tweet in tl: txt = tweet["text"] txt = re.sub(r"(@\w+:|RT|http.+)", "", txt) tokens = tokenizer.tokenize(txt) nouns = [] for token in tokens: if token.part_of_speech.split(',')[0] == '名詞': nouns.append(token.surface) txts += " ".join(nouns) from wordcloud import WordCloud wc = WordCloud( background_color="white", font_path="/System/Library/Fonts/ヒラギノ角ゴシック W7.ttc", width=800, height=600 ).generate(" ".join(txts)) wc.to_file("./wordcloud_sample.png")
これだけでワードクラウドが作れてしまいます.簡単すぎて驚きました.

時期が時期なので新元号一色です.
Day04::300点の埋め始め
Day4
- AtCoder300点を5問解いた
300点からやっと本番が始まる感じがします.4月中には埋めようかと思います!!!
ABC 051: C – Back and Forth
string(7, 'Z')
という書き方でPythonの
"Z" * 7
のように文字の掛け算ができる.
しかし文字列をかけたい際はどうすればいいか分かんない.(募集中です)
ABC 054: C – One-stroke Path
よくあるDFS.よくあるけど結構時間掛かってしまった.猛省.
ABC 057: C – Digits in Multiplication
約数全列挙は$O(\sqrt{N})$なので間に合った.
ABC 061: C – Big Array
制約条件の解釈に時間がかかりました.日本語の構文解析が世界一下手な気持ちになりました.
signed main() { llin(N); llin(K); vpllin(vp, N); SORT_ASC(vp); // この行を忘れてWAした vll s = {0}; REP(i, N) { s.pb(s[i] + vp[i].second); } ll arg = ARG(s, UB(s, K - 1)) - 1; //二分探索 echo(vp[arg].first); }
ABC 064: C – Colorful Leaderboard
レート3200以上の人の数を入れる変数の名前をtouristにしました.
if(a[i] >= 3200) { tourist++; }else { c[a[i] / 400] |= true; }
Dat03::AtCoder 200点埋めをした
Day3
- AtCoderの200点の過去問埋め
- BTE on Mac
- 帰省
200点の割に苦戦した問題
100点よりは骨がありましたが,それほどほとんど迷うことはなかった印象です.しかし,中にはとてもじゃないが200点とは思えない問題がありました.特にAGC-A問題にその傾向は強めです.出題者の吹っ切れ具合が伝わってきました.
AtCoder Grand Contest 023 A - Zero-Sum Ranges
高度なアルゴリズムである累積和を使う問題です.数列の部分和は累積和という事前知識はいまでこそTLを見たりして身についてたのですが,初見全く歯が立ちませんでした.
CODE FESTIVAL 2017 qual B B - Problem Set
調子乗って二分探索で解こうとしてTLEになりました.ループ$M$でにぶたんが$\log_2N$なので通ると思ったのですがTLEでした.これならTLEになりそうだなという感覚を身につけるの大事ですね.
TLE
Keyence B - KEYENCE String
コンテスト中にKEYENCEを二つに分割した部分文字列全体で探索するという超単純なアルゴリズムが思い浮かばず1完になってしまった.猛省...
全国統一プログラミング王決定戦 エキシビジョン C - 11で割った余りの計算方法
整数 $M$を $11$で割った余りは、$M$ の下から奇数桁目の数の和 から $M$ の下から偶数桁目の数の和 を引いた値を $11$で割った余りと一致します。 整数 $N$が与えられます.$N$を $11$で割った余りを出力してください。
まさかとは思いますがこんなコードで提出しようとは思っていませんね!?
#include <iostream> using namespace std; int main() { int N; cin >> N; cout << N % 11 << endl; }
Day02::音声認識(2),動的計画法
Day2
- 音声認識本の続き
- DPという言葉が出てきたのでDPの問題をといた
まえのひ
音声認識の方法
一言に音声認識といっても,単語の認識なのか,それとも文章(単語列)の認識なのかによって適用されるアルゴリズムが異なります.
離散単語認識では,予め決められた語彙のうちから発声された単語が何なのかを当てるタスクです.単語間の前後関係の考慮が不必要なのでアルゴリズムは比較的単純で済む場合が多いです.
対して,連続的な単語列の認識では,単語間の前後関係1を把握する必要があります.連続的な場合においては,電話番号や郵便番号などといった限られた語彙間の推移を有限状態オートマトンなどで推定するような比較的単純なタスクである連続音声認識と,膨大な語彙の文を認識させる文認識へと細分化されます.
加えて,語彙の発声は個人差が大きく存在します.なので特定の話者のデータで学習を行えばその話者に対する精度ばかりが高くなります.これは特定話者音声認識とよばれ,ディクテーションなどの用途に特化していると言えます.対して話者が不特定の場合は,不特定話者音声認識と呼ばれます.
特徴量の量子化
音声認識の分野では度々単語間の類似度を図るために,特徴ベクトル間の距離(=類似度合い)を測定したい場合があります.その際に,特徴ベクトル間類似度の計測が実数値を取るような高次元のベクトルでは,計算量が嵩むようなものが存在すします.そこで,計算資源を節約するために,ベクトル量子化と呼ばれるアルゴリズムを適用します.ベクトル量子化では,特徴量ベクトルの取りうる空間を重複の無いように分割し,各々の空間に対して離散的な何かしらのシンボルを付与することで高次元の特徴ベクトルではなく,シンボルを記憶するだけで済み,計算量の大幅な削減が見込めます.もちろん,計算量を向上する代わりに実際の距離とは乖離が生じますが,この劣化は量子化ひずみとも呼ばれます.
空間分割のためのアルゴリズムとしては$k-$meansアルゴリズムなどが採用されています.そのアルゴリズムで得られたセントロイド(早い話が重心)はコードベクトル,その点に割り当てた一意な符号をコードワードなどと呼ばれます.
DPマッチング
離散単語の認識を考えます.まずは,特定話者が語彙の各々を発生して音声認識の標準パターンを作成していると仮定した場合を考えましょう.
この場合の認識タスクは,可変長の入力データと,同じく可変長の単語の標準データとの間の類似度の計算に相当します.固定長の場合には各々の要素間の距離を測ることで簡単に達成できますが,可変長の場合には,フレーム間をどのように対応付けるべきかが認識する上では非常に重要となります.ただ単に全通りを探索するとなると,組み合わせは$NM$となり全く現実的ではありません.
そこで計算量を削減するために考案されたのがDPマッチングです2.
DPマッチングでは,まず単語列をベクトル量子化をします.そうすることで,2つの単語間の距離は予め保存しておいたフレーム間を参照するだけで済みます.
入力単語列$A=\{a_1,a_2,...,a_N\}$と,標準パターン$B=\{b_1,b_2,...,b_M\}$および任意のA,Bの元の間の距離$d(a_i,b_j)$が分かっている際,DPマッチングは,以下のような座標系における点$c_1=(1,1)$から点$c_k=(i_k,j_k)$までの距離の累積和を$g(c_k)$とした際に,点$c_K=(a_N,b_M)$までの累積和を最小化させる効率的なアルゴリズムです.
また,音声の性質に対して,このDP平面上の座標の増加は時間の経過に等しいことから,逆方向にDP平面状を進むことはありませんし,途中の音韻を抜き去ることは別の単語となる可能性があるためあまり考えられないでしょう.すなわち,以下の単調連続性の制約を課すことができます. $$ i_{k+1}=i_k\textrm{or}i_k+1,j_{k+1}=j_k\textrm{or}j_k+1 $$ ここで,累積和をマンハッタン距離 $$ w_k=(i_k-i_{k-1})+(j_k-j_{k-1}) $$ を用いて $$ g(c_K)=\frac{1}{N+M}\sum_{k=1}^{K}d(c_k)w_k $$ のように定めれば,その最小距離は, $$ g(c_k)=\min[g(i,j-1)+d(i,j),g(i-1,j-1)+2d(i,j),g(i-1,j)+d(i,j)] $$ と,再帰的に定めることができます.これは,単純な配列を保持しておけば簡単な動的計画法で解くことができてその計算量は$3NM$程度で済みます.これを用いて単純な単語の語彙の間では,動的計画法を用いて大幅に計算量を抑えて音声認識を取らせる方法がとられていました.
関連して...
DP
ありがたいことにDPまとめコンテストといったものが存在しているので,DPの勉強に解いていこうと思います.
問題K
この手の「最善を尽くした場合」という問題は非常に苦手で,どうやればいいのか手がつかない場合が多いです.
タイトルにDPとついているためDP思考で解こうという気概があったため解けたと思います.
dp[i]を石が残り$i$個の時に先手が勝てるかどうか
の配列とすれば各々の数に対して
$$ dp[i]|=!dp[i-a_j] $$
としていけば$dp[0]$は先手が負けていることを利用して漸化式に持ち込めました.
余談
上の提出では700行ほど書き込んでいますが実際に使ったのはたかだか10行ぐらいなんですよね.
ほとんど他所からもってきたテンプレ(パクリじゃん!)なのです...
Day01::Pythonではじめたい音声認識
音声認識
ことのいきさつ
Twitterで面白そうなタグ #100DaysOfCode というものを見つけました.三日坊主克服のために分野を問わず,進捗をブログにまとめます.
音声処理
")
- 作者: 篠田浩一
- 出版社/メーカー: 講談社
- 発売日: 2017/12/09
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
時系列分野に対する知識が疎いと感じたため読みます.
人体と音
音の高さ(音程)
人間が認識できる音の高さは一般に20Hzから20000Hzと言われており,人間の耳が知覚する音の高さと,実際の周波数との関係は線形ではなく,高音域になるほど音程の変化に対する知覚は小さくなると言われています.
人間の知覚する音の高さを測る尺度としては,メル尺度(mel scale)がよく使われています.これは,1000Hzの音を基準とし,その音に対し$n$倍の高さに知覚される周波数を$n\times 1000$melと表記することで表現されます.例えば,以下のファントの式が周波数とmelの変換によく用いられます. $$ m=\frac{1000}{\log_{10}2}\log_{10}\left(\frac{f}{1000}+1\right) $$
音の大きさ(音圧)
音の物理的強度は音圧と呼ばれ,単位はPa.melとおなじように図るための尺度が存在して,音圧が$p$であるときの音圧レベル(Sopund Pressure Level:SPL)$L_p$は $$ L_p=10\times\log_{10}\frac{p^{2}}{p_0^{2}}=20\times\log_{10}\frac{p}{p_0} $$ と表され,単位はdB SPLです.ただし$p_0=20\times10^{-6}$(Pa)で,人間の耳が聞こえる最小の音圧に対応しています.
音の大きさの感じ取り方も周波数に依存し,人間が同じ音の大きさであると感じる音の音圧レベルと周波数間の関係をプロットした曲線は等ラウドネス曲線と呼ばれます.
 Wikipediaより
Wikipediaより
人間の感じる音の大きさの単位はホン(phon)であり,これは1000Hzの音の音圧レベルをホンと定めています.ホンが等しい音どうしは人間には同じ音の大きさとして聞こえます.例えば1000Hzの20dBの音は80Hzの50Hzの音の大きさと等しく,どちらも20phonの音といえます.
他にも人間の耳には興味深い効果があり,その例としては,
- 大きな音の鳴った前後の音が聞こなくなる経時マスキング効果
- 大きな音の鳴っている時,その周波数前後の音が聞こえなくなる同時マスキング効果
- 対面の相手の音声認識において無意識に口唇の動きで発音を読み取るマガーグ効果
- 騒音の中でも遠くの音を集中して聞こうとすることで聞こえるようになるカクテルパーティ効果
などがあります.
