Aidemyの特徴と料金を分かりやすく解説!
こんにちは!budouです! 今回は、私の所属する会社で「AI活用・データ活用に関しての良さげな研修はないか?」というテーマでAidemyを調べていましたが、法人の研修のみならず個人にとってもAidemyは良さそう。 と思ったので、こちらで紹介させて頂ければと思います。
主に、
- 「AI・データ分析のスキルを身に着けたいけどどこからやればよいのか?」という方
- Aidemy気になってるけどちゃんと調べられてない
という方に向けての記事になります。
<目次>

Aidemyとは
代表の石川さんが2014年に東大在学中に始めたベンチャー企業。
現在は正社員・アルバイト含めて80人以上とのことで目下急成長の会社ということになるでしょう。
そんなアイデミー株式会社が2017年にローンチしたのが「Aidemy」というサービスとのこと。
現在は100超の企業での導入、50,000人を超える個人のユーザーが使用している。
Aidemyの特徴
Aidemyの特徴としてまとめると下記4点かなと思います。
- 無料で始められて、3ヶ月で使えるレベルにスキルアップ
- プロのチューターによるコードレビュー
- AIdemy社メンターによる徹底的なオンラインコーチング
- 条件を満たすと最大70%の返金を国から受けられる「教育訓練給付金」の対象サービス
無料で始められて、3ヶ月で使えるレベルにスキルアップ
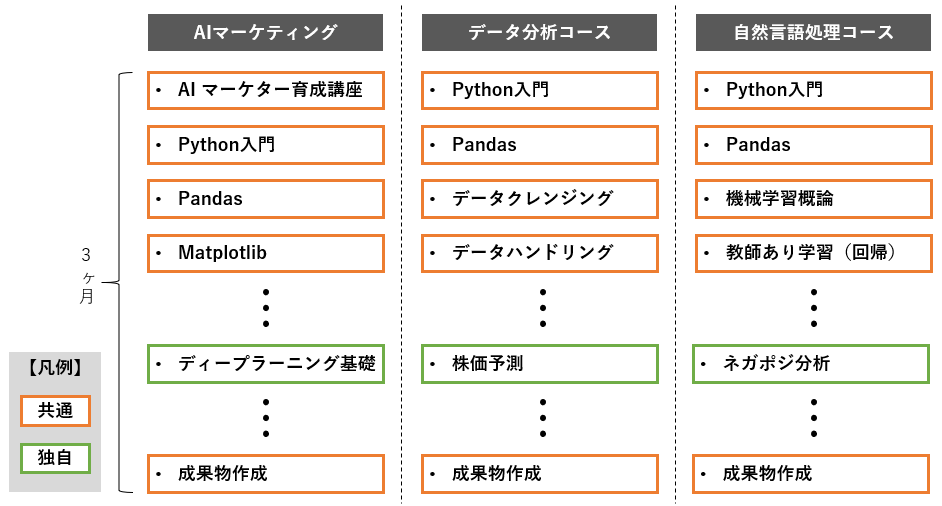
HPのトップでも書かれている通りのAidemyの売り文句とも捉えられると思います。 3ヶ月の根拠ですが、基本的な構成(イメージ)は↓のようになっているみたいです。
プロのチューターによるコードレビュー
書いたコードをチューターがレビューしてくれるそうです! 独学をしていると「これは正しい書き方なのか...?」と疑問に思うところが死ぬほど出てきますが、始めにフィードバックを受けることが出来ると確かにありがたい面がありそうです。 始めの内はフィードバックを受けてもチンプンカンプンな事もあると思いますが、一度考えて書いたコードに対してのフィードバックというのは1年後に見直しても学びが多いものです。
AIdemy社メンターによる徹底的なオンラインコーチング
ここが独学とスクール受講の大きな違いですね。
「聞ける人がすぐそばにいる」ということ。Aidemyは講師がマンツーマンで一人ひとりの学習進度に合わせてサポートしてくれるよう。
プログラミングで挫折してしまう人はやはり初期で躓いてしまうことが多いのですが、それを回避するための転ばぬ先の杖がこのオンラインコーチング(サイト上ではオンラインメンタリングとも言われている)かと思います。 結果まで辿り着くことが出来るということが自信を得るうえでも重要なのは間違いないですが、そのために調べても分からないことを直ぐに聞いて教えてもらえる環境というのはかなり重要です。
条件を満たすと最大70%の返金を国から受けられる「教育訓練給付金」の対象サービス
厚生労働省から出ている教育訓練給付制度 |厚生労働省 をAidemyのスクールを受講する事でも給付対象として助成金を受け取ることが出来るそうです。 なんと最大70%キャッシュバック...! 対象講座としての期限があるそうですがこれは大きいですね。 全講座が対象となるわけではなさそうですので、気になる方は「無料相談会」に参加してみると詳細の説明を聞くことが出来ます。

料金体制
気になる料金ですが、 [キャプ] 3ヶ月で48万円ということで安くはないですが、プログラミングを自身の武器にして生きていくには決して高くはないですね。 受講後8日間は全額返金保証期間を設けているということで良心的な仕組みも敷かれています!! また国からの70%給付を利用するのも良いですね。
おわりに
「AI活用・データ活用に関しての良さげな研修はないか?」というテーマでAidemyに関して調べたところ、 大手法人が導入しているだけあってAIリテラシー獲得という文脈でも、個人のスキル向上による市場価値の向上という点でも有用であると感じたため今回ご紹介させて頂きました。
全額返金保証期間であったり、最大70%の国からのサポートであったり料金に関してもユニークですよね。
引き続き、追加で調べる事もあるかと思いますので、まとまり次第こちらで共有させて頂ければと思います。
以上、よろしくお願いします。
【Python】GドライブにSQLiteでお手軽DB構築
こんにちはbudouです!
