日本百名城巡りその2 箕輪城
概要
箕輪城はおよそ500年前に長野業尚によって築かれた城です。群馬県高崎市にあり、昭和62年に国指定史跡に指定され、日本百名城にも選出されています。
歴史
| 西暦 | 城主 | 出来事 |
|---|---|---|
| 1512 | 長野家 | 長野業正によって築城される |
| 1561 | 業正が死去。業盛が後を継ぐ | |
| 1566 | 武田信玄によって攻められ、業盛は自刃 | |
| 1570 | 武田家 | 内藤昌豊が城代となる |
| 1575 | 昌豊が長篠設楽原の戦いで戦死。子の昌月が城代となる | |
| 1582 | 武田家が滅亡 | |
| 織田家 | 滝川一益が城主となる。本能寺の変後北条家の城となる | |
| 北条家 | 北条氏邦が城主となる | |
| 1590 | 小田原征伐で北条家が滅亡 | |
| 徳川家 | 徳川家の関東移封により井伊直政が城主となる | |
| 1598 | 井伊直政が高崎城を築城し、移る。それに伴い箕輪城は廃城となる | |
| 1987 | ------- | 国の史跡に指定される |
入城


見どころのようなものはあまりなく、立派な門があるぐらいでした。散歩コースになっており、お散歩している人がちらほらいましたが、観光地のような場所にはなっていません。
スタンプも城の敷地内にあるわけではなく、少し離れた役所のような場所にありました。上下逆さまに押してしまったがすごく悔しいです。。。笑


さいごに
散歩コースになっているので歩き甲斐のあるルートになっていました。駅からのアクセスはあまりよくなく、中々行くことができないので旅行のついでに行くことができてよかったです。
リンク
リンク
日本百名城巡りその1 鶴ヶ城(会津若松城)
概要
鶴ヶ城は福島県会津若松市にある城です。鶴ヶ城は会津城だとか会津若松城と呼ばれています。以後会津若松城と呼びます。会津若松城は会津若松駅から3kmほどのところにあります。
歴史
会津若松城は蘆名氏から始まり、幕府血縁の松平氏に終わりました。伊達や上杉氏など名家が城主となっていた時期がありますがどちらもかなり短いです。城での案内もやはり命名し長く治めていた蒲生氏郷のものが多かったです。
| 西暦 | 城主 | 出来事 |
|---|---|---|
| 1384 | 蘆名家 | 7代当主蘆名直盛によって築城、当時は黒川城と呼ばれる |
| 1553 | 16代当主蘆名盛氏が城主となる 蘆名家全盛期 |
|
| 1589 | 伊達家 | 伊達政宗が蘆名家を攻め滅ぼし、黒川城を入手 |
| 1590 | 伊達政宗が豊臣秀吉に臣従し、黒川城を没収される 蒲生氏郷入城 |
|
| 1593 | 蒲生家 | 7層の天守閣が完成 地の名前を黒川から若松に変え、城の名前を鶴ヶ城へと変更 |
| 1598 | 氏郷の子である秀行は家中騒動の影響で会津を没収される | |
| 上杉家 | 上杉景勝が入城 | |
| 1600 | 関ヶ原の戦いにて上杉家が西軍に加担したため会津を没収される | |
| 蒲生家 | 蒲生秀行が再度入城 | |
| 1627 | 跡取りがいない問題のため四国へ移封 | |
| 加藤家 | 代わりに同地から加藤家が入城 | |
| 1643 | 家中騒動のため改易 | |
| 松平家 | 徳川家光の弟である保科正之(後に松平へ改名)が入城 | |
| 1868 | 戊辰戦争の1つである会津戦争にて会津城は新政府軍に攻められ、開城 | |
| 1873 | --- | 廃城令によって鶴ヶ城は廃城となる |
入城
まず敷地に入ると全体マップがあります。

お堀を抜け、進んでいくと天守閣が見えてきます、ネットで見た通りの壮大さでした。天守閣が最近リニューアルされたらしいのですがかなり混んでおり、予定も詰まっていたので入ることができませんでした。次行くときはリベンジします。


天守閣の麓には自由市が開かれており、そこでは会津若松名物の味噌を使った食べ物や地酒、漆器などが売られていました。


さいごに
観光地として売り出されているだけに自由市や喫茶店など観光客向けのものが多くありました。100名城として初めて訪れるお城として楽しかったです。

リンク
論文メモ⑥:Spatially-Adaptive Pixelwise Networks for Fast Image Translation
論文の情報
- Spatially-Adaptive Pixelwise Networks for Fast Image Translation
- 論文リンク: https://arxiv.org/abs/2012.02992
- 被引用数(2021年11月時点): 3
- 採択日: 5 Dec 2020
- リンク:https://ai-scholar.tech/articles/image2image/ASAPNet
まとめ
CycleGANなどのある画像を別のドメインへ変換する技術はGANに関する研究の中でも活発に行われている分野の一つである。生成画像の品質や制度の向上と引き換えにモデルのサイズが大きくなり、計算量が膨大となる。本論文で提案されたASAP-Net(A Spartially-Adaptive Pixcelwise Network)はFigure 1のように既存手法と比較して性能をそのままに大幅に実行時間を減らすことに成功した。