人間の発声の過程は,肺からの息で押し出された声帯の振動から声門波を発生させ,それが声道を通り口唇から放射されるという過程で,声帯の振動周波数は基本周波数と呼ばれます.有声音の場合は声帯は振動するが,無声音の場合には振動しないことが特徴.
声道は,複数の太さの音響管をつないだ構造と近似することができて,その構造故に複数の共鳴周波数があり,その周波数の音が特に強く発声されます.この周波数はフォルマント周波数と呼ばれている.また,フォルマント周波数が複数存在する場合は周波数が低い方から順に,第一フォルマント(F1),第二フォルマント(F2)...などと呼ばれています.また,舌と歯をつけて発生するような子音などは摩擦音として高周波音域の音として観察されます.
音声の持つ特徴のうち特に重要なものは音韻と音素と呼ばれます.音韻はある言語における音声認識の最小単位の音の集合であり,音素は音韻同様音声を構成する集合であるが,こちらは音の物理的に特徴により分類したものである.
世界中の言語の音素を表現するために国際音声字母(IPA:International Phonetic Alphabet)が定められており,下表は日本語の子音のIPAにおける音素分類です.
| 調声器官 | 口唇有声 | 口唇無声 | 歯有声 | 歯無声 | 口蓋有声 | 口蓋無声 | 声帯無声 |
|---|---|---|---|---|---|---|---|
| 摩擦音 | f | z | s | sh | h | ||
| 破擦音 | dz | tz | dʒ | ch | |||
| 破裂音 | b | p | d | t | g | k | |
| 半母音 | w | r | y | ||||
| 鼻音 | m | n |
対して日本語の母音(aiueo)は声道や舌の形を変えることでフォルマント周波数を変えることで生成されます.
また日本語の場合には上表の他に撥音(ん/ɴなど),拗音(ゃゅょ/fya,tjaなど),促音(っ/ːなど)の音素が存在します.
音声の分析
AD変換
音声自体は空気の振動であり,マイクロホンにより電圧の連続的な変化として扱われるため,計算機上で処理を行うためには連続値を離散値へと変換させる必要があります(AD変換).
AD変換の際はまず,アナログ信号を一定間隔で取り出し離散的な時間間隔のデータとします.この操作は標本化(Sampling)と呼ばれています.
さて,一般的なCD等の音源を見ると44.1kHzで標本化されていることが多いが,これは人間の可聴域の上界が20kHz程度であることとサンプリング定理が成り立つことからそう定められています.
サンプリング定理
あるアナログ信号が0HzからW[Hz]までの音で構成されているとしたとき,2W[Hz]以上の周波数で標本化を行えば元の信号を完全に復元できる
標本化したデータに対して,次に音の大きさを離散化させます.この処理は量子化(Quantization)と呼ばれており,多くは後に2進データとして符号化するために2の累乗個に分割されます.こう言った場合には,分割数は量子化ビット数などと呼ばれます.すなわち,8bitの量子化ビット数は標本一つあたり8bitの情報が与えられ,音を256の細かさに分類して表現することができるということを意味します.一般には16bit(6.5万分割),32bit(42億分割)の量子化ビット数が用いられます.
Pythonでの実装例
音声は効果音ラボの落ち着いた女性の「ご静聴ありがとうございました」を利用します.
以下作業ディレクトリ直下に音声を置いたと仮定してまずは依存パッケージとかを入れます.
brew install ffmpeg --with-libvorbis --with-ffplay --with-theora pip install pydub numpy matplotlib
以下Jupyter Notebook上で行います.
wavデータで読み込みたいので変換をします.
import pydub sound = pydub.AudioSegment.from_mp3("info-lady1-goseichouarigatou1.mp3") sound.export("voice.wav", format="wav")
wavデータの読み込みには標準パッケージのwaveを利用します.そして,得られたバイナリデータをNumPyのfrom_buffer関数でNumPy配列にします.
import wave import numpy as np def get_wave_profile(file): wf = wave.open(file, "rb") # モノラルかステレオか nc = wf.getnchannels() # サンプルの大きさ(量子化ビット数) ss = wf.getsampwidth() # サンプリングレート sr = wf.getframerate() # フレーム数 fl = wf.getnframes() # 生データ(バイナリ) data = wf.readframes(fl) # NumPy配列に変換 data = np.frombuffer(data, dtype="int%d" % (8 * ss)) # 正規化 data = data / data.max() print(file) print("\tチャネル数\t\t%s" % nc) print("\t量子化バイト数\t\t%s Byte" % ss) print("\tサンプリングレート\t%s Hz" % sr) print("\tフレーム数\t\t%s" % fl) print("\t秒数\t\t\t%.3f 秒" % (fl / sr)) wf.close() params = { "channels": nc, "width": ss, "rate": sr, "length": fl } return data, params data, params = get_wave_profile("voice.wav") #voice.wav # チャネル数 1 # 量子化バイト数 2 Byte # サンプリングレート 48000 Hz # フレーム数 98816 # 秒数 2.059 秒
波形を表示してみましょう
import matplotlib.pyplot as plt plt.figure(figsize=(11, 5)) plt.plot(range(len(data)), data / data.max()) plt.show()
音声編集ソフトとかでよく見る形ですね.
ついでに,関数から音を生成する関数を作ります.
import struct ''' func: 関数 fs: サンプリング周波数 t: 秒数 name: 出力ファイル名 ''' def create_wave(func, fs, t, name): point = np.arange(0,fs*t) wave = func(point/fs) wave = [int(x * 32767.0) for x in wave] binwave = struct.pack("h" * len(wave), *wave) w = wave.Wave_write(name) # 1:モノラル, 2:16bitの量子化, fs:サンプリング周波数 # バイトでのサンプルサイズ, 圧縮形式(現状PythonではNoneだけがサポートされている) p = (1, 2, fs, len(binwave), 'NONE', 'not compressed') w.setparams(p) w.writeframes(binwave) w.close()
検証のために,単純なSin波と少し複雑な合成Sin波を生成させます.
create_wave(lambda x: np.sin(2 * np.pi * 440 * x), 44100, 0.3, "sin.wav") create_wave( lambda x: 0.2 * np.sin(2 * np.pi * 680 * x) + \ 0.3 * np.sin(2 * np.pi * 440 * x) + \ 0.5 * np.sin(2 * np.pi * 1880 * x), 44100, 0.3, "sins.wav" )
sin.wav(少し長めに出力しています)
sins.wav(少し長めに出力しています)
以下,この音声を用いて音声解析を行います.
高音域強調
高音域になるほど音圧は減衰するため,それを補うため高音域を強調します.一般には1オクターブあたり6dBの強調が行われます.ハイパスフィルタを用いて高音域強調を行う場合を考えると,一次有限インパルス応答をハイパスフィルタとして用いる場合,その式は $$ H(z)=1-\alpha z^{-1}~~(z=e^{j\omega},\omega=2\pi f/f_0) $$ となる($f_0$はサンプリング周波数)ので,その対数ゲインを考えるれば,単位をdBにするため両辺を10倍することで $$ 10\log{|H|^{2}}=10\log(1+\alpha^{2}+2\alpha\cos\omega) $$ となります.6dB/1octの高音強調を達成させるために,$\alpha=0.97$程度の値がハイパスフィルタによく用いられます.
音声フレーム
音声のような時系列信号を解析するためには,一般に一定の時間間隔で特徴量を出力させます.その際の間隔ごとに分析される対象は音声フレームと呼ばれ,間隔自体はフレーム間隔やフレーム周期などと呼ばれます.
フレーム周期は短すぎても計算量が増加し,長すぎても時系列的な特徴が失われてしまうことから,適用な長さに定める必要があります.
人間の一般的な音素の長さがおよそ30ms以上であるというデータをもとに,10ms程度のフレーム間隔として取られることが多いです.
つぎにその間隔で信号をとる場合,単純な矩形窓で取る方法が愚直に考えられますが,それだと両端の不連続な波形が高周波に対してのノイズを生む危険性があります.

そのため,フレームの中心から端にかけて減衰するハミング窓やハニング窓を音声データに対して適用し,高音域のノイズを抑えています.
ハミング窓
$$ W_H(n)=0.54-0.46\cos\left(\frac{2n\pi}{N-1}\right)(n=0,1,2,...,N-1) $$
ハニング窓
$$ W_N(n)=0.5-0.5\cos\left(\frac{2n\pi}{N-1}\right)(n=0,1,2,...,N-1) $$ いずれも,0未満,N以上の時には0を取ります.この二つの窓の違いによる分析性能の変化はさほどないものの一般的にはハミング窓の方が良く用いられます.
窓自体の長さはフレーム長と呼ばれます.フレーム長は一般に20ms-80ms程度の値を取ることが多いです.たとえばフレーム周期10ms,フレーム長50msの場合には0-50ms,10-60ms,20-70msのデータが特徴量として利用されます.
音声の特徴量抽出
ほとんどの音声認識アルゴリズムでは,実際の音声から,音声認識にとって重要な特徴量を抽出する処理が行われます.
短時間フーリエ解析
フーリエ解析のなかで,この音声信号処理のように窓関数をずらしながらフーリエ解析を行うことを短時間フーリエ解析といいます.
信号$x_N[n]$が周期$N$の信号であるとすると,以下の式で表される離散フーリエ変換(DFT)$X_N[k]$が存在します. $$ X_N[k]=\sum_{n=0}^{N-1}x_N[n]e^{-j2\pi nk/N} (0\leq k<N) $$ その逆変換ももちろん存在して $$ x_N[n]=\frac{1}{N}\sum_{k=0}^{N-1}X_N[k]e^{j2\pi nk/N}(0\leq n<N) $$ となる.実際の処理では,高速化させた高速フーリエ変換(FFT)を用いて信号解析を行います.
FFTではビンの数$N$は2のべき乗である必要があり,そのため窓幅とサンプリング周波数を調節して$N$が条件を満たすような値にする必要があります(例えば窓幅32ms,サンプリング周波数16kHz→$N=512$など).高速フーリエ変換を用いることで,計算量を$O(N^{2})$から$O(N\log_2N)$にまで抑えることが可能になります.
$X_N[k]$は複素スペクトルと呼ばれ,そのゲインを用いて,音の大きさを表すパワースペクトルを $$ \begin{align} S_k&=\frac{1}{N}|X_N[k]|^{2}\\ &=\frac{1}{N}\left|\sum_{n=0}^{N-1}x_N[n]e^{-j2\pi nk/N}\right| \end{align} $$ と定義することができます.フォルマント解析などに用いられるスペクトログラムは軸を時間と周波数とし,色をその周波数,時間におけるパワースペクトルの大きさとして表現したものです.人間が音声を認識する際,音声のゲインの情報を専ら使い,位相の情報はそこまで使われないことが知られており,この事実からスペクトログラムに,音声認識で必要な情報が多く含まれているといえます.
Pythonでの実装
NumPyには,高速フーリエ変換を行うための関数が実装されているため,それを利用します.
まずは,単純な離散信号をフーリエ変換する関数を定義します.(この関数は短時間ではなく渡された信号全体に関してフーリエ変換を行います.)
def fft(X, params): # scipyでも以下のフーリエ変換の処理は可能です X = np.fft.fft(X) # 結果Xに対応する周波数を求めます freqs = np.fft.fftfreq(len(X), d=1 / params["rate"]) gain = np.abs(X) # 位相はあまり使いませんが一応返り値として返します. phase = np.angle(X) return freqs, gain, phase
生成した2つのSin波に対して,先ずはfft関数を用いてフーリエ変換してみます.