今回は業務使用も多いと思われるGoogleドライブを使ったデータベースの共有方法を紹介したいと思います。
[ここにGドライブの中に~~.dbファイルがあるキャプション。これがGドライブの中のデータベースと吹き出しを付ける]
はじめに
・スクレイピングしているデータを日々継ぎ足ししながら保存しておきたい
・ER図を描きたいけど、社内のセキュリティの関係で簡単にDBをインストールすることが出来ない
こんな時にはデータベース管理が便利です。
データのチーム共有の方法は以下の方法が一般的かと思います。
- csv(などテキストファイル)にして共有
もともと持っているシステムにテーブルを作って共有
などあるかと思いますが、今回はGドライブ上にSQLiteでデータベースを作って共有 する方法を紹介しようと思います。
<目次>
Google Colaboratoryを開く
今回はやってみると手軽に出来たのでローカルPythonではなく、Google Colaboratoryを使ってのDB構築を試みます。 ※ローカルPythonからDドライブへのアクセスももちろん出来ますが、目的に対してはGoogle Colaboratoryを使った方が早いと思いました
開き方は↓
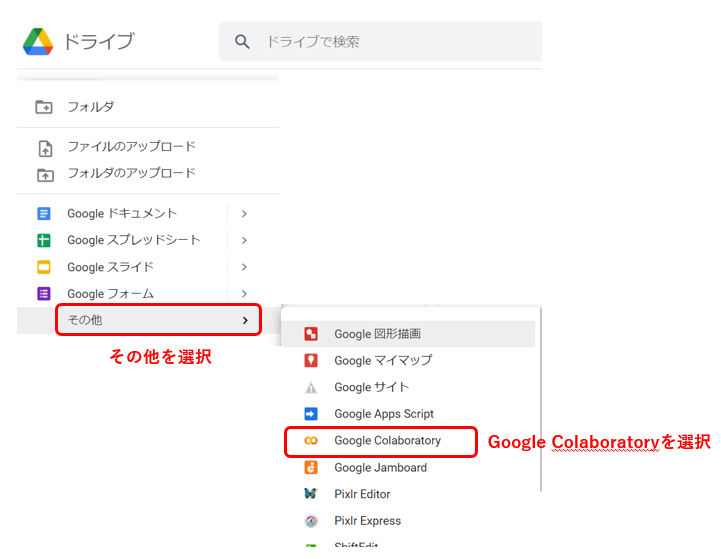
①Gドライブを開く
②その他からGoogle Colaboratoryを選択
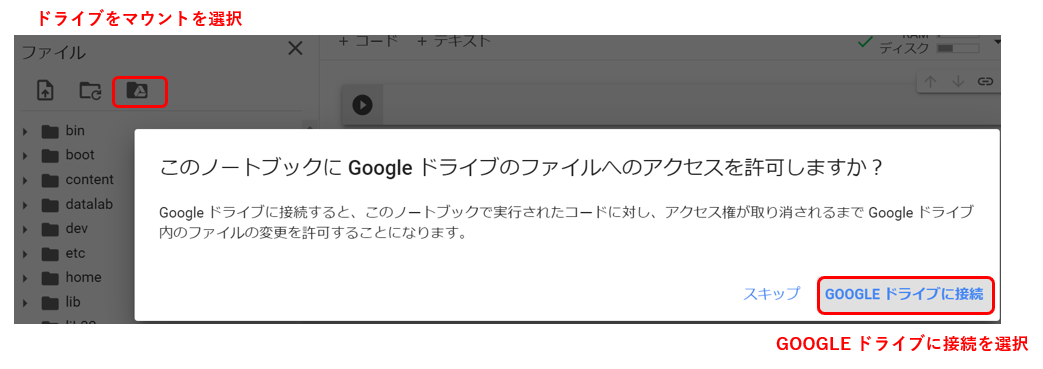
Google ColaboratoryでGドライブをマウントする
Gドライブをマウントします。
マウントの方法は、
①ドライブをマウントを選択
②GOOGLE ドライブに接続を選択

または、下記のコードを貼り付けて実行しても出来ます。
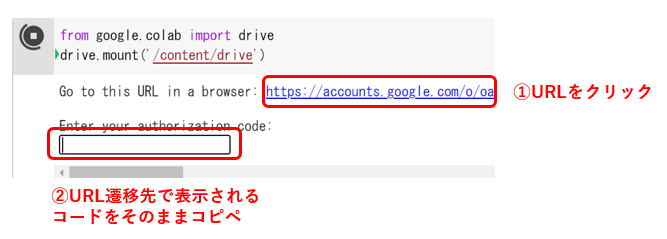
from google.colab import drive drive.mount('/content/drive')
↓その際、認証のためのURLが発行されるので、それに従い認証を行います。
SQLiteを使ってデータベースを作ろう!