手法の詳細は記事に示す通りであるが簡単に述べると高解像度の画像マップをダウンサンプリングすることによって低解像度で解釈を行う。その後各ピクセルごとのMLPを導入することで計算量を削減している。

感想
ピクセル単位でMLPを用いることは画像生成等において良い性能を出せていなかったのは有名な話だが、計算量を減らすためにピクセル単位で小さなMLPを導入するという発想が意外だった。論文を読み解説記事を書いたがこのような手法になった経緯等が筆者には難しく、なぜこのようなアーキテクチャになったかがあまりわからなかった。興味深い内容なのでまた時間があるときに読みたい。
論文メモ⑤:Reducing Transformer Depth on Demand with Structured Dropout
論文の情報
- Reducing Transformer Depth on Demand with Structured Dropout
- 論文リンク: https://arxiv.org/abs/1909.11556
- 被引用数(2021年8月時点): 142
- 採択日: 25 Sep 2019
- リンク:https://ai-scholar.tech/articles/dropout/LayerDrop
一言まとめ
Dropoutは深層学習を用いる際にほぼ必ずと言っていいほど使われる技術である。Dropoutとは一般的にノード間の重みを無視することを指すが、本論文ではノード間の重みではなく層全体をDropout、すなわち無視する。今回対象のモデルとして非常にDeepなモデルであるTransformerを正規化させ、学習を安定化させた。
本論文は実験を多く行っている。結果を以下に示したが他にも多くの実験でTransformerにLayerDropを施すことでスコアが上昇した。
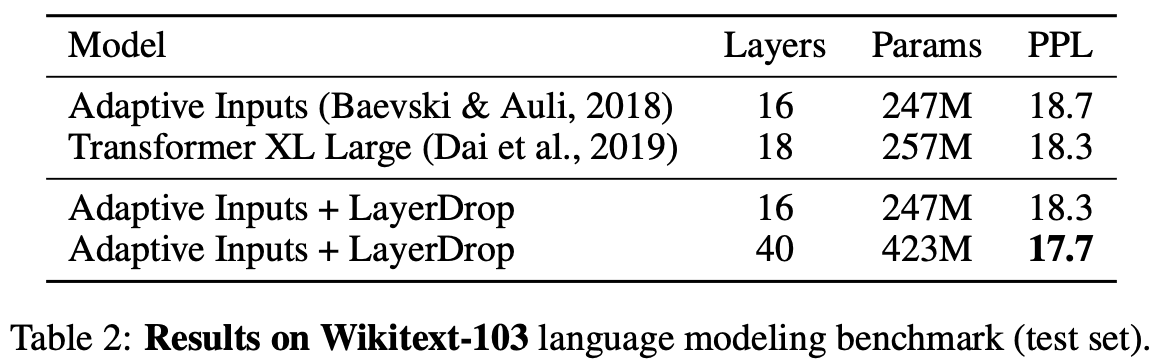
感想
層全体をDropoutするという発想は非常に面白かった。層をDropoutするのならば初めからなければ良いのでは?と思ったがそうではない。学習の過程でいらない層を識別し、Dropoutしてから再学習のような手法を取っているからだ。多くの実験で良いスコアを出しており、2019年に出された論文であるにも関わらず2021年最近の論文でLayerDropの文字を見ないのであまり使われていないのだろうか。見逃しているだけかもしれない。被引用数も多いので反響は大きかったと思う。
pandasのdatatime型でのAssertionError: <class 'numpy.ndarray'>
はじめに
pandasのdatetime型を扱ったときにエラーを吐かれ、検索してもほぼ出てこなかったので残しておきます。
問題設定
以下のようなcsvファイルをpandasで読み込み、dateをindexにした後にdateが2020年のものをスライスすることを目的とする。下の表は一例だがデータ収集の際、日付に関して降順にソートされている。
| title | date |
|---|---|
| aa | 2021/4/3 |
| bb | 2021/2/1 |
| cc | 2020/6/11 |
| dd | 2020/2/20 |
今回動かしたコードは以下:
import pandas as pd
df = pd.read_csv('./data.csv')
df['date'] = pd.to_datetime(df['date'])
df.index = df['date']
print(df['2020'])
まずdateが年/月/日となっているのでpandasのdatatime型に変換する。変換すると年-月-日の形となる。このdatatime型をindexに設定するといろいろと楽なのでindexを変更する。日付で範囲指定できたりスライシングができる。 https://qiita.com/sakabe/items/ae1fa47a58c796006627 とりあえず2020年のものを抜き出そうとすると、、、
AssertionError: <class 'numpy.ndarray'>
解決方法
初めに解決方法だけ書く。どうやらdatetime型は昇順にソートされていないとスライスができないようなのでdateに対してソートを行う。すなわちdf = df.sort_index()を追加することで期待する出力(=2020年のtitle)が得られる。
原因
AssertionErrorはプログラムが設定されたアサーションがFalseとなったときに出るエラー。今回はpandas側でエラーが出ている。エラーログを見るとassert isinstance(slobj, slice), type(slobj)となっているため本来受け取ってはいけないnumpy配列型がきてしまっている。pandasの中身を見てみるとslice型?スライスオブジェクトを受け取るらしい。それが何故昇順にソートすることでnumpy配列からスライスオブジェクトになるのかはわからない。numpy配列で何を受け取っているのか確認すると元のインデックスを受け取っているようだった。また、(ないとは思ったが)sort_index()で特別な処理がされているのでは?と思い敢えて降順でソートsort_index(ascending=False)として実行してみたが同様のエラーが出た。よって昇順にソートされていることが重要であると考えられる。もし何か知っている方がいたら教えてください…。
論文メモ④TransGaGa: Geometry-Aware Unsupervised Image-to-Image Translation
論文の情報
- TransGaGa: Geometry-Aware Unsupervised Image-to-Image Translation
- 論文リンク: https://arxiv.org/abs/2003.02819
- 被引用数(2021年3月15日時点): 40
- 採択日: 21 Apr 2019 UTC
- プロジェクトページ: https://wywu.github.io/projects/TGaGa/TGaGa.html
簡単なメモ
CycleGANなどの従来の手法は、猫⇔人間などの大きな幾何学的変化を伴うドメイン変換のimage2imageタスクは達成できていなかった。提案手法では入力画像をgeometry(向き)とappearance(形状)に分け、それぞれ潜在変数に落とし、さらにそれぞれに変換器を用意することでタスクを達成している。アーキテクチャは以下の図(論文より)。