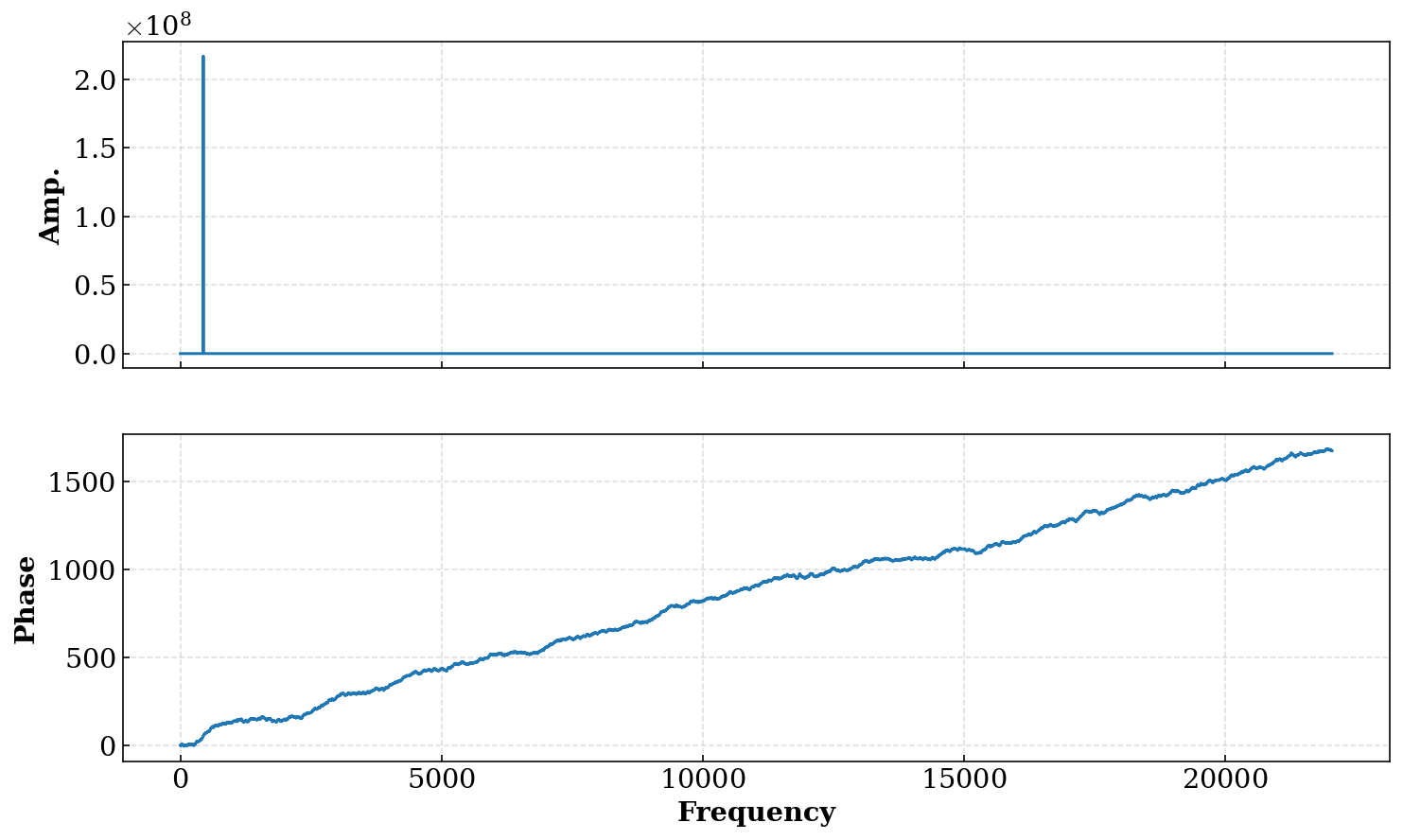
sin_data = get_wave_profile("sin.wav") f, g, p = fft(*sin_data) n = len(f) # FTは共役な複素数が帰るという特性上,正負で鏡像となる(偶対称) # FFTの場合,前半部分が正となるのでその部分だけを利用する f, g, p = f[:n//2], g[:n//2], p[:n//2] fig, axs = plt.subplots(2, 1, figsize=(12, 7), sharex=True) axs[0].plot(f, g) # np.unwrap で位相が -pi ~ piの範囲に限定されなくなる. axs[1].plot(f, np.unwrap(p)) axs[0].set_ylabel("Amp.") axs[1].set_ylabel("Phase") axs[1].set_xlabel("Frequency") plt.show()
これを2つの波に対して適用してみましょう.
sin.wav
sins.wav
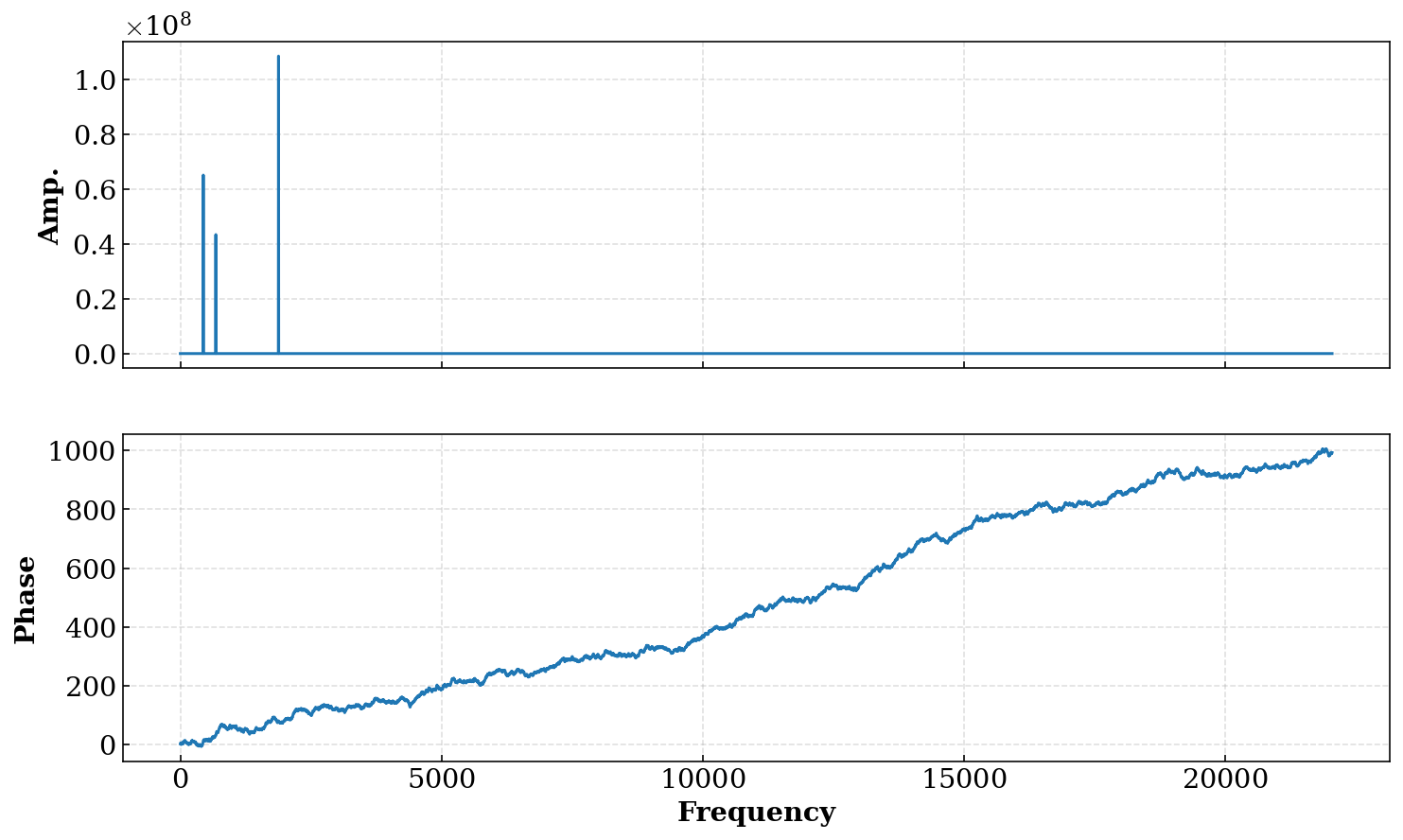
しっかりと,入力周波数部分で振幅が大きな値を示しています.
では,次に短時間フーリエ解析です.NumPyには波形を$N$分割した際に各々のハニング/ハミング関数が幾つになるかを返すnp.hanning(N),np.hamming(N)が用意されています.これを利用して,ハミング窓を利用した短時間フーリエ解析を行います.
# res: フレーム長 # intv : フレーム周期 def stft_hamming(X, params, res=512, intv=32): f = None gs = [] # (フレーム数, フレーム長)の行列 for i in range(len(X) // intv): w = X[i * intv:i * intv + res] # 端は切り捨てる if len(w) != res: continue # ハミング関数.要素ごとにかければ端点の連続性を仮定できる. hamm = np.hamming(len(w)) f, g, _ = fft(w * hamm, params) gs.append(g[:res//2]) return f[:res//2], np.array(gs)
FFT部分は前に定義したfft関数の使い回しで,for文を使った単純な短時間フーリエ解析です.
これを用いて,sin波と音声波形に対して短時間フーリエ解析を行いましょう.
sin_data = get_wave_profile("sin.wav") f, gs = fft_hamming(*sin_data) # 音声に対してSTFTを行う場合はこっち # v_data = get_wave_profile("voice.wav") # f, gs = stft_hamming(*v_data) plt.figure(figsize=(7, 3)) plt.plot(f, 20 * np.log10(gs[10] / gs.max())) plt.xlabel("Frequency [Hz]") plt.ylabel("Power [dB]") plt.show()
こうすることで,ある一つの窓の音圧が表示されます.ただし,ここでのdBは最大音圧に対する相対値であって絶対的な圧力から定義されるdB SPLではありません.