これで準備は出来ましたので、DBをGドライブに作っていきましょう。
必要ライブラリのインポート
import sqlite3 from contextlib import closing import pandas as pd
テーブル作成
「氏名」と「年齢」の絡むでテーブルを作ってみます。
create_table = '''create table sample_table (氏名 text, 年齢 integer);''' dbname = "/content/drive/MyDrive/Colab Notebooks/sample_table.db" with closing(sqlite3.connect(dbname)) as conn: c = conn.cursor() c.execute(create_table)
※ハイフン(-)は許されていないようです。 ハイフンを入れると ↓ [OperationalError: near "-": syntax error] のようなエラーが出て失敗します。
SQLiteを使ってデータを入れよう!
データ挿入の基本構文はこちらです。
with closing(sqlite3.connect(dbname)) as conn: conn.execute("insert into sample_table values(?, ?)", ['高橋花子',20]) conn.commit()
SQLiteを使ってデータを抽出しよう!
pandasのDataFrameを使うことが多いのでpd.read_sqlで読みにいきます。
with sqlite3.connect(dbname) as conn: df = pd.read_sql('select * from sample_table', con=conn)

おわりに
今回は業務使用も多いと思われるGドライブにDBを簡単に立てる方法のご紹介でした。 私も手軽にDB使いたいときに利用させてもらってます。
以上、よろしくお願いします。
【Pythonでスクレイピング】ElementClickInterceptedException例外回避の方法
こんにちは!budouです!
今回はPythonでスクレイピングをしているときに実際に詰まった例外エラーとその対処に関して紹介出来ればと思います。
[ElementClickInterceptedException]エラーの原因と対処法に関しての紹介の記事になります。
ElementClickInterceptedExceptionとは
エラーメッセージには下記の様に記されています。
ElementClickInterceptedException: Message: element click intercepted
つまり、このエラーは「Selenium側で操作しようと思ったときに何かに邪魔されて出来ません」ということと解釈できます。
原因(どんな時に出たか)
↓をクリックしたいけど
↓のように「お邪魔オブジェクト」が出てきてクリックできない~
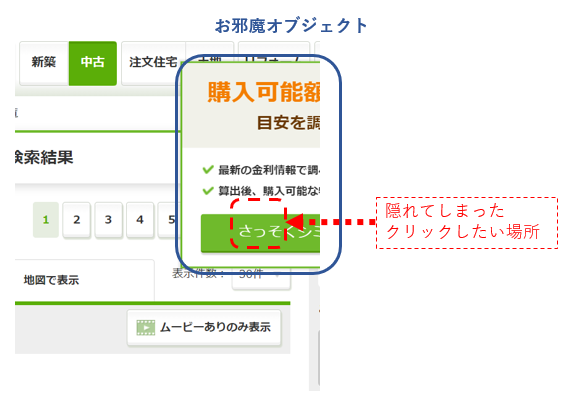
このエラーが出るときは以下のようなケースが考えられます。
・Seleniumでクリックさせたい場所に何か別の「お邪魔オブジェクト」がある。
・クリックさせたいのにクリックする場所が画面外にある。
...今回原因を探っていって「邪魔者があると操作出来ないとかSeleniumも意外に人間みたいなんだな」とかよくわからない感想を持ってしまいました。
実際の対処法
対処法として色々と考えられますが、今回は
- 画面サイズを変えることで(最大化する)「クリックさせたい場所」と「お邪魔オブジェクト」の配置を強制的にずらす
ことでクリック可能にすることで回避しました。
コードは下の一行追加しただけ。(ドライバーのインスタンスを立ち上げた直後やエラーになる直前など、適当な個所に入れ込んで画面を最大化させる)
driver.maximize_window()
おわりに
画面最大化ではなくて、「画面スクロール」などでも同じく回避できそうですよね。
今回のような「お邪魔オブジェクト」をそもそもseleniumに消させることって出来るのでしょうかね。 出来たら楽なのにな~
以上、よろしくお願いします。
コンサル業界の中でデータアナリストの立ち位置をまとめてみた
こんにちはbudouです!