geometryはヒートマップを用いて表現されている。このヒートマップをきちんと実現するための損失関数が導入されている。
さいごに
アーキテクチャや損失関数の自分なりの詳細な解説はこちらに書かせていただいたので興味のある方は是非。
2020年第3回G検定合格体験記
はじめに
資格とかには特に興味がなかったのですが、コロナの影響で大学へあまり行くことができず、春休み~夏休みを何もせずに過ごしさらに年も越してしまいそうな勢いだったので何かやることのきっかけが欲しくて受験を決意しました。研究室で深層学習について学んでいるので1週間あれば大丈夫だろ~wと思い1週間前にやっと申し込みしました。しかし受験日が卒業研究中間発表の数日前で資料の作成等をしなければならず、あまり勉強時間が確保できませんでした。
G検定とは
G検定は日本ディープラーニング協会が開催している資格であり、深層学習などの人工知能全般に関する知識問題が出題されます。計算問題はほぼ無く、法律に関する問題や用語に関する問題が多く出題されます。シラバスは以下の通りです。

G検定はネット受験なので好きなだけインターネットで調査することが可能です。しかし当然運営さんもそれは承知であるため時間は厳しく設定されています。試験時間は120分で問題数は220問ほどです。全ての問題を逐一調べていたら間に合いません。
合格率は6~7割とかなり高いです。合格率が高いため余計にプレッシャーを感じました。今回受けた試験は従来よりも合格率が低く、やはり受けてみても思ったより難しかったです。



難易度は低い試験なので人工知能初学者の大学生が受けてそうだな~と思っていたんですが意外と開発職の2,30代の方が受けていて驚きました。それだけ会社で人工知能を導入しているということでしょうか、知らんけど。
勉強方法
何からやればいいのかようわからんかったのでとりあえず公式テキストなるものを読もうと思い、1週間前に買い、全9章あるため1日2章で4日目は3章読むことで4日で読み終わらせました。
残り2日は問題集を半分ずつ解きました。当日はなんかやる気が起きなくて何もやっていません。テストあるあるじゃないですか??直前にやる気なくなるの。
勉強方法の振り返りなのですが、まず公式テキストはかなり浅く広くといった印象を受けました。元から知っている単語は「あーはいはいそれね」となるのですが初見の単語だと説明が浅すぎて全く頭に入ってきません。特にRNNやCNN周りの応用の範囲は少し難しいで別で検索して理解をしておく必要があります。ただ範囲がある程度広いためこのようになることはしょうがないと思います。カバーしきれていない分を問題集で演習を積みつつ補填するイメージです。また、試験中に逐一参考書を開いて~とやるのは効率が悪いので事前に自分の言葉でどこかのファイルにまとめておきましょう。検索すると他の方がまとめた記事が大量に見つかるのですが網羅できているかわかりませんし、自分でまとめたほうが当日見つけるのも読み解くのも時間が圧倒的にかかりません。勉強時間は1日3時間程度行いました。
リンク
リンク
試験
試験は先ほども書きましたが法律周りの問題が圧倒的に多く、知識問題は事前の知識で事足りる程度のものが多かったです。法律は試験中に調べるつもりだったので試験中はひたすらに法律についてググっていました。他の受験者も同様だったようでG(oogle)検定などと言われていました。公式テキストからはほぼ出題されていない印象でした。
総評
今回の目的は資格をとることよりも人工知能を体系的に学ぶことでした。結果的に試験前の参考書での勉強や当日の試験での検索で知見を深めることはできたと思います。ただ資格自体に価値があるかと問われるとプログラムや理論的なことは全く問われないので機械学習エンジニアになりたいような人には難易度等考慮してあまり感じられませんでした。しかし初学者であったり私のように勉強するきっかけとして受験することには意味があると思います。
SGDを使うにあたってのハイパーパラメータの設定(論文紹介③ Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence)
概要
深層学習において、確率的勾配降下法(SGD)はOptimizerとして良い結果を出しており、SGDをより良く動かすためにハイパーパラメータの調整が必要。複数あるハイパーパラメータのうち、特にバッチサイズ(Batch Size)と学習率(Learning Rate)に着目し、どのように設定すべきかを解析的に考えた論文。数値解析の結果、バッチサイズの大きさSと学習率ηの比S/ηが小さいほどより良い結果となる。
予測損失と経験損失
本来最小化したい損失は予測損失である。