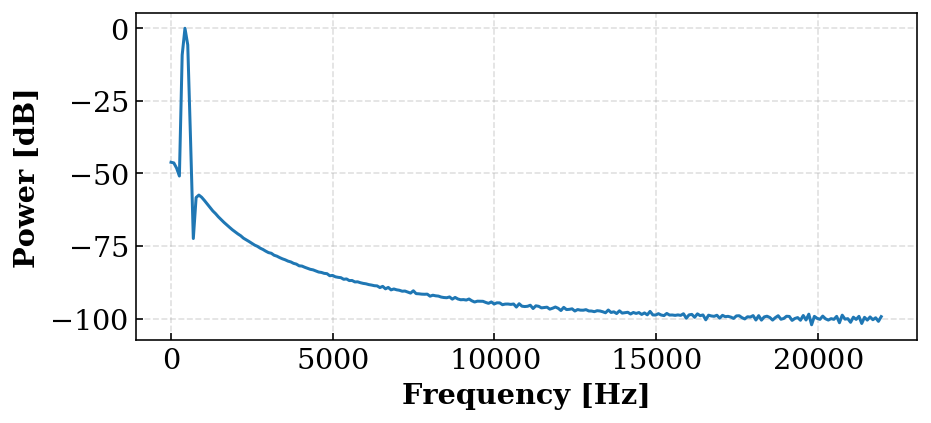
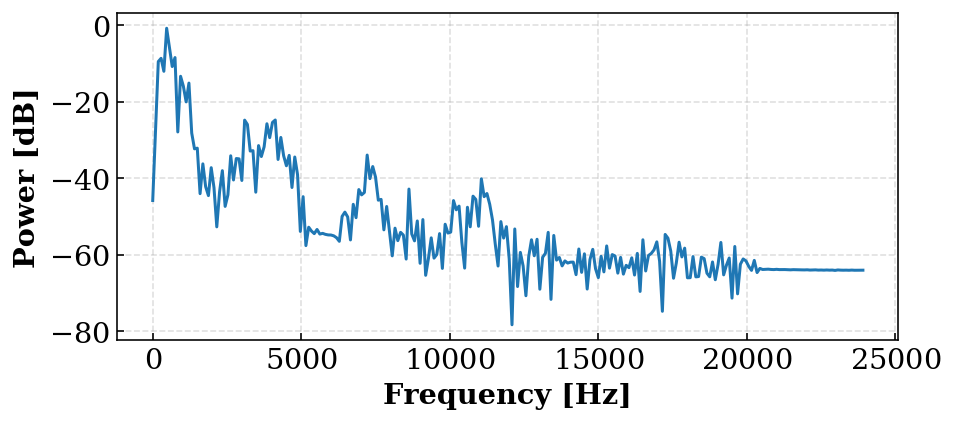
ついでに,アニメーションとして出力します.
def stft_anim_hamming(X, params, res=2048, intv=128): ims = [] fig = plt.figure(figsize=(7, 3)) f, gs = stft_hamming(X, params, res, intv) for g in gs: im = plt.plot(f[:res//2], 20 * np.log10(g[:res//2] / gs.max()), c="b") plt.xlim((0, 10000)) plt.ylim((-100, 10)) plt.xlabel("Freq [Hz]") plt.ylabel("Log Power [dB]") ims.append(im) ani = anim.ArtistAnimation(fig, ims, interval=1000*intv/params["rate"]) ani.save("output_hamm.mp4", writer="ffmpeg") # Jupyter Notebook上でMP4動画を再生できます from IPython.display import Video v_data = get_wave_profile("voice.wav") stft_anim_hamming(*v_data) Video("output_hamm.mp4", width=400, embed=True)
メルフィルタバンク
音声認識の観点からは,単純なビン幅による分割ほど細かな分割は要らず,隣接したスペクトルを纏めて,バリアンスを削減しても,音声認識上は問題は少ないといえます.
分散を小さくさせたいわけですが,高周波ほど人間の耳の分解能が低くなるという特性を反映させるために,周波数をメル尺度に変換して,その上で等間隔となるようにバンドパスフィルタを適用させます.すなわち周波数尺度に直すと高周波ほど幅が広い三角形状のバンドパスフィルタを入力に対して適用させます.

各々のメルフィルタに適用した出力を,用いることで次元数を削減することが可能となります.この出力の対数を次のケプストラム特徴量抽出で用います.
Pythonでの実装
メルフィルタバンクを可視化させる
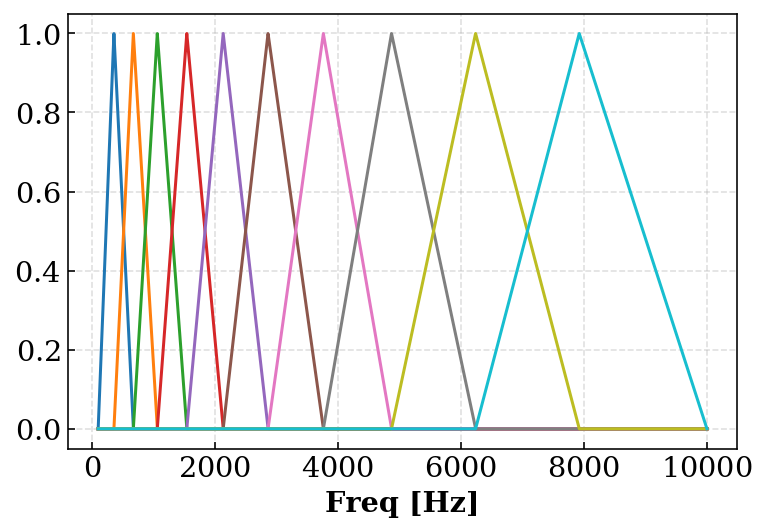
# f_min, f_max: 周波数スケールでの最小値と最大値 # n: 分割数 def mel_filter_show(f_min, f_max, n=20): # 周波数 -> メル変換 mel = lambda x: 1000 * (np.log10(x / 1000 + 1))/ np.log10(2) # メル -> 周波数変換 invmel = lambda y:1000 * (np.power(10, (y * np.log10(2)/ 1000)) - 1) # メルスケールでの最大値と最小値 (m_min, m_max) = mel(f_min), mel(f_max) # メルスケールでの等分割を周波数スケールに直す mp = invmel(np.linspace(m_min, m_max, n + 2)) t = np.arange(f_min, f_max) plt.xlabel("Freq [Hz]") for i in range(1, n + 1): mf1 = lambda x: 1 / (mp[i] - mp[i - 1]) * (x - mp[i - 1]) mf2 = lambda x: 1 / (mp[i + 1] - mp[i]) * (mp[i + 1] - x) # バンドパスフィルタの定義 mf = lambda x: np.maximum(np.minimum(mf1(x), mf2(x)), 1e-80) # 周波数スケールでの可視化 plt.plot(t, mf(t, mp)) plt.show() mel_filter_show(100, 10000, 10)
これで,メルフィルタバンクがどの周波数帯の音に対して強く働くかが可視化されます.
メルフィルタバンクの実装
上記のコードを流用しメルフィルタバンクを適用させる関数を作成します.次に適用する関数のことを考慮し,対数パワースペクトルを出力させます.
# 引数 # f: 周波数の格納されたベクトル # spec: (フレーム数 Nf, フレーム長 fl)のゲインの行列 # f_min, f_max: 周波数スケールでの最小値と最大値 # n: 分割数 # 返り値 # mp: メルフィルタバンクの周波数(shape=(n,)) # mspec: 各々のフレームのメルフィルタバンクにおける対数パワースペクトルの大きさ(shape=(Nf , n)) def mel_filter(f, spec, f_min, f_max, n=20): mel = lambda x: 1000 * (np.log10(x / 1000 + 1))/ np.log10(2) invmel = lambda y:1000 * (np.power(10, (y * np.log10(2)/ 1000)) - 1) (m_min, m_max) = mel(f_min), mel(f_max) mp = invmel(np.linspace(m_min, m_max, n + 2)) t = np.arange(f_min, f_max) mspec = np.zeros((spec.shape[0], n)) for i in range(1, n + 1): mf1 = lambda x: 1 / (mp[i] - mp[i - 1]) * (x - mp[i - 1]) mf2 = lambda x: 1 / (mp[i + 1] - mp[i]) * (mp[i + 1] - x) mf = lambda x: np.maximum(np.minimum(mf1(x), mf2(x)), 1e-80) # i番目のフィルタが周波数に対して作用する度合い coef = mf(f) # @ はドット積(spec.dot(coef))と同義 mspec[:, i - 1] = np.log10(spec @ coef) return mp, mspec
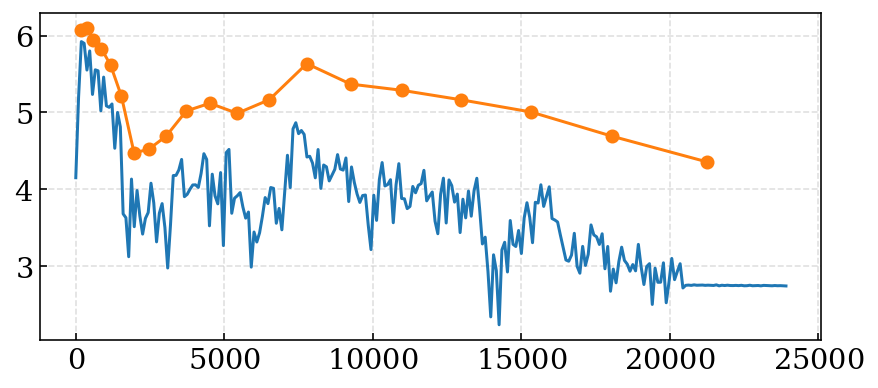
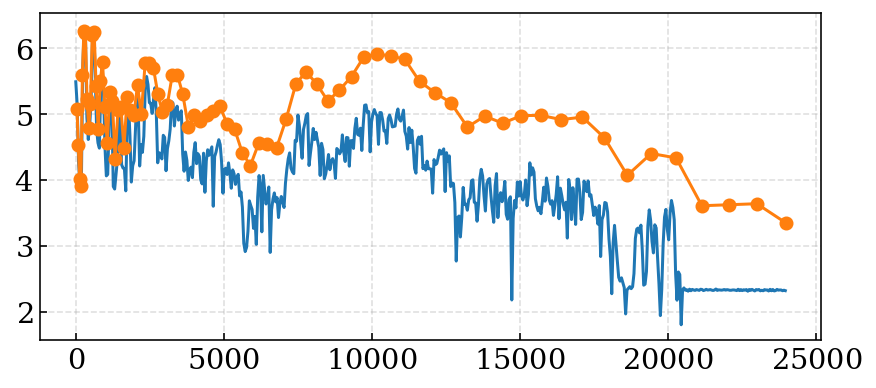
v_data = get_wave_profile("voice.wav") f, gs = fft_hamming(*v_data) mp, ms = mel_filter(f, gs, 0, 25000, 20) # 20 or 80 plt.figure(figsize=(7, 3)) plt.plot(f, np.log10(gs[180])) plt.plot(mp[1:-1], ms[180], marker='o') plt.show()
これで,あるフレームにおけるメルフィルタバンクに変換した値が出力されます.青線で記した単なる対数パワースペクトルに比べると,バリアンスが大幅に減少していることがわかります.
$N$=20の場合
$N$=80の場合
ケプストラム特徴量
これまで生の波形をフーリエ変換し,そのゲインをメル尺度でメルフィルタバンクを用いて次元を減らし,その対数をとりました.音声を微細構造部分と包絡成分(ノイズを取り除いたような滑らかな部分)に分けると,微細な方は声門の波形を,包絡成分は声道のインパルス応答を表していることが知られています.音声認識では主に後者の方が必要となることが多いので,これをメルフィルタバンクの出力から取り出します.
声門波に対するインパルス応答$h$を考える際,声門波によるフィルタリング$v$との畳み込みにより,観測信号$y$が記述できます.すなわち,畳み込み和 $$ y[n]=\sum_{m=-\infty}^{\infty}v[m]h[n-m]=v[n]*h[n] $$ で観測信号が記述されます.畳み込み和のフーリエ変換は積に直すことができて $$ Y[k]=V[k]H[k] $$ 今回のメルフィルタバンクの出力であるパワースペクトルは対数を取っているので, $$ \log Y[k]=\log V[k]+\log H[k] $$ となり,観測信号が包絡部分$H$と声門のフィルタ部分$V$に分けることができます.