今回は本ブログのタイトルでもあるデータアナリストは実際業務の現場でどのような仕事をしているのか。
というところを自身の例を交えながらご紹介出来たらと思います。

はじめに
データアナリストという職種は、一体どんなのものなのか。 というところを、自身の例を交えながら紹介します! 多分に主観が交じる可能性があることを先にお断り致します、、(;-;)
※尚、定義の問題ではありますがデータサイエンティスト、機械学習エンジニアとしての経験をお持ちの方も本記事の中では同じく語れると考えております。
なので、それぞれデータアナリストから読み替えて読んで頂ければと思います。本記事ではブログタイトルに寄せる意味でも「データアナリスト」という言葉を使っております。
対象とする読者イメージ
データ分析のスキルをコンサル業界で活かしてみたいと思い、コンサル業界への転職を考えている方
データ分析に興味がある新卒でコンサル業界へのエントリーを考えているが、コンサルの中身がどうなっているのか知りたい方
を主な対象としてイメージして書いてます。
メッセージ
この記事を読むと、
データアナリストの活躍の場の一つとして「コンサル」というところも一つの選択肢かも。
コンサル組織の中でデータアナリストは「組織横断的」に必要とされる存在である。
プログラミング未経験からでもコンサルの中でデータ分析者として活躍することが出来る。
というところが少し伝わったら良いな。というところで誰かに勇気を届けることが出来たならそれが一番嬉しいです。
前提整理
先にこの記事を書いている私の経歴など背景を書いておきます。
<小売業界>[3年]
↓ 転職
<半SESの分析業務[3年]
↓ 転職
<分析コンサル歴[2年] ← いまここ
<小売の営業>
モノを直接お客様に販売してました。
徐々に責任のある立場になってくると必然的に経営視点でモノを考えなくてはならず、毎日数字と戦う内に当時吹き荒れていたビックデータのビックウェーブに乗りたくなって転職。(ただのミーハーです...)<半SESの分析会社で分析>
プログラミング完全に未経験(黒い画面コワイ...というレベル)から、楽しくて楽しくて夢中になって仕事しているうちに、 自然言語処理、予測モデル構築、BI開発、アプリ開発、事業のサポートとしてアドホックな分析担当としての常駐案件。などデータ分析として必要な要素をに関してものすごーーく雑多な経験を積む事が出来た。<分析コンサル>
総合ファームのコンサル部隊の中でデータアナリストの肩書を持って色々な案件でお仕事中。
コンサルの中でのデータアナリストの立ち位置
データアナリストが関わる、コンサルの仕事の実際
ざっくりかくとこんな感じです。
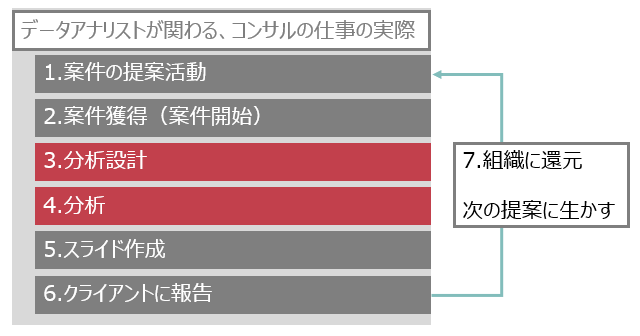
新卒・転職組問わず"必須"スキルとして求められるのは「3.分析設計能力」と「4.分析」能力です。
他はいわゆる"歓迎"スキルです。
あったらプラス1点しといてね。というアレです。(どれだ)
これってむしろスタートアップや大学の研究などで分析されている方ほど経験されている事ではないでしょうか?
おっきな組織だと長らくアシスタントみたいな役回りで分析設計する経験を積むまで時間が掛かりそうな気もしますが、小さい組織ほどこれらの重要なタスクの経験が早く積めそうです。
実際私がそうでした。
コンサル組織の中でデータアナリストは「組織横断的」に必要とされる存在
最近のDXの流れで、大量のデータを使ってどう意思決定するのか。
という案件は増えている印象です。政府が推しているというのも背景にあると思います。
産業界におけるデジタルトランスフォーメーションの推進 (METI/経済産業省)
金融業界でもそうだし、人材業界でもそう。飲食だってそう。どこの業界でも今はDXの流れは顕著です。 そんな中でデータアナリスト活躍中というのがあります。
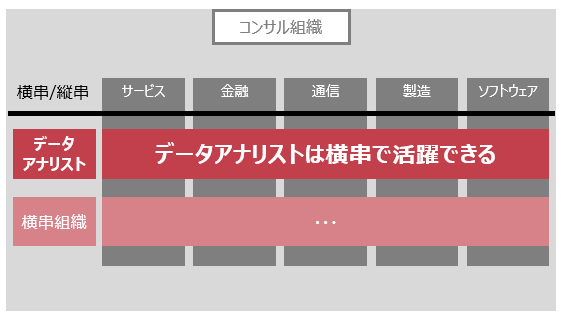
私の所属する組織では、データアナリストスキルのある人材は横ぐしで必要とされていて、案件に応じて必要な部分に配置されます。(以前は各組織にポツポツと存在していた分析スキル持ちが一か所に集まってきている) ※横串にはなりきっておらず、それぞれの領域でお抱え状態というのも聞きますが、現在の潮流を考えると横串で機能させる方が効果が高いのを実感しており、点在状態の組織も徐々に横串化一択と思われる。
実際にある相談としては
などなど、コンサルにくる相談としてはぼんやりしたスタートのものばかりが常ですが、実際は特定のドメイン特化の人と組むのが多いです。
ドメイン特化の方からすると、自身の分析能力だけだと上記のような相談を完全にカバーするのは、データ量的にも技術的にも難しいためデータアナリストの出番!
というわけです。
コンサルのイメージと実際
私はコンサルジョインの前に下記をイメージとして持ってました。
とにかく忙しい
求められる成果物への基準が高い
とにかく忙しい
コンサルというと「とにかく忙しい」というイメージが付きまといますが実際どうなのか...。 少なくとも私のいる総合ファームは...
控えめに言って...「忙しい!」
事業会社でエンジニア的なポジションで分析もされていた方からすると、どうしても「うーん..」というレベルで忙しいのは事実かと思います。残念ながら。
私もまだ2年程度の経験ではありますが、どうしても「クライアント」の期待値を上回るのが仕事。
というのがコンサルなので、プログラムをゴリゴリ書くタイプのデータアナリストと言えど忙しくなるのは事実です。
定時にいつも帰れるコンサルなどが存在するとしたら、それは...