しかし、データの分布Dがわからないため予測損失と近似することのできる経験損失を用意する。

できるだけ経験損失が予測損失と近くなるようにアルゴリズムを設定したい。以後、経験損失を最小化することを目的とする。
解析的証明(略)
※具体的な証明は別で記事にする…かもしれません※
経験損失と予測損失の差(≒アルゴリズムの良さ)の変数部分をIと置く。また、バッチサイズと学習率の比をk(=|S|/η)と置き、Iをkで微分すると以下になる。

パラメータ数dが十分に大きい、具体的に以下の条件を満たすと仮定すると∂I/∂kは常に正となる。

この時、変数kはS,η>0より予測損失と経験損失の差はk>0で単調増加である。よってバッチサイズと学習率の比が予測損失と経験損失の差と正の相関がある。つまりaccuracyとは負の相関があるということでありkが小さいほどより良い結果が得られると期待できる。この時、むやみにkを小さくすれば良いというわけではなく、あくまで上記のdの範囲内であることに注意。
実験
- モデル…ResNet-110,VGG-19
- データセット…CIFAR-10,CIFAR-100
- バッチサイズ…16,32,48,64,80,96,112,128,144,160,176,192,208
- 学習率…0.01,0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.09,0.10,0.11,0.12,0.13,0.14,0.15,0.16,0.17,0.18,0.19,0.20
- エポック数…200
以上の実験設定でテスト誤差(accuracy)を比較。スピアマンの順位相関係数(SCC)を求める。
実験結果
Ⅰバッチサイズとaccuracy
表左部の学習率で固定し、バッチサイズとaccuracyでSCCを取る。SCCが全てのケースで-1.0付近なのでバッチサイズとaccuracyは負の相関がある。

Ⅱ 学習率とaccuracy
表左部のバッチサイズで固定し、学習率とaccuracyでSCCを取る。SCCが全てのケースで1.0付近なのでバッチサイズとaccuracyは正の相関がある。