人間の聴覚特性は,パワースペクトルの対数と対応していると言われています.したがってここで,パワースペクトル$S[k]$の対数を考えると, $$ \log S[k]=\log|Y[k]|^{2}=2\log|V[k]|+2\log|H[k]| $$ となります.では,この対数パワースペクトルに逆離散コサイン変換を適用します.パワースペクトルの対称性を利用すると, $$ \begin{align} c[n]&=\frac{1}{N}\sum_{k=0}^{N-1}\log S_k\exp\left(j\frac{2\pi kn}{N}\right)\\ &=\frac{1}{N}\sum_{k=0}^{N-1}\log S_k\cos\left(\frac{2\pi kn}{N}\right)\\ &=\frac{1}{N}\sum_{k=0}^{N-1}\log V_k\cos\left(\frac{2\pi kn}{N}\right)+\frac{1}{N}\sum_{k=0}^{N-1}\log H_k\cos\left(\frac{2\pi kn}{N}\right) \end{align} $$ と,変換できます.この$c$は,ケプストラム(cepstrum:spectrumのアナグラム)と呼ばれます.ケプストラムの単位はケフレンシー(quefrency:frequencyのアナグラム)です.
ケプストラム-ケフレンシー図を書くと包絡成分$H_k$が低いケフレンシー部分に,声門波成分$V_k$が高ケフレンシー部分に現れます.そのため,低ケフレンシー部分を取り出すローパスリフタリング(liftering:filteringのアナグラム)をして,低ケフレンシー部分を取り出します.一般にはケフレンシーの低い方から10-15個の値が用いられます.
特にメルフィルタバンクの対数スペクトラルパワーのケプストラムはメルケプストラムや,メル周波ケプストラム係数(MFCC:Mel Frequency Cepstral Coefficient)と呼ばれます.
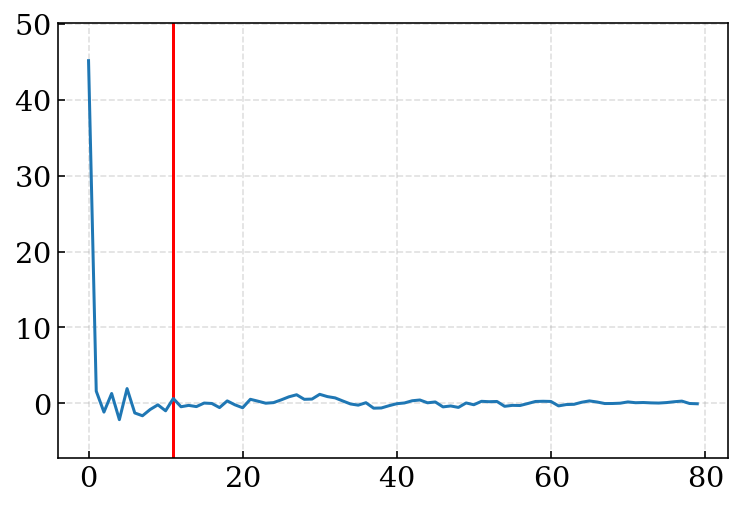
from scipy.fftpack.realtransforms import dct def get_cepstrum(mp, mspec): ceps = dct(ms, type=2, norm="ortho", axis=1) return ceps v_data = get_wave_profile("voice.wav") f, gs = stft_hamming(*v_data, res=1024, intv=64) mel_data = mel_filter(f, gs, 0, 25000, 80) ceps = get_cepstrum(*mel_data) cep = ceps[180] plt.plot(range(len(cep)), cep) plt.ylim((y.min() - 5, y.max() + 5)) # 低い方から12個までを特徴量として利用します thres = 12 plt.vlines(thres - 1, -100, 100, color="r") print(cep[:thres]) # [45.15669001 1.60017792 -1.15822766 1.2903854 -2.15728379 1.93866199 # -1.27352706 -1.64276638 -0.81609222 -0.20153028 -0.99046816 0.63004835]
これで,ようやくメルケプストラムが抽出されます.お疲れ様でした...
差分特徴量
音声の動的な特徴を捉えることも音声認識には有効な手段であることが知られています.そのためには,2通りの方法が考えられます.
一方は,隠れマルコフモデル(HMM)や超短期記憶(LSTM)などといった時系列のデータの特徴を学習するモデルを使う手段で,もう一方は,フレーム間の特徴量の推移を新たな特徴量とする手段です.
具体的には隣接フレーム間で,ケプストラムの差分を取りそれを新たな特徴量とさせます.これはデルタケプストラムや,差分ケプストラムなどと呼ばれています. $$ \Delta c_n(t)=\frac{\sum_{k=-K}^{K}kc_n(t+k)}{\sum_{k=-K}^{K}k^{2}} $$ 一般には$K=2\sim5$の値を用います.また差分の差分を新たに特徴量として加える場合があります.
まとめ
音声解析では,生の信号で扱われることは少なく,様々な分析を経てなるべく特徴を保持したまま次元削減して利用しています.具体的には
- AD変換: マイクでの録音の際に離散化されます.16kHz前後が多い.
- 高域強調:パワーの弱い高音域を強調します.
- STFT: 信号に対し,窓関数をずらしてフーリエ解析を行います.
- メルフィルタバンク: 次元を削減してバリアンスを抑えます.
- ケプストラム変換: 信号の包絡部分をケプストラム領域に逆離散コサイン変換をして抽出します.
- 差分特徴量: 時系列変化の特徴を追加で考慮します.
という過程を経て利用されます.
誤植等があればご報告お願いいたします.
参考資料
- メル周波数ケプストラム係数(MFCC)- 人工知能に関する断創録
- 離散コサイン変換 - Wikipedia
- ブログ記事中に音声や音楽ファイルプレイヤーを埋め込む方法
- FFT to spectrum in decibel - Stack Exchange
- 音楽と機械学習 前処理編 MFCC ~ メル周波数ケプストラム係数 - Qiita
- メル周波数ケプストラム係数(MFCC) - 人工知能に関する断創録
- 高速フーリエ変換(FFT) - 人工知能に関する断創録
wave--- WAVファイルの読み書き— Python 3.7.3 ドキュメント- The mel frequency scale and coefficients
余談
100日こんな調子は絶対無理なので2日目以降はボチボチやります.
技術書典に書きたい本と近況::2/13
お残し的な演習科目が春休みに食い込んで色々忙しかったのですが,ここ数日ひと段落しました.しかしながらもう一週間後には自分の抱えたタスクでまた忙殺されそうになるので遺言がてら書いています.
技術書典6に当選した(2/5)
4/15に池袋サンシャインシティにて開かれる技術書典6に私の属しているサークルKCSがめでたく当選しました.
#技術書典6 では部員が共同して作成した技術の闇鍋合同誌とこれまでのイベントで配ってきた既刊を頒布します!
— KCS@日曜日東ト59b (@kcs1959) February 10, 2019
また、秘密裏に進んでいるプロジェクトもあったりするという噂も・・・
当日は是非お立ち寄りください! pic.twitter.com/cO8P1bj9gd
ここのツイートにも書いた通り,1月頭から秘密裏に何か執筆している張本人です.現在ページ数が100,文字数が85000を超えてそれなりに本っぽい体裁になってきました.

現在(2/13 23:22)での目次の様子です.間に合うのかこれ
というわけで当日はよろしくお願いします.紙で出したいけど印刷費がマジで馬鹿にならないから悩み中です.頒布価格も1800円前後を予定していますが,相場としてどうなのでしょうか.わからん.
電子書籍版は実質無限なのでかなり持っていきます.売れたら2080ti組みたいです.野望.
AtCoderで緑色になりました(2/9)
緑になった!わーい https://t.co/aqDVY3d5jx pic.twitter.com/nj3a3dXwlz
— 🌓TsunaKan🌓 (@fujifog) February 9, 2019
クソ雑魚アルゴリズマーでも頑張れば緑にはなれました.今年中には青色になりたい.ホンマか?
Pythonで学ぶ強化学習を買いました(1/19)
")
機械学習スタートアップシリーズ Pythonで学ぶ強化学習 入門から実践まで (KS情報科学専門書)
- 作者: 久保隆宏
- 出版社/メーカー: 講談社
- 発売日: 2019/01/17
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
強化学習何もわからんマンなので強い人(例えば@syu*****14など)教えて下ちゃい
iPhone Xs MAXを買いました(2/11)
なんだかんだ人生初のリンゴです.一回買うとiPadもApple PencilもApple WatchもMacbook Proも買いたくなるので沼みを感じます.
技術書典,お願いします(念入り)
情報科学若手の会冬の陣に行ってきました::1/20
とある同期がSlackで宣伝していたのを思い出し急遽参加しました.
様々な分野の知見が聞けて良かったです.懇親会があったのですがABCに出たかったので帰りました.
夏の本陣にもぜひ参加したいのですがB4で行けるのかなあ.厳しそう...
以下メモです.すべてが適当なメモです.
1. @arayaryoma
- フロントエンドを頑張りたくない時どうすれば良いか?
フロントエンドの疑問
HTML.JS,CSS生じゃダメ?
条件を満たせるならば良い. 「IEサポート要らん」や「JS使わん」という場合は良い
React?Vue?Angular?jQueryは?
jQueryは生きているぞ. DOM API操作の不自由度が下がってきた. Virtual DOM等の登場によりDOMの直接操作の必要がいらなくなった.
Webpackの代案
percel: Webpackの糞めんどくさいコンフィグを解消してくれる
brouserify: +glup, +gruntで使う
rollup.js: ESModuleしかデフォでは使えない
どうしてめんどくさいの?
5割IEのせい!
npmはどういうときに必要?
SPAはパッケージマネジャ
2. @K_atc
シンボリック実行の活用例
- テスト
- 脆弱性解析
シンボリック実行の種類
FSEとSBEの二つがある
SBEはプログラムを逆順に実行する.そんなことできるの?
→最弱事前条件を満たせば可能!
最弱事前条件の計算方法
- まず,プログラムをGCLに変換
- それぞれの規則に対して最弱事前条件を導出
→WP向けのエンジンをPythonで実装した
.pyをastモジュールでASTに変換にできて便利
3. @porisuteru
Deep Learning+異常検知(Anomaly Detection)(会社ChillStackのCEO)
異常検知
- ホテリング法
- ナイーブベイズ
- 近傍法
- OC-SVM
- 密度推定
等があるが,昨今ではDEEEEEEEEEPLEARNING,とくにGANを使ったアルゴリズムがある.
GAN・・・$z$の分布$p$に対して$G(z)\approx x$に対して検定を行って閾値外にあるとき,異常であると認識させる
$c.f.$ AnoGAN
- GANに学習をさせる
- $G(z)\approx x$となるような$z$を探索する.
めっちゃ時間かかる!
- そこでEfficient GANという双方向構造を用いたモデルが提案された $G^{-1}(x)$もモデル化しちゃえばいいじゃん!というスタンス.
- 異常検知!
4. @Knium_
Cコンパイラを自作したい!
字句解析→構文解析→意味解析→コード生成といった順序に行われる.
方針
いきなり完璧を目指さずにインクリメントに制作する.
Compiler Explorer(https://godbolt.org/)というなかなか便利なサイトがある.
入門書: https://www.sigbus.info/compilerbook/
BNF読むの楽しいぞ!
5. @kuro_m88
Webデバイストラッキングのはなし
- Cookie:cookie: -> Cookie Sync
- IP Address …<->Grobal IP <-> NAT <-> Device ユーザの一意特定が少し面倒.最近ではWebRTCというのがあるらしい
- HSTS Super Cookie httpで訪問してきたクライアントにhttpsにリダイレクトさせるようにするHSTSのアルゴリズムを使った手法.