「期待値を超える仕事が常に出来る」かつ「仕事しているアピールがとんでもなく上手い」
という領域に達している領域に達してしまった人なのかと思います。
ほとんどの方は「コンサルは忙しい」というイメージを持たれた上で入社されると思いますので良いですが、ヘッドハンターさんなどに『大丈夫。A社さんはいつも定時に帰れるって言ってますよ!』などと吹き込まれていたら要注意。
相当納得できる説明でなければ信じてはいけません。
求められる成果物への基準が高い
これは忙しさと相まったイメージとして持っていたところですが、とにかく成果物(作成する資料)への要求水準が高いです。
これは実際に直面するまで"理由"は分かっていませんでした。
が、コンサルにとっての成果物は殆どのケースで「パワーポイントで作成したスライド」になります。
そのため、『クライアントの期待値を上回る』が基本にあるコンサルとしてはスライド作成で手を抜くことはあり得ないというわけです。
おわりに
コンサル組織(総合ファーム)におけるデータアナリストの立ち位置に関して書いてみましたが、いかがでしたでしょうか。
もし転職に迷われている方、コンサルで活躍したい!と考えられている方への参考に少しでもなれば幸いです。
ご意見・ご要望などはツイッターのDMで頂けますと嬉しいです。
【Pythonでスクレイピング】法人検索サイトから法人情報を取得
こんにちはbudouです!
今回はPythonを使ったスクレイピングに関して書いていきたいと思います。
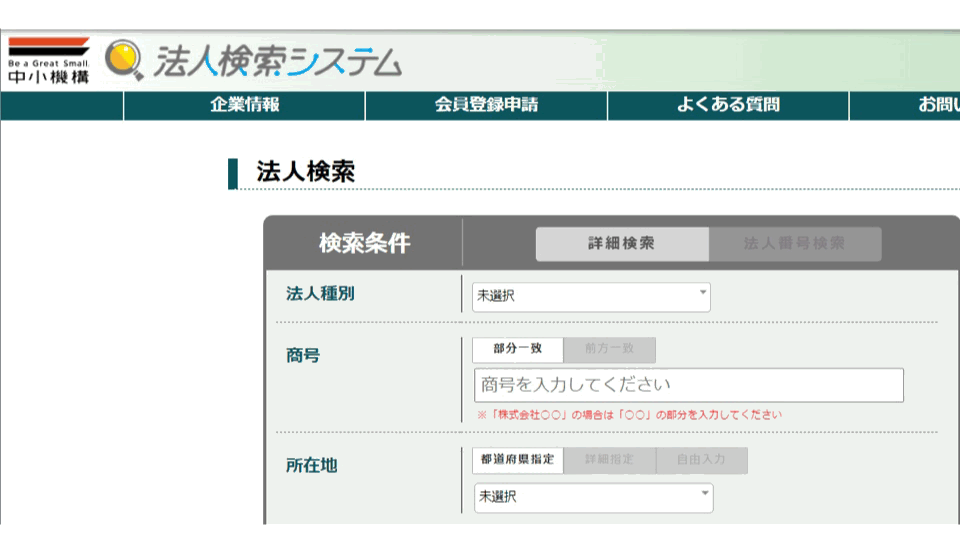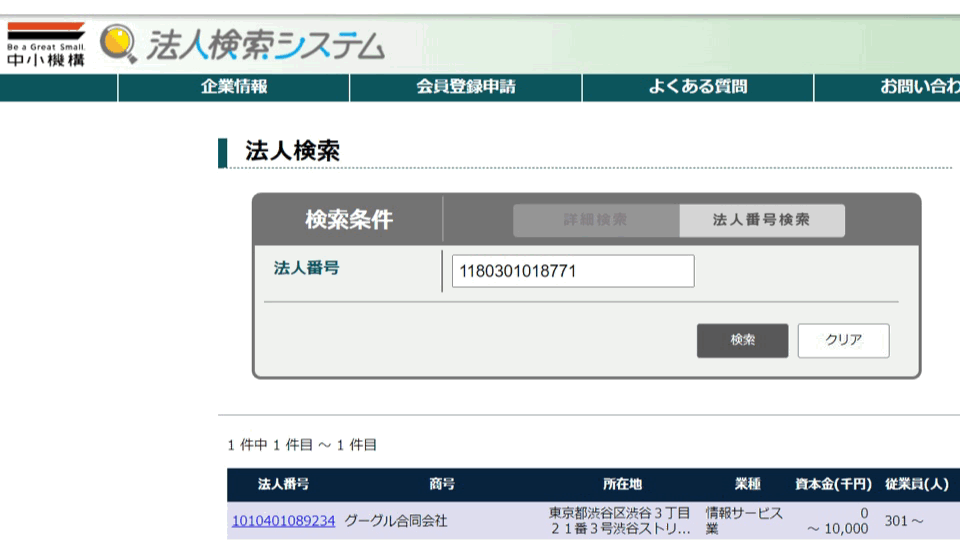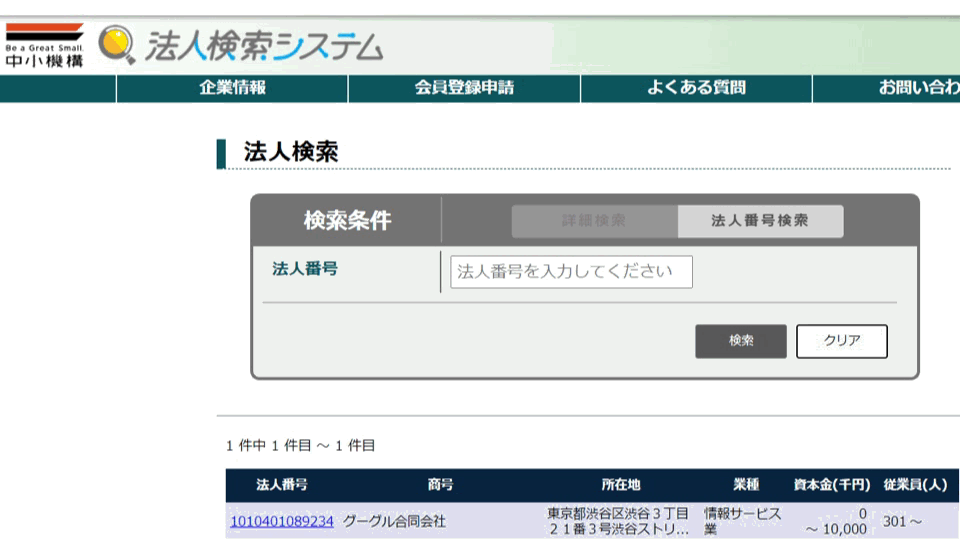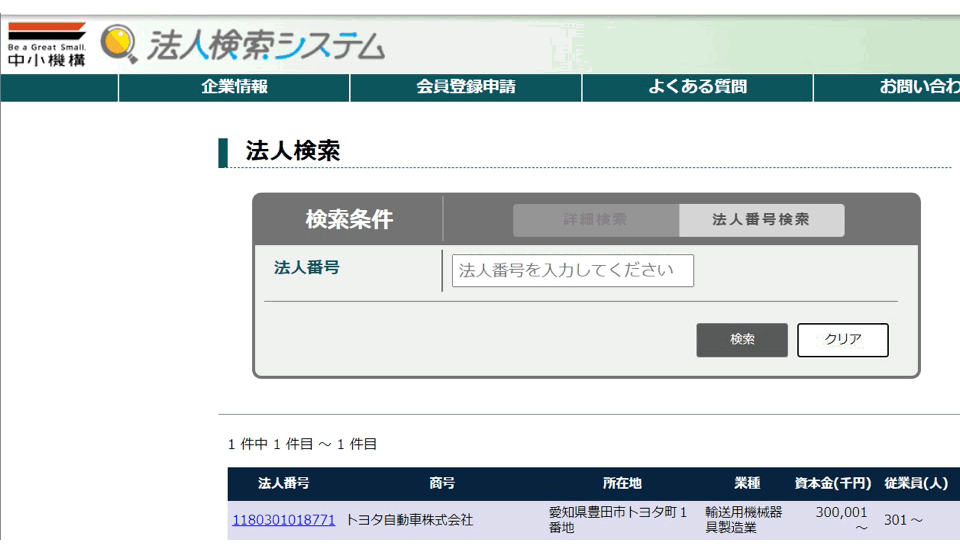
スクレイピングに関しては以前にも何パターンか書いたことがありますが、今回は「法人番号のリスト」から「社名・所在地・業種」を取得したいと思います。
はじめに
実話ですが、下記のようなやり取りがありました。
クライアント)「取引先6000社を業種ごとに分類してデータを見たいよー」
私)「はーい」
... データを見てみたあと
私)え、業種の情報ないぢゃん!人手だけでやるには...1日で終わらないぞこれ...
みたいな事がありスクレイピングして情報を取ってくることに。
そんな時に書いたのが本記事のコードになります。
こちらの「中小機構」のサイトから情報の取得が出来るようになってます。
本記事で使用しているスクレイピングの要素まとめ
この記事では下記のスクレイピング要素を使用してます。 ・ボタンクリック ・入力ボックスに書き出し ・検索実行 ・検索結果
スクレイピング設計
サイトに降り立つ
「法人番号」をクリック
法人番号をインプットボックスに入力して検索
検索結果から必要な情報を抜き出す
インプットボックスの法人番号をクリア
3.→5.を繰り返す。
Pythonコード
input : 法人番号のリスト
output : pandas.DataFrame(法人番号、商号、所在地、業種)