Ⅲ バッチサイズと学習率の比とaccuracy
横軸にBSとLRの比(=k)、縦軸にaccuracyをとると負の相関があることがわかる。


まとめ
数値解析と実験結果から、バッチサイズと学習率の比が予測損失と経験損失の差と正の相関(=accuracyと負の相関)があることがわかった。よってSGDで学習率を行う時はバッチサイズを小さく、学習率を大きくすると結果が良くなると期待できる。しかし、パラメータの制約等があるためむやみに大きくor小さくすれば良いというわけではない。
便利なPythonのリスト内包表記
最近、競プロみたいな問題をPythonで解いたりしているのですが、その時にデータの入出力周りでリストをよく扱います。いたずらにfor文とappend()メソッドを用いるとコードが冗長になってしまうのでリスト内包表記を用いるのですがちゃんと調べたことがなかったので調べて備忘録としてまとめます。
リスト内包表記のメリット・デメリット
- コードが短くなる
- 実行速度が上がる
- Pythonわかってる風になれる
- あまりディープな表記にすると可読性が著しく下がる
シンプルなリスト内包表記
元データ
for文
data =
for i in range(10):
data.append(i)
print(data)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
リスト内包表記
[式 for 変数 in イテラブルオブジェクト]といった形です。上記のfor文記法と比較するとわかりやすいと思います。
data = [i for i in range(10)]
print(data)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
補足
上記の例ではrange()から1つずつ要素を抽出しましたが、そのままlist()関数でリスト化できます。
data = list(range(10))
print(data)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
リストの型を変える
先ほどのリストの各要素はint型です。それをstr型に変更します。
for文
data_str =
for i in data:
data_str.append(str(i))
print(data_str)
#['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
リスト内包表記
data_str = [str(i) for i in data]
print(data_str)
#['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
補足
map関数を使うことで同様の処理をすることができます。
data_str = list(map(str,data))
print(data_str)
#['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
if文のあるリスト内包表記
if文のみ
for文
data_if =
for i in data:
if i == 2 or i == 8:
data_if.append(i)
print(data_if)
#[2, 8]
リスト内包表記
[式 for 変数 in イテラブルオブジェクト if文]といった形です。
data_if = [i for i in data if i == 2 or i == 8]
print(data_if)
#[2, 8]
if-else
まず、先ほど作成したdata_strに要素を追加します。
data_str.append('G')
print(data_str)
#['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'G']
for文
int型への変更が可能であるならばint型にし、不可能ならばそのままにするプログラムです。
data_ifelse =
for i in data_str:
if i.isdigit():
data_ifelse.append(int(i))
else:
data_ifelse.append(i)
print(data_ifelse)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'G']
リスト内包表記
先ほどのif文と位置が異なります。
[Trueの式 if 式 else Falseの式 for 変数 in イテラブルオブジェクト]と書きます。
elif文はif-elseを組み合わせて記述することができますが、可読性が落ちてしまうので辞めた方がいいかもしれません。
data_ifelse = [int(i) if i.isdigit() else i for i in data_str]
print(data_ifelse)
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'G']
まとめ
今回はPythonのリスト内包表記についてまとめました。内包表記はリストだけでなく、dict型やset型にも同様に使えるので試してみてください。繰り返しになりますが、ここで挙げた以上の複雑な処理を内包表記で書くととても読みにくくなってしまうので注意が必要です。実行速度が上がるとメリットで書きましたが、そこまで大きな差はなく、これぐらいを気にするのならばリストではなくnumpy配列等を使った方がよほど早くなります。
言語処理100本ノック2020 第4章 Pythonでの解答例
前章↓↓
第4章 形態素解析
まず、与えられたneko.txtをMeCabを使って形態素解析します。MeCabの導入等は別途調べてみてください。形態素解析するコマンドは以下の通りです。
mecab neko.txt --output neko.txt.macab
30.形態素解析結果の読み込み(31日目|9月4日)
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
まず、各行をタブ(\t)区切りで分割します。文末文字(EOS)のみである行があるため、それを除くために分割した長さが2である場合にのみ適用します。分割した後の方を次は','区切りで分割し、それぞれ求められたキーとマッピングします。
31.動詞(32日目|9月5日)
動詞の表層形をすべて抽出せよ.
30で作成した辞書型のデータを使います。まず、動詞の重複等が考えられるのでset()を用いて重複する要素を除きます。
32.動詞の原形(33日目|9月6日)
動詞の原形を全て抽出せよ.
31と同様です。
33.「AのB」(34日目|9月7日)
2つの名詞が「の」で連結されている名詞句を抽出せよ.
"名詞"+”の”+"名詞"となっている場所を探します。
34.名詞の連接(35日目|9月8日)
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
現在参照している品詞が名詞ならばtempに追加し、次の文字を参照する。次の文字も名詞ならば再度tempに追加する。tempの長さが2以上つまり名詞が2連続以上続いているならばそれを出力します。
35.単語の出現頻度(36日目|9月9日)
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
単語と出現回数を対応させたdictを作成します。そのままカウントを開始すると','や'。'をカウントしてしまうため、posが記号のものはdictへ格納しないようにします。未登録の単語が来た場合、新たにdictへ登録し、その後登録未登録に関わらずインクリメントします。
36.頻度上位10語(37日目|9月10日)
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
35で出現頻度順にしたデータが用意されたのでそれを使います。棒グラフにする際、横軸のラベルを単語にします。それが当然日本語であり、そのままグラフにすると日本語は豆腐になってしまうため専用のライブラリ?をインストールします。pip install japanize_matplotlibを実行してから動かしましょう。

37.「猫」と共起頻度の高い上位10語(38日目|9月11日)
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
今回、何をどうするかが具体的に問題文で示されていません。自分で何を"よく共起する"か定義する必要があります。僕は"猫"の前後5単語の記号と助詞、及び助動詞を除いた品詞をそれとし、カウントしました。

38.ヒストグラム(39日目|9月12日)
単語の出現頻度のヒストグラムを描け.ただし,横軸は出現頻度を表し,1から単語の出現頻度の最大値までの線形目盛とする.縦軸はx軸で示される出現頻度となった単語の異なり数(種類数)である.
35のデータをヒストグラムにするだけで特に難しいことはないです。

39.Zipfの法則(40日目|9月13日)
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
対数グラフはそれぞれのスケールをlogにすればよいのでplt.x(y)scale('log')とします。余談ですが、Zipf(ジップ)の法則は、ある膨大なテキストの要素を出現頻度順にしたとき、その順位と頻度を乗算すると定数になる法則です。つまり今回は縦軸に出現頻度、横軸に順位としているためプロットしたグラフは1次関数のような形になることが期待されます。