- TCP Timestamp TCP Timestampの周波数からデバイスのuptimeがありそこから同定.
- SSL Session Ticket SSL :handshake:を高速化させるためのTicketにより同定.
- IPv6 1IP=:iphone:の時代に...?
6. @mkt_kwn
スマートシティ
都市内にIoTデバイス(ゴミ収集車など)を埋めこませて都市情報をセンシングしてフィードバックを行う
昨今ではRaspberry PIやJetsonを載せて組み込み内で認識→学習まで行えちゃう.
IoTとセキュリティ:エッジ側で処理をさせたい!
Node-RED:https://nodered.org これをどうにかして分散処理に応用できないか?
→Distributed Node-REDというものを開発.
→→Node-RED上でDEEEEEEEEEPLEARNINGしちゃえば?
→→TensorflowノードをNode-RED上で使えるようにさせた
LT-1 @ngmt83
エンジニアの生存戦略について
生存していくためには,エンジニアリングスキル以外にも,プレゼンや業務スキルの取得が必要だ.
ビジネス書のすすめ
→エンジニアリング以外での生き残り方を学ぶことで,コミュニケーションやマネジメントのスキルが身につく
LT-2 @hnmx4
頑張りの可視化
→WindowのLogを記録しよう
Mackerelがあるが秘匿情報を流すのがまずい!
→macOS用に自作
2018年を今頃振り返ろう::1/9
書きそびれていたので七草がゆを食べながら昨年あったことに思いを馳せました.(怠惰により七草がゆより後に投稿されていることに気付いた)
1月
初めてのJSとすごいHを読んでいる(語弊あんど語弊) pic.twitter.com/y2v3Lb3JKL
— 🌒TsunaKan🌒 (@fujifog) 2018年1月7日
三重振り子ができた(合ってるかは知らない) pic.twitter.com/fjzoWvtTSD
— 🌒TsunaKan🌒 (@fujifog) 2018年1月19日
JSと初めてのスゴイHをしながら三重振り子で遊びました.
2月
わーい pic.twitter.com/6lhANAdznx
— 🌒TsunaKan🌒 (@fujifog) 2018年2月7日
やっぱ見た目って大事ですね pic.twitter.com/g4CWDchq6m
— 🌒TsunaKan🌒 (@fujifog) 2018年2月17日
フォロワーのTLから形態素解析→マルコフ連鎖したツイート:
— 🌒TsunaKan🌒 (@fujifog) 2018年2月26日
数年前、バシバシ取り締まれ!」じゃなくて仕事やべーんだろ」もよろしくお願いいたしましただけした
DXなライブラリでマルコフ連鎖をしてスッタンで和了りました.
3月
レンダリング中は暇なんですよ pic.twitter.com/ue2s4M3pX7
— 🌒TsunaKan🌒 (@fujifog) 2018年3月30日
レンダリング中暇なのでばあちゃる日記をつけ始めました.
4月
Fooooooooooooo!!!!!!!!!! pic.twitter.com/OVWEk8QefK
— 🌒TsunaKan🌒 (@fujifog) 2018年4月16日
フォロー中のTLから形態素解析→マルコフ連鎖したツイート:
— 🌒TsunaKan🌒 (@fujifog) 2018年4月16日
レポンヨヨはぁぉ〜
手書きレポートに蹂躙されながらCourseraのコースを完了しました.
5月
月:徹夜で疲れる
— 🌒TsunaKan🌒 (@fujifog) 2018年5月20日
火:実験で疲れる
水:生活習慣の乱れで疲れる
木:慢性的なストレスで疲れる
金:フルコマで疲れる
土:レポートで疲れる
日:レポートで疲れる
というわけで僕は21歳になりました!!!!!!
— 🌒TsunaKan🌒 (@fujifog) 2018年5月29日
祝って!!!!!
手書きレポートに蹂躙されて21歳になりました.
6月
バイト採用された
— 🌒TsunaKan🌒 (@fujifog) 2018年6月13日
とくによくできてそうなやつ
— 🌒TsunaKan🌒 (@fujifog) 2018年6月22日
上,上,上,左上 pic.twitter.com/iJAzLOS5gG
美少女錬成して人工知能系のバイトに行き始めました.
7月
3.00からにした
— 🌒TsunaKan🌒 (@fujifog) 2018年7月16日
窓がきちんと出ててすごい pic.twitter.com/6pRdh7eg3J
Spectral Normalization GANをいつものデータセットで実装してみた.
— 🌒TsunaKan🌒 (@fujifog) 2018年7月23日
ソースコードはほとんど写経した.
右かわいい!(左上から目をそらしつつ) pic.twitter.com/uBlzLQQy8v
非線形のロジスティックマップと$L_2$ノルムで人生終了してました.
8月
にゃんこ pic.twitter.com/GXbTZCZBMz
— 🌒TsunaKan🌒 (@fujifog) 2018年8月12日
混合ガウス分布のEMアルゴリズム pic.twitter.com/aaw3AOMK17
— 🌒TsunaKan🌒 (@fujifog) 2018年8月24日
変分下界を追加した pic.twitter.com/BevHDvpLhP
— 🌒TsunaKan🌒 (@fujifog) 2018年9月1日
にゃんこ with PRML
9月
何もなかった...
10月
BigGANについて書きました.計算資源がなくてつらいと思いました. #はてなブログ
— 🌒TsunaKan🌒 (@fujifog) 2018年10月6日
Large Scale GAN Training for High Fidelity Natural Image Synthesis(BigGA…https://t.co/0HyPIjTtEC
— 🌒TsunaKan🌒 (@fujifog) 2018年10月13日
— 🌒TsunaKan🌒 (@fujifog) 2018年10月19日
BigGANの論文を読んだら,無謀にもWebアプリに挑戦して糞雑魚数字分類アプリと適当インスタ映え診断機ができた.
11月
強い(確信)
— supercell (@undermountainaf) 2018年11月20日
バネちゃんやったらぴったりでしたw pic.twitter.com/yauWZvIhrA
適当Webアプリを作ったら「火焔瓶投げる系サイコなVtuber」が「ほのお・エスパー」に分類されてシンギュラリティを感じた!
12月
はてなブログに投稿しました
— 🌒TsunaKan🌒 (@fujifog) 2018年12月29日
統計的学習の基礎 2章のメモ - 進捗だめです https://t.co/z7Ko6TC1nj #はてなブログ
いいかんじ pic.twitter.com/18dj5Z3m5U
— 🌒TsunaKan🌒 (@fujifog) 2018年12月23日
VueとFirebaseと統計やってたら2019年になってたよ.
2018年は個人的に割と💪圧倒的成長💪できた一年だったと思う
2019年もこの調子で🐗猪🐗突🐗猛🐗進🐗していきたいよね.
統計的学習の基礎 2章のメモ
統計的学習の基礎を買ったのでそのメモを公開します.どこか,変な所がございましたらコメントをお願いいたします!

- 作者: Trevor Hastie,Robert Tibshirani,Jerome Friedman,杉山将,井手剛,神嶌敏弘,栗田多喜夫,前田英作,井尻善久,岩田具治,金森敬文,兼村厚範,烏山昌幸,河原吉伸,木村昭悟,小西嘉典,酒井智弥,鈴木大慈,竹内一郎,玉木徹,出口大輔,冨岡亮太,波部斉,前田新一,持橋大地,山田誠
- 出版社/メーカー: 共立出版
- 発売日: 2014/06/25
- メディア: 単行本
- この商品を含むブログ (6件) を見る
2.3. 最小二乗法と最近傍法
最小二乗法
統計的にデータを解析したい際に,昔からよく取られる有用な方法の一つに,線形モデルによる近似がある.線形モデルとは入力$\boldsymbol{x}^ T=(x_1,x_2,...,x_p)$に対して出力$y\in \mathbb{R}$を $$ \hat{y}=\hat\beta_0+\sum_{j=1}^ {p}\hat\beta_jx_j $$ のように線形和で予測する方法である.$x_0=1$とすることでバイアス項を一つにまとめることができて $$ \hat y=\boldsymbol{x}^ T\hat{\boldsymbol{\beta}} $$ のようにベクトル表記で簡潔に表すことが可能である.ただし上の$\boldsymbol{x}^ T,\hat{\boldsymbol{\beta}}$は$p+1$次元である.
最小二乗法は,このアプローチに対して,各点の残差二乗和(RSS)を最小化するように適切な$\boldsymbol{\beta}$を学習する手法である.
$$ \text{RSS}(\boldsymbol{\beta})=\sum_{i=1}^ {N}(\hat{y}_i-\boldsymbol{x}_i^ T\boldsymbol{\beta})^ {2} $$
これは$X\in \mathbb{R}^ {N\times(p+1)},\boldsymbol{\beta}\in \mathbb{R}^ {p+1},\boldsymbol{y}\in \mathbb{R}^ {N}$のように行列を用いて表記すると, $$ \text{RSS}(\boldsymbol{\beta})=(\boldsymbol{y}-X\boldsymbol{\beta})^ T(\boldsymbol{y}-X\boldsymbol{\beta}) $$ のようにも表記することが可能である.
$\boldsymbol{\beta}$で偏微分すると
$$ \newcommand{\v}[1]{\boldsymbol{#1}} $$
$$ \begin{eqnarray} \frac{\partial}{\partial \boldsymbol{\beta}} \text{RSS}(\boldsymbol{\beta})&=&\frac{\partial}{\partial \boldsymbol{\beta}}(\boldsymbol{y}^ T\boldsymbol{y}-\boldsymbol{\beta}^ TX^ T\boldsymbol{y}-\boldsymbol{y}^ TX\boldsymbol{\beta}+\boldsymbol{\beta}^ TX^ TX\boldsymbol{\beta})\\ &=&-X^ T\boldsymbol{y}-\boldsymbol{y}^ TX+(X^ TX+(XX^ T)^ T)\boldsymbol{\beta}\\ &=&-2X^ T(\boldsymbol{y}-X\boldsymbol{\beta}) \end{eqnarray} $$
となり,この式=0とときの方程式の解$\hat{\boldsymbol{\beta}}$で極値をとることが分かる.この方程式は正規方程式と呼ばれる.この解は$X^ TX$が特異でない限り,解くことが可能で $$ \hat{\boldsymbol{\beta}}=(X^ TX)^ {-1}X^ T\boldsymbol{y} $$ という解になる.
実装例
import numpy as np import matplotlib.pyplot as plt class LeastSquare(): def fit(self, X, y): self.X = np.hstack([np.ones((X.shape[0],1)), X]) self.w = np.linalg.inv(self.X.T.dot(self.X)).dot(self.X.T).dot(y) def predict(self, X): return X.dot(self.w) # トイデータの作成 X = np.concatenate([np.random.normal((-2, 2), (4, 4), (60, 2)), np.random.normal((2, -1), (4, 4), (60, 2))]) y = (np.arange(0, 120)//60).astype(np.int32) model = LeastSquare() model.fit(X, y) w = model.w f = lambda x: (w[0] + w[1] * x - 0.5) / -w[2] plt.scatter(X[:, 0], X[:, 1], c=y) t = np.linspace(-10, 10) plt.plot(t, f(t))

最近傍法
k最近傍法は$\hat y$を予測する際,入力に対する最も近い訓練データ$k$点の値を利用する.アルゴリズムは単純で,入力$x$に最も近い点から$k$個の点$N_k(x)$を選んでその訓練ラベルの平均を算出して予測出力とする. $$ \hat{y}=\frac{1}{k}\sum_{x_i\in N_k(x)}y_i $$ 01分類問題であればこの値が0.5より大きいか小さいかで分類を行う.