import time from selenium import webdriver import pandas as pd list_ = [] driver = webdriver.Chrome() """1.サイトに降り立つ""" driver.get('https://tdb.smrj.go.jp/corpinfo/corporate/search#o') """2.「法人番号」をクリック""" path1 = "//dl[@class='corp-search-method']/dd/label[@for='searchMethodNum_id']" driver.find_element_by_xpath(path1).click() list_hojin_no = ["1010401089234","1180301018771"] #法人番号のリストを用意する。ここの例では[Google, トヨタ自動車]の法人番号 """3.→5.を繰り返す。""" for hojin_no in list_hojin_no: # 法人番号ごとに下記を繰り返す print(hojin_no) """3.法人番号をインプットボックスに入力して検索""" path2 = "//input[@id='corporateNumber_id']" search_box = driver.find_element_by_xpath(path2) #法人番号入力ボックスを指定 time.sleep(0.5) #0.5秒待つ search_box.send_keys(hojin_no) #法人番号を入力 search_box.submit() #検索実行 """4.検索結果から必要な情報を抜き出す""" path3 = "//table[@id='resultTbl_id']/tbody/tr[2]" search_text = driver.find_element_by_xpath(path3).text #検索結果のテキストを取得 search_words = search_text.split(" ") #結果を半角スペースごとに切り取り... dic = {} #下記で辞書に突っ込んでいく dic["法人番号"] = search_words[0] dic["商号"] = search_words[1] dic["所在地"] = search_words[2] dic["業種"] = search_words[3] time.sleep(0.5) list_.append(dic) #辞書型に整形したものをリスト化 """5.インプットボックスの法人番号をクリア""" path4 = '//*[@id="clear_id"]' clear_bottn = driver.find_element_by_xpath(path4).click() #次の入力をするために法人番号入力ボックスをクリアしておく df = pd.DataFrame(list_)
おわりに
スクレイピングコードの一例としての紹介でした。 スクレイピングの事例として他にも記事を書いてますので、困ったことなどあれば見てみてください。
以上、よろしくお願いします。
オープンデータAPIポータルをPythonで使ってみた(コロナの最新データ)
こんにちはbudouです!