以上で4章は終わりです。お疲れ様でした。
言語処理100本ノック2020 第3章 Pythonでの解答例
第2章↓↓
第3章:正規表現
20.JSONデータの読み込み(21日目|8月25日)
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
今回与えられたデータはよく見るJSONと少し形式が異なります。一行ずつ読み込む必要があるのでfor文で1行ずつ読み込みます。そのタイトルがイギリスであるテキストを出力します。
21.カテゴリ名を含む行を抽出(22日目|8月26日)
記事中でカテゴリ名を宣言している行を抽出せよ.
カテゴリを宣言している行は"Catedory:〇〇"という形になっています。[]は正規表現で用いられる記号なので\でエスケープします。そしてCategory:の後は任意の文字がくるので.*とします。pythonで正規表現を用いる時はreモジュールをインポートします。findall()に正規表現と対象データと複数行にマッチさせるためにre.MULTILINEを引数として渡します。
22.カテゴリ名の抽出(23日目|8月27日)
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
21で抽出したもののうち、":"以降であり、"|*"より前まで抽出したいです。前者は簡単なのですが、後者をどのようにすれば良いのかわかりませんでした。調べた結果、(?:pattern)とすることでそのpatternをマッチした場合、抽出しないことができるそうです。正規表現だけ用いる必要がないならば"|"をreplace()したりすることで実装可能です。
23.セクション構造(24日目|8月28日)
記事中に含まれるセクション名とそのレベル(例えば”== セクション名 ==”なら1)を表示せよ.
セクションのレベル?はよくわからないのですが、おそらく"=="の長さ-1がレベルなんでしょう。["=の部分","セクション名","=の部分"]のような形でリストに格納します。[^pattern]はpattern以外のものにマッチします。
24.ファイル参照の抽出(25日目|8月29日)
記事から参照されているメディアファイルをすべて抜き出せ.
参照されているファイルは"ファイルorFile"の後にファイル名が指定されます。そこを指定して抽出します。
25. テンプレートの抽出(26日目|8月30日)
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
基礎情報のフィールド名と値は、「|"フィールド名""任意の空白文字"="任意の空白文字""値"」となっています。なのでそれを抽出する正規表現をpatternマッチさせます。\sは任意の空白文字です。それを辞書型に保存します。
26.強調マークアップの除去(27日目|8月31日)
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
指定されたマークアップ早見表を見てみると、強調には「'」が使われています。この数によって強調の度合いが変わりますが、2~5個であるため25のresultに正規表現で指定して削除します。\で'をエスケープし、{n,m}でその数を指定します。それをsub()関数で削除します。
27.内部リンクの削除(28日目|9月1日)
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ(参考: マークアップ早見表).
(内部リンクは内部リンク|表示名となっているのでそれを削除すればいいのだがよくわからなかった)
28.MediaWikiマークアップの削除(29日目|9月2日)
27で内部リンクは削除できた(?)ので残りの部分の気になるところを削除します。<br>等のhtmlタグを削除しました。
29.国旗画像のURLを取得する(30日目|9月3日)
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
WikiのAPIを使って画像urlを取得します。APIの説明は以下のページから
Pythonでのサンプルコードもあるので利用します。サンプルでpropはimageinfoが指定されているためそこからさらに画像urlを指定するにはiipopでurlを指定するだけです。結果をjsonで受け取り構造を確認してurlを出力します。
これで第3章は終わりです。お疲れ様でした。
言語処理100本ノック2020 第2章 Pythonでの解答例
第1章↓↓
- 第2章:UNIXコマンド
- 10.行数のカウント(11日目|8月15日)
- 11.タブをスペースに変換(12日目|8月16日)
- 12.1列目をcol1.txtに、2列目をcol2.txtに保存(13日目|8月17日)
- 13.col1.txtとcol2.txtをマージ(14日目|8月18日)
- 14.先頭からN行を出力(15日目|8月19日)
- 15.末尾のN行を出力(16日目|8月20日)
- 16.ファイルをN分割する(17日目|8月21日)
- 17.1列目の文字列の異なり(18日目|8月22日)
- 18.各行を3コラム目の数値の降順にソート(19日目|8月23日)
- 19.各行の1コラム目の文字列の出現頻度を求め、出現頻度の高い順に並べる(20日目|8月24日)
第2章:UNIXコマンド
※UNIXコマンドとありますが、筆者は現在WindowsにしかPythonの実行環境をそろえておらず、Linuxもさっぱり使っていないのでコマンドは省略します。他の方がやった解答を見て自分のプログラムの出力が正しいことは確認します。※
10.行数のカウント(11日目|8月15日)
行数をカウントせよ.確認にはwcコマンドを用いよ.
テキストファイルをpythonで読み込む方法は何通りかありますが、今回は最も(?)ポピュラーなpandasを使います。pandasで読み込み表示するだけで行数*列数も表示されるのですが、shapeを使ってそれぞれ表示してみます。行数だけでなく、ついでに列数を表示させてみました。
11.タブをスペースに変換(12日目|8月16日)
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
区切り文字をタブにして読み込んだtxtファイルを区切り文字を半角スペースにして保存します。この時、headerとindexをFalseにしておかないとインデックス番号等がついたまま保存されてしまうので注意が必要です。
元のファイルと出力されたファイルの一部
Get-Content data.txt -last 5
Benjamin M 13381 2018
Elijah M 12886 2018
Lucas M 12585 2018
Mason M 12435 2018
Logan M 12352 2018
Get-Content newdata.txt -last 5