むろん,kが1に近づくにつれて誤分類が少なくなるため,訓練誤差は少なくなるが,汎化性能が低下してしまう.
また,k最近傍法は,一見パラメータ数が$k$個のみのように思えるが,有効パラメータ数と呼ばれるものがk最近傍法の場合,$N/k$となることが知られている.すなわち,$k$が増加するにしたがって有効パラメータ数は減少する.
実装例
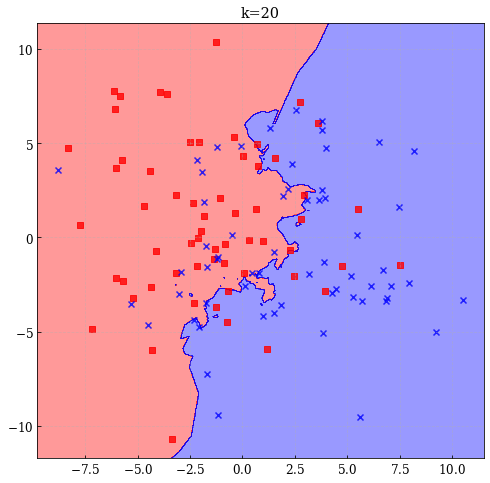
class KNN(): def __init__(self, k=3): self.k = k def fit(self, X, y): self.X = X self.y = y def predict(self, X): dists = np.array([self._distance(p, X) for p in self.X]) nearpoints = dists.argsort(axis=0)[:self.k, :] return self.y[nearpoints].mean(axis=0) # ユークリッド距離 def _distance(self, x0, x1): return ((x0 - x1)**2).sum(axis=1) k = 20 model = KNN(k=k) model.fit(X, y) plot_decision_regions(X, y, model, title='k=%d' % k)
(plot_decision_regionsは本質ではないのでここに格納してあります)
- k=20の場合
- k=1の場合
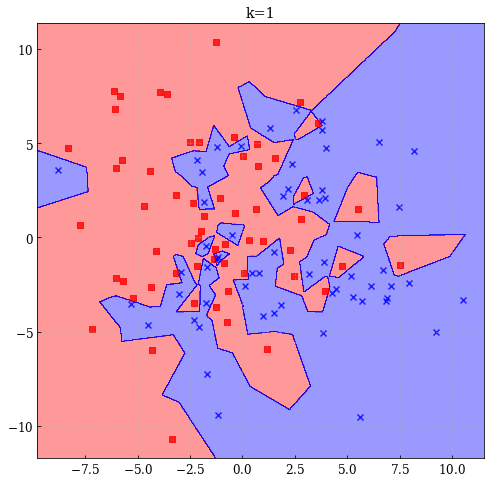
最小二乗法は決定境界が滑らかであり,当てはめの結果も安定しているが,線形であるという仮定に大きく依存している.一方で最近傍法は生成過程に対して厳密な仮定を置いていないため任意のデータに対してうまく適合するように思える.しかし,決定境界が曲がりくねった複雑なものになりやすいものとなるという問題点もある.
統計学の用語では前者の最小二乗法のようなモデルはバイアスが大きいモデルといわれ,最近傍法のようなモデルはバリアンス(分散)が大きいモデルであると呼ばれる.
2.4. 統計的決定理論
入力確率変数$X\in \mathbb{R}^ p$,出力確率変数$Y\in\mathbb{R}$が,同時確率分布$P(X,Y)$に従うような場合を考える.このようなときに出力を予測する関数$f$を予測させるためにはどうすればよいか.
理論的に考察するため,予測に関する罰則$L$を定義することは有用で.二乗誤差損失 $$ L(Y,f(X))=(Y-f(X))^ 2 $$ はその中でもよく用いられる.この二乗誤差損失を用いると,関数$f$はどう定義されるのかを考察する.
定量的に扱うため,この二乗誤差損失の期待値である期待二乗予測誤差(EPE)を考えよう. $$ \begin{eqnarray} \text{EPE}(f)&=&\mathbb{E}\left[(Y-f(X))^ 2\right]\\ &=&\int[y-f(x)]^ 2P(dx, dy)\\ &=&\iint[y-f(x)]^ 2P(x,y)dxdy\\ &=&\int\left(\int[y-f(x)]^ 2P(Y=y|X=x)dy\right)P(x)dx\\ &=&\int\mathbb{E}_{Y|X}[(y-f(x))^ 2|X=x]P(X=x)dx\\ &=&\mathbb{E}_X\mathbb{E}_{Y|X}[(y-f(x))^ 2|X] \end{eqnarray} $$ から,それぞれの入力$x$に対して最小化を行えばよく, $$ f(x)=\arg\min_c\mathbb{E}_{Y|X}[(y-c)^ 2|X=x] $$ となる.よって $$ \begin{eqnarray} \arg\min_c\mathbb{E}_{Y|X}[(y-c)^ 2|X=x]\Rightarrow \frac{\partial}{\partial f}\int[y-f]^ 2P(Y=y|X=x)dy&=&0\\ \int\frac{\partial}{\partial f}[y-f]^ 2P(Y=y|X=x)dy&=&0\\ -2\int yP(Y=y|X=x)dy+2f\int P(Y=y|X=x)dy&=&0\\ -\mathbb{E}_Y[Y|X=x]+f&=&0\\ f(x)&=&\mathbb{E}_Y[Y|X=x] \end{eqnarray} $$ となる.最後の関数は回帰関数と呼ばれる.
すなわち,二乗誤差を考慮した状況下では$X=x$のもとでの最良の予測は条件付き期待値に等しいといえる.
最近傍法は,訓練データからこの期待値を $$ \hat{f}(x)=\text{Ave}(y_i|x_i\in N_k(x)) $$ と期待値を標本平均に,その点直接ではなく近傍領域へと緩和して,直接近似している.
$k,N\rightarrow\infty,k/N\rightarrow0$のもとでは実際$\hat{f}(x)\rightarrow \mathbb{E}_Y[Y|X=x]$となることが証明されている.しかしながら,多くのデータを集めることは困難であり,線形性等の構造上の仮定がデータに対して満たしていればそのモデルの方が安定した推定が可能であることがわかる.
また,近傍領域を考慮するk最近傍法は次元数$p$が大きくなるにつれて高次元特有の不利益をうけてしまうことが知られている.
最小二乗線形回帰の場合は$f(\boldsymbol{x})\approx \boldsymbol{x}^ T\boldsymbol{\beta}$と近似できると仮定することで,上の期待二乗予測誤差の式に代入しそれを最小化する解$\boldsymbol{\beta}$を求めるべく偏微分することで $$ \begin{eqnarray} \frac{\partial}{\partial \boldsymbol{\beta}}\text{EPE}(f)=\frac{\partial}{\partial \boldsymbol{\beta}}\iint[y-\boldsymbol{x}^ T\boldsymbol{\beta}]^ 2P(x,y)dxdy&=&0\\ \iint-2\boldsymbol{x}(y-\boldsymbol{x}^ T\boldsymbol{\beta})P(x,y)dxdy&=&0\\ \iint(y\boldsymbol{x}-\boldsymbol{x}\boldsymbol{x}^ T\boldsymbol{\beta})P(x,y)dxdy&=&0\\ \mathbb{E}[XY]-\mathbb{E}[XX^ T]\boldsymbol{\beta}&=&0\\ \boldsymbol{\beta}&=&(\mathbb{E}[XX^ T])^ {-1}\mathbb{E}[XY] \end{eqnarray} $$ 以上をまとめると最小二乗法は線形関数でうまく回帰関数を近似できると仮定し,k最近傍法は局所的な定数関数でうまく近似できると仮定しているという点が異なるといえる.
また,ここまで$L_2$誤差損失のみを考えてきたがこれを$L_1$誤差損失へと置き換えた場合,最良を示す回帰関数は何になるであろうか.これは,条件付き中央値へとなることが知られている.
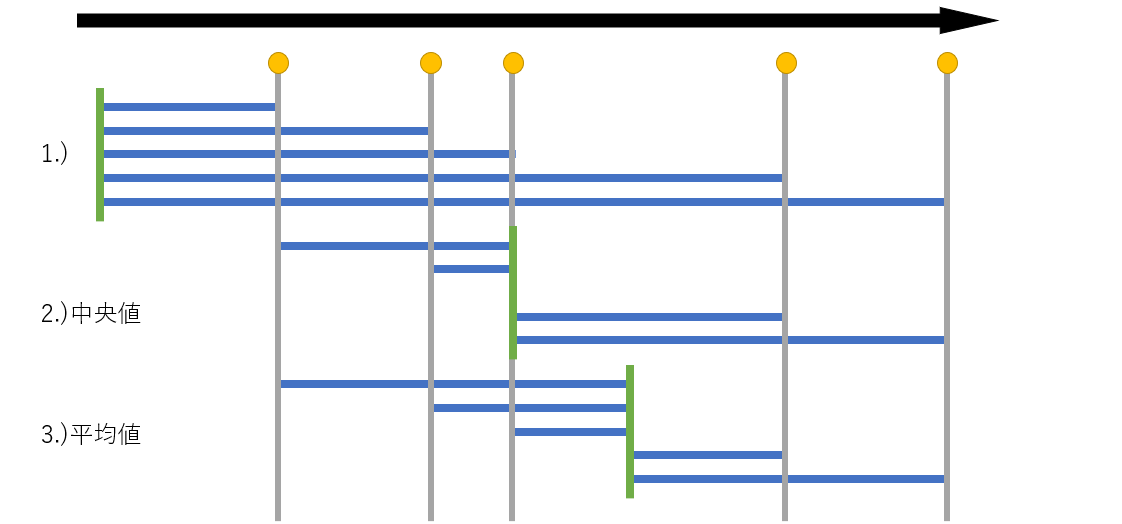
中央値は左に存在する点の数と右に存在する点の数が等しくなるような点が中央値であるので,かりに上の図の緑線が中央値より右にずれた場合,中央値とそれより左にある点は右方向に余計な損失が生まれてしまう.このことから $$ \hat{f}(x)=\text{median}(Y|X=x) $$ が回帰関数となる.
離散の場合はカテゴリ型の変数を$G$として,そのカテゴリが集合$\mathcal{G}$のうちのいずれかの値を取ると仮定する.カテゴリ数を$K$とする($K=\#\mathcal{G}=\text{card}(\mathcal G)$)この時の損失関数は,対角成分が0でそれ以外が非負の$K\times K$行列$L$によって与えられる.損失としては多くは0,1の損失が取られる($L\in\{0,1\}^ {K\times K},\text{tr}~L=\boldsymbol{0}$).
このとき,期待予測誤差は $$ \text{EPE}=\mathbb{E}[L(G,\hat{G}(X))] $$ として与えられる.ただし,$L(k,l)$はクラス$\mathcal G_k$を誤って$\mathcal G_l$へと分類した時の罰則である.
これは $$ \text{EPE}=\mathbb{E}_X\sum_{k=1}^ {K}L(\mathcal{G}_k,\hat{G}(X))P(\mathcal G_k|X) $$ とあらわすことができ,連続の場合と同様に $$ \hat{G}(x)=\arg\min_{g\in\mathcal G}\sum_{k=1}^ {K}L(\mathcal G_k,g)P(\mathcal G_k|X=x) $$ と変形できさらに01損失の場合は $$ \hat{G}(x)=\arg\min_{g\in \mathcal G}[1-P(g|X=x)] $$ と単純化できる.