今回は、2020年12月18日に公開されたオープンデータAPIポータルの紹介と、実際にPythonからAPI叩いてみましたのでやり方に関してご紹介したいと思います。
はじめに
「オープンデータAPIポータル」を開設しました | 政府CIOポータル
2020年12月18日に"政府CIOポータル"より、オープンデータAPIポータルがリリースされました。
ここでは、オープンデータの利活用に資する環境構築を目的として、地方自治体が公開しているデータを集約して公開していくそうです。
今回は最初の試みとして、地方公共団体(10団体)が公開している新型コロナウイルス感染症関連のオープンデータを公開された。
との事でしたので、実際に使ってみたAPIの使い勝手などに関してご紹介したいと思います。
サイトにも記載がありましたが、
有効性が確認できれば、ここでの知見を活かし、他の分野・形式のオープンデータも API 化の対象に加えることを検討していきます。
との事ですので、個人的にも信頼できるデータがAPI公開され誰でも利用できる様になるのは大変嬉しい事であり、どんどん使うことで応援したいと考えています。
オープンデータAPIポータルって何?
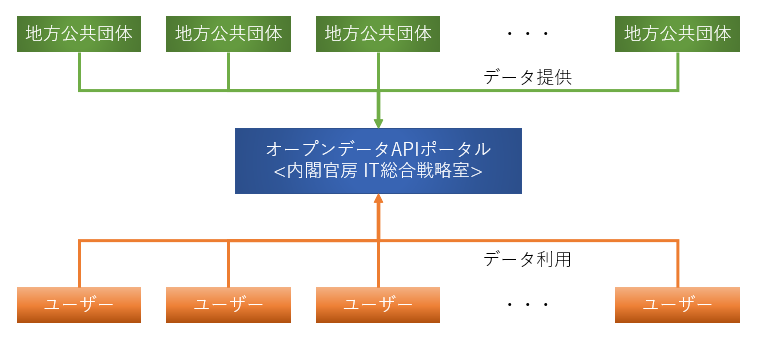
こちらにも記載があるように、「内閣官房 IT総合戦略室」が運営するオープンデータに係るAPIプラットフォームサイト。
のようです。
政府系というところで見ると、e-statsなどが既にあるサービスが思い浮かびますが、オープンデータAPIポータルは地方自治体からの提供データという点が特筆すべき点なのかなと思います。
より細かい粒度が期待出来るということですね。
オープンデータAPIポータルでどんな事が出来るの?
本記事を書いているタイミング(2020年12月21日)では、10の地方自治体からのコロナ関連のデータを取得出来るようです。
尚、現在取得可能な地方自治体は、
<札幌市、会津若松市、群馬県、東京都、神奈川県、横浜市、福井県、三重県、神戸市、福岡市>