Benjamin M 13381 2018
Elijah M 12886 2018
Lucas M 12585 2018
Mason M 12435 2018
Logan M 12352 2018全体↓↓
12.1列目をcol1.txtに、2列目をcol2.txtに保存(13日目|8月17日)
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
df[0]に1列目がdf[1]に2列目が格納されているのでそれを保存します。
結果
13.col1.txtとcol2.txtをマージ(14日目|8月18日)
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
pandasのconcat()関数を使います。デフォルトだと縦方向にマージしてしまうので、axis=1とすることで横方向にマージするよう指定します。
出力ファイルは上記のgithubにあります。
14.先頭からN行を出力(15日目|8月19日)
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち先頭のN行だけを表示せよ.確認にはheadコマンドを用いよ.
コマンドライン引数はsys.argvで受け取ります。ここで注意すべきは第一引数がargv[0]ではなくargv[1]に格納されていることです。受け取ったnはstr型なのでint型に変換し、pandasの関数head()に渡します。
15.末尾のN行を出力(16日目|8月20日)
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち末尾のN行だけを表示せよ.確認にはtailコマンドを用いよ.
14と同様です。異なる点はhead()ではなく、tail()を使います。
16.ファイルをN分割する(17日目|8月21日)
自然数Nをコマンドライン引数などの手段で受け取り,入力のファイルを行単位でN分割せよ.同様の処理をsplitコマンドで実現せよ.
演算子'//'は除算の結果を切り捨てます。例えば10//3ならば3となります。
17.1列目の文字列の異なり(18日目|8月22日)
1列目の文字列の種類(異なる文字列の集合)を求めよ.確認にはcut, sort, uniqコマンドを用いよ.
duplicated().value_counts()は重複する場合にTrueとします。なのでFalseの数が重複しない要素の数です。例えばAnna,Bnna,Cnna,Annaだった場合、False,False,False,Trueとなります。重複しない要素を取り出すにはunique()メソッドを使います。その要素数を数えるにはlen(df.unique())でもいいのですが、nunique()によっても得られます。
18.各行を3コラム目の数値の降順にソート(19日目|8月23日)
各行を3コラム目の数値の逆順で整列せよ(注意: 各行の内容は変更せずに並び替えよ).確認にはsortコマンドを用いよ(この問題はコマンドで実行した時の結果と合わなくてもよい).
sort_values()を用います。引数にソートしたい対象のコラムを指定します。今回は3カラム目なので2を指定しました。出力は先頭の5行のみとしています。
19.各行の1コラム目の文字列の出現頻度を求め、出現頻度の高い順に並べる(20日目|8月24日)
各行の1列目の文字列の出現頻度を求め,その高い順に並べて表示せよ.確認にはcut, uniq, sortコマンドを用いよ.
value_counts()メソッドを用います。value_counts()は出現回数のカウントだけでなく、デフォルトで降順にソートしてくれるため題意の出力をすることができます。ソートをしたくない場合はvalue_counts(sort=False)とし、昇順にしたい場合はvalue_counts(ascending=True)とします。
これで第2章は終わりです。
第3章↓↓
言語処理100本ノック2020 第1章 Pythonでの解答例
はじめに
夏休みに入り、研究室のゼミも少なくなったりコ〇ナの影響でバイトがなくなったりして暇なので1日1個言語処理100本ノックを第3章までやりたいと思います。第3章までとしているのは、とりあえずデータの前処理を再勉強したいということと短期的な目標としたいからです。8月5日から始めるので順当にいけば9月3日に終わります。しかし、僕のことなので途中で飽きてサボってしまったり、辞めてしまったりするかもしれません。というか多分なります。1週間続けば自分としては立派だと思います。統計学入門も終わってないし…。
※毎日別の記事として投稿すると記事数がとても多くなってしまうので各章ごと(全10章)記事として保存します。各章が終わるまで同一の記事に更新していこうと思います。更新する度タイトルの〇日目も変えます。※
第1章:事前準備
00.文字列の逆順(1日目|8月5日)
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
2通りのやり方で解きました。1つ目はreversed()を用いて逆順にし、リスト化した後に結合する方法です。2つ目はスライシングによって直接逆順にします。a[::-1]は"最初から最後まで逆順に1つずつ抜き出す"という意味です。2つ目の方が簡単ですね。
01.パタトクカシーー(2日目|8月6日)
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
00と同様、スライシングで解く手法が最も楽です。たまたま今回は1,3,5,7となっているため、[::2](最初から最後まで2つおきに)とすることで実装することができましたが、1,2,4,6,9…番目を取り出せという問題でも対応することが可能なように泥臭い手法も書いておきました。
02. 「パトカー」+「タクシー」=「パタトクカシーー」(3日目|8月7日)
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
for文で複数のイテラブルオブジェクトを取得するためにzip()関数を使います。iにパトカー、jにタクシーがそれぞれ入ります。ans_1とans_2を用意しましたが、ans_1はリスト内包表記をとっているので見慣れていない方は何をやっているのかわかりにくいかな、と思ったのでans_2で少し冗長な導出をしました。どちらもやっていることは変わりません。リスト内包表記を簡単に説明すると、[式 for 変数 in リスト等]となります。ans_2にもある通り、これはfor 変数 in リスト等: リスト.append(式)と同じ意味です。
03.円周率(4日目|8月8日)
“Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.”という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