この解は,条件付き確率を用いて最も確からしいクラスへと分類する妥当なものとなっており,そのようなモデルをベイズ分類器などと呼ばれている.
2.5. 高次元での局所的手法
$p$次元単位超立方体に対して,データ点が一様に分布していると考える.ある頂点からの近傍を単位超立方体内の部分超立方体と定義し,$p$を変化させたときの部分超立方体の一辺の長さと体積の割合を考えよう.
近傍データ数が全データのうち,割合$r$だけ含んでいるとしたときの近傍の部分超立方体の長さの期待値は$e_p(r)=r^ {1/p}$となるため,$p=10$の場合を考えてみると,$e_{10}(0.01)=0.63, e_{10}(0.1)=0.80$である.
これは,10次元のパラメータ空間において入力データ点に対する全データ点の1%や10%の近傍を考慮するためには,入力変数に対してそれぞれ63%,80%の空間を近傍とみなさなければならないということを示している.
plt.figure(figsize=(6, 6)) for p in [1, 2, 3, 10, 100]: t = np.linspace(0, 1, 200) y = t ** (1 / p) plt.plot(t, y, label='p=%d' % p) plt.xlabel('体積の割合') plt.ylabel('距離') plt.legend()
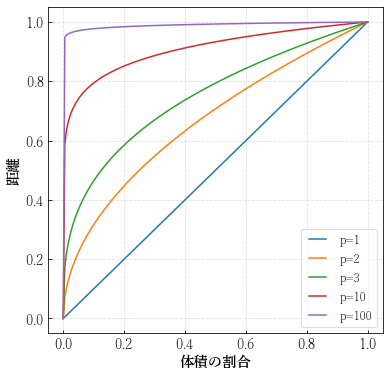
また,高次元空間においてはあらゆる点がデータの中心から離れて分布してしまうという問題がある.
データ点$\mathcal{D}=\{\boldsymbol{x_1},\boldsymbol{x_2},...\boldsymbol{x_N}\}$が$p$次元の超球内に一様分布している場合を考える.
半径が$d$である$p$次元超球の体積は係数を$k_p$のように表せば $$ V_p(d)=k_pd^ p $$ である.単位超球$B$内にデータが一様分布しているので,その確率密度関数は $$ p(X)= \left\{ \begin{array}{ll} 1/k_p & (\boldsymbol{x}\in B)\\ 0 & (\text{otherwise}) \end{array} \right. $$
である.
うち,距離$d=|\boldsymbol{x}|$に対して最も原点に近いデータ点$m=\min(\mathcal{D})$以上であるような確率,すなわち,$P(m<d)$は $$ \begin{eqnarray} P(m<d)&=&P(|\boldsymbol{x_i}|\geq d,\forall\boldsymbol{x_i}\in\mathcal{D})\\ &=&\prod_{\boldsymbol{x_i}\in\mathcal{D}}P(|\boldsymbol{x_i}|\geq d)\\ &=&\prod_{\boldsymbol{x_i}\in\mathcal{D}}(1-P(|\boldsymbol{x_i}|<d))\\ &=&\prod_{\boldsymbol{x_i}\in\mathcal{D}}\left(1-\int_{|\boldsymbol{x}|<d}p(\boldsymbol{x})d\boldsymbol{x}\right)\\ &=&\prod_{\boldsymbol{x_i}\in\mathcal{D}}\left(1-\frac{1}{k_p}\int_{|\boldsymbol{x}|<d}d\boldsymbol{x}\right)\\ &=&\prod_{\boldsymbol{x_i}\in\mathcal{D}}\left(1-d^ p\right)\\ &=&(1-d^ p)^ N \end{eqnarray} $$ これの中央値を考えると $$ \begin{eqnarray} (1-d^ p)^ N&=&\frac{1}{2}\\ d&=&\left(1-\left(\frac{1}{2}\right)^ {\frac{1}{N}}\right)^ {\frac{1}{p}} \end{eqnarray} $$ となる.$N=500,p=10$の場合,$d\approx0.52$となり,最近の点の中央値は境界までの距離の半分以上の位置にあることを示している.そのため,これは近傍点を用いた推論が極めて不安定なものになることを示唆しているといえる.
さらに,一般に標本化の密度は$N^ {1/p}$に比例するといわれている.$p=1$では$N=100$で十分な予測ができていたとしても,$p=10$ではこの条件と同様に密であるためには$N=100^ {10}$もの標本数が必要となる.
つぎに,実分布が$Y=f(X)=\exp(-8|X|^ 2)$という関係にあり,$\boldsymbol{x}$が$p$次元一様分布$U(-1,1)$から得られており,計測ノイズのないようなデータセットを考える.まず,このデータセットに対して$\boldsymbol{x}_0=0$に対する出力$y_0$を予測するといったタスクを考えると,$\boldsymbol{x_0}$に対する期待予測誤差は$f(0)$の平均二乗誤差(MSE)に相当する.ここで,平均二乗誤差は以下のように分解できる. $$ \begin{eqnarray} \text{MSE}(\boldsymbol{x_0})&=&\mathbb{E}_{\mathcal{T}}[(f(x_0)-\hat{y}_0)^ 2]\\ &=&\mathbb{E}_{\mathcal{T}}[(\hat{y}_0-\mathbb{E}_{\mathcal{T}}[\hat{y}_0]+\mathbb{E}_{\mathcal{T}}[\hat{y}_0]-f(x_0))^ 2]\\ &=&\mathbb{E}_{\mathcal{T}}[(\hat{y}_0-\mathbb{E}_{\mathcal{T}}[\hat{y_0}])^ 2+(\mathbb{E}_{\mathcal{T}}[\hat{y_0}]-f(x_0))^ 2+2(\hat{y}_0-\mathbb{E}_{\mathcal{T}}[\hat{y_0}])(\mathbb{E}_{\mathcal{T}}[\hat{y}_0]-f(x_0))]\\ &=&\mathbb{E}_{\mathcal{T}}[(\hat{y}_0-\mathbb{E}_{\mathcal{T}}[\hat{y}_0])^ 2]+ (\mathbb{E}_{\mathcal{T}}[\hat{y}_0]-f(x_0))^ 2+2\mathbb{E}_{\mathcal{T}}[(\hat{y}_0-\mathbb{E}_{\mathcal{T}}[\hat{y}_0])] (\mathbb{E}_{\mathcal{T}}[\hat{y}_0]-f(x_0))\\ &&~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(\because \mathbb{E}_{\mathcal{T}}[\hat{y}],f(x_0)は定数)\\ &=&\text{Var}_{\mathcal{T}}[\hat{y}_0]+\text{Bias}_{\mathcal{T}}^ 2[\hat{y}_0] \end{eqnarray} $$ と,バイアス項とバリアンス(分散)項に分解することができる.このバイアスバリアンス分解は任意の問題設定において適用が可能である.
実装例
ps = np.arange(1, 11) b = [] v = [] for p in ps: x = np.random.random((1000, p)) * 2 - 1 x_test = np.zeros((1, p)) y = np.exp(-8*np.linalg.norm(x, axis=1, keepdims=True)**2) y_test = np.exp(-8*np.linalg.norm(x_test, axis=1, keepdims=True)**2) # 図2.8の場合はこちらです # y = .5*(x + 1) ** 3 # y_test = .5*(x_test + 1) ** 3 # if p != 1: # y[:, 1:] = 1 # y_test[:, 1:] = 1 model = KNN(k=1) model.fit(x, y) y_pred = model.predict(x_test) bias = ((y_test - y_pred)**2).mean() var = np.var(y_pred, axis=1).mean() b.append(bias.ravel()) v.append(var.ravel()) b = np.array(b) v = np.array(v) plt.figure(figsize=(7, 5)) plt.plot(ps, b, label="Bias") plt.plot(ps, v, label="Variance") plt.legend()
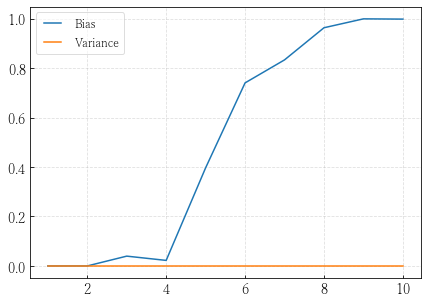
この場合は問題設定が大げさであるが,同様な問題は複雑なデータに関しても起こることが知られている.低次元でうまくいくようなモデルを,そのデータ数を変えずに高次元に対して応用した場合,思うような精度が出ず,必要となるデータ数が指数関数的に増加してしまう.
つぎに,線形モデルに$\epsilon\sim\mathcal{N}(0, \sigma^ 2)$の摂動が加わった $$ Y=X^ T\boldsymbol{\beta}+\epsilon $$ のモデルを最小二乗法で近似する場合を考える.
誤差項が加わったこの場合の期待予測誤差は
$$ \text{EPE}(\boldsymbol{x_0})=\sigma^ 2+\text{Var}_{\mathcal{T}}[\hat{y}_0]+\text{Bias}^ 2[\hat{y}_0] $$
となる.このモデルの下での最小二乗推定は不偏であることが知られており, $$ \text{Var}[\hat{y}_0]=\mathbb{E}_{\mathcal{T}}[\boldsymbol{x}_0^ T(X^ TX)^ {-1}\boldsymbol{x}_0\sigma^ 2] $$ である(証明は略.というより演習2.5が解けない) ので,共分散$\text{Cov}(X)$は$\mathbb{E}[X]\rightarrow0,N\rightarrow\infty$のもとでは $$ \text{Cov}(X)=\mathbb{E}[(X-\mu)(X-\mu)^ T]=\mathbb{E}[XX^ T]-\mu\mu^ T $$ と変形できることから,$\text{Cov}(X)\rightarrow\mathbb{E}[XX^ T]$であり,不偏であることから, $$ \mathbb{E}_{\boldsymbol{x}_0}[\text{EPE}(\boldsymbol{x}_0)]\sim\mathbb{E}_{\boldsymbol{x}_0}[\boldsymbol{x}_0^ T(X^ TX)^ {-1}\boldsymbol{x}_0\sigma^ 2]/N+\sigma^ 2 $$ $\boldsymbol{x}_0^ T(X^ TX)^ {-1}\boldsymbol{x}_0$はスカラーであり,スカラー値は自身の転置と当たり前ながら等しいので転置行列の性質$\text{tr}(AB)=\text{tr}(BA)$から, $$ \mathbb{E}_{\boldsymbol{x}_0}[\boldsymbol{x}_0^ T(X^ TX)^ {-1}\boldsymbol{x}_0]=\text{tr}(\mathbb{E}_{\boldsymbol{x}_0}[\boldsymbol{x}_0\boldsymbol{x}_0^ T] (X^ TX)^ {-1})=\text{tr}(\text{Cov}(X)\text{Cov}(X)^ {-1})=p $$ となり,結局 $$ \mathbb{E}_{\boldsymbol{x}_0}[\text{EPE}(\boldsymbol{x}_0)]=\sigma^ 2\left(\frac{p}{N}+1\right) $$ となる.
すなわち,最小二乗法では$N$を大きく,$\sigma^ 2$を小さくすることでバリアンスの次元数の増加に伴う線形増加を微小なものへと抑えることが可能であることを意味している.