方針としてはまず単語ごとにリストに格納します。しかしこの時","や"."があると文字数がおかしくなるのでこれらを削除します。replace()は第1引数を第2引数に置換します。なので本プログラムのように書くと削除することが可能です。今回、2文字削除したいため2回replace()しています。削除したい文字がより多くなるのならば正規表現によって削除するやり方もあるようなのでそちらにしましょう。リストに格納した後はリストの各要素の長さ(=単語の文字数)を取得します。今回もリスト内包表記を取っています。iに_listに入っている各単語が入り、iの長さを取っています。
04.元素記号(5日目|8月9日)
“Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.”という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭の2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
今回は辞書型を作成します。01.のように規則的に取り出す対象が並んでいないので対象のインデックス番号のリストを作成します。 enumerate()は2つの変数に値を入れていきます。1つ目にはインデックス番号、2つ目には対象オブジェクト(リスト等)の中身です。対象の単語ならば1文字目([0])、そうでないならば2文字目まで([:2]=0,1)を取り出し辞書へ格納します。
05.n-gram(6日目|8月10日)
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,”I am an NLPer”という文から単語bi-gram,文字bi-gramを得よ.
n-gramとはある文字列をn個の単語や文字で区切ることを言います。ここで問題になっているbi-gramは2-gramです。関数自体は単純なもので引数として受け取ったn-gramのn個ごと文章の最初から区切っているだけです。
06.集合(7日目|8月11日)
“paraparaparadise”と”paragraph”に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,’se’というbi-gramがXおよびYに含まれるかどうかを調べよ.
まずbi-gramを作成します。05で作成した関数をimportで呼び出します。ファイル名を05.pyとしてので直接importせず、__import__()によって呼び出します。詳しくは以下に書きました。
そのままだと重複する要素('pa'など)があるため集合として機能しません。そのためset()を用いることで重複する要素を消し、集合演算を行うことのできるようにします。その後は各集合に演算子やメソッドが用意されているのでそれを使うだけです。今回、例として両方とも使っています。'se'があるかどうかはin演算子を使い確認します。
07.テンプレートによる文生成(8日目|8月12日)
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y=”気温”, z=22.4として,実行結果を確認せよ.
format()メソッドによって文字列内に変数を入れます。あとは特に説明することはないです。
08.暗号文(9日目|8月13日)
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
・英小文字ならば(219 - 文字コード)の文字に置換
・その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.
問題文の219が何かわからなかったので英小文字の文字コードをまず調べます。文字コードはord()によって調べることが可能です。"a"が97、"z"が122なので97+122=219となります。つまりa→z、z→aのように暗号化、復号化をします。文字コードから文字への変換はchr()を使います。英小文字か否かの判定はislower()を使います。英小文字ならば暗号、復号化を行いそれ以外だったらそのままにします。結果を見ると大文字の"I"と"."がそのまま出力されており、復号化もできていることがわかります。
09.TypoglycemiaPermalink(10日目|8月14日)
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば”I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .”)を与え,その実行結果を確認せよ.
入力を単語とする関数typo()を作ります。受け取った単語の長さが5以上ならば(元の単語の1文字目)+(真ん中をシャッフル)+(元の単語の最後)のリストを作り、join()で結合したものを返します。
これで第1章は終わりです。
第2章↓↓
Pythonのスクリプトをimportするときにエラーが出たのでメモ
はじめに
Pythonスクリプトのimportでファイル名関係でエラーが出たのでメモ
問題
例として以下のファイルをimportしたいとします。
def test():
a = 'test'
return a
〇〇.pyである時、普通ならば単に
import 〇〇
とすれば良いです。しかしファイル名が
①"-"(ハイフン)を含む
②数字から始まる
のいずれかを満たすと「SyntaxError: invalid syntax」と出ます。
解決策
今回、例として0a-a.pyを呼び出します。
module = __import__('0a-a')
print(module.test()) #test
__import__()を使ってスクリプトを呼び出します。これはimport 0a-a as moduleと同じように扱うことが可能です。
さいごに
本来、このような手法を使わなくても良いようにファイル名には気を付けましょう。どうしてもハイフンが含まれているファイル名を使わなければならない時にのみ使うようにした方が良さそうです。
統計学入門(基礎統計学Ⅰ)第8章演習問題
第8章
8.1
確率変数
に従っている。中心極限定理から、
となる
を定め、
のときの
の値を求めよ。
ベルヌーイ分布の期待値、分散は6章のものを使用します。
平均で引いて標準偏差で割る標準正規化を施すと平均0,分散1の標準正規分布に従うため、正規分布表を使用することができます。

8.2<ランダムウォーク>
確率変数
は独立で、確率分布
に従っている。ただし、
(1)nが大きいとき、
の近似的確率分布を求めよ

8.3
昨シーズンを2割8分の打率で終わった打者が、今シーズンもこの確率でヒットを打つものとし、450打席であるとすると、3割バッターになれる確率はどれくらいか、またこのバッターが、確率0.2以上で3割バッターになろうとすると、打率はどのぐらいでなければならないか。

このような結果になるのは面白いです。
リンク