となっています。
実際にPythonから使ってみる
基本的には Quick Startページ
に従って登録を進める形で大丈夫です。
下記は実際に手順に従った手順と、留意点を書いています。
ポータルアカウントの作成
「Sign In」 をクリックしてサインイン画面を開きます。
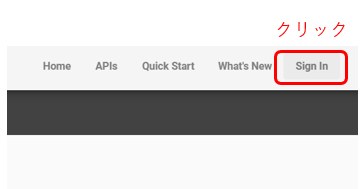
サインイン画面で「Create an account」をクリックします。
必要項目を入力してアカウントを作成します。
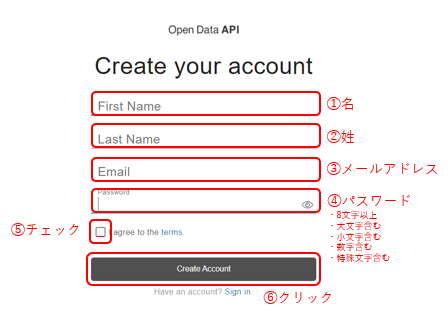
このあと、登録したメールアドレスに確認メールが届きますので、メール内にある認証をクリックします。
ここまでで即アカウントが有効になるわけではないようです!登録したアカウントが実際に認証されるまで少し時間がありました。待っているとそのうち許可されて使えるようになると思いますので、コーヒーでも飲みながら待ちましょう。
アプリ(App)の作成
API Keyを発行してもらうまでのプロセスになります。 サインインした状態から始めます。
NEW APPをクリックします。
アプリ登録(運営にAPI使用の目的を知らせる)をします。
ここで使用するAPIを選択します。
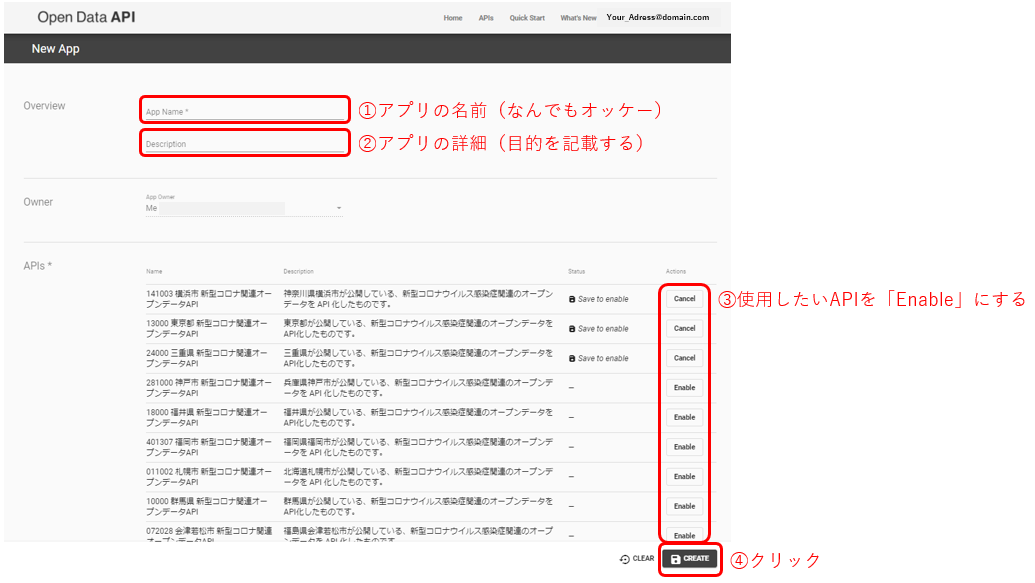
ここまででAPI keyが発行されるので、メモしておく。
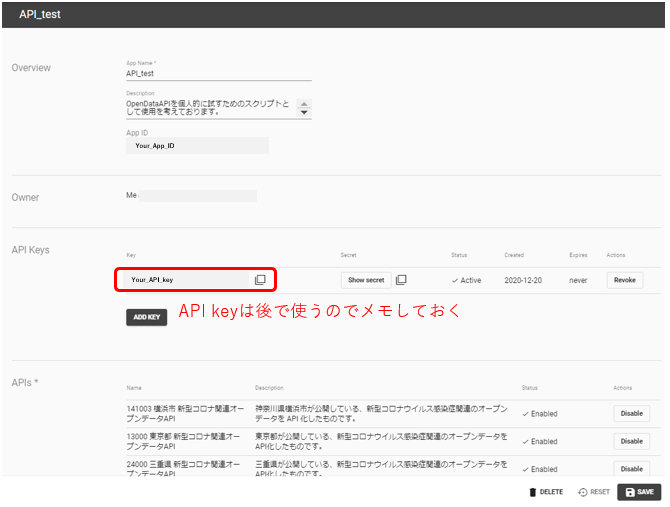
APIを実際に使ってみる
API keyを取得したので、あとはどのAPIを使うのか選んで実際に使ってみたいと思います。
ここでは神奈川県の 新型コロナ関連オープンデータAPIを試しに使ってみたいと思います。
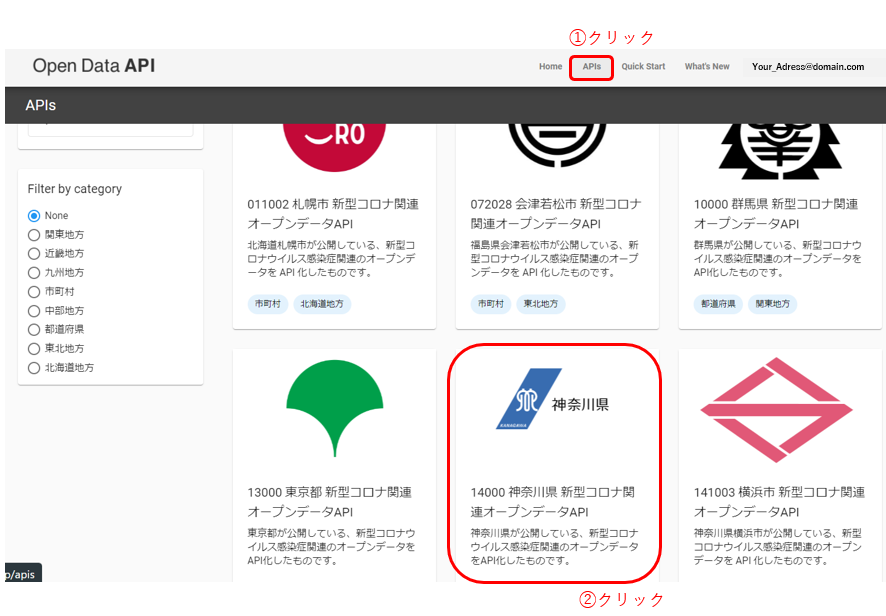
どのAPIを使うのかを選んだら、リクエスト先の情報を取得します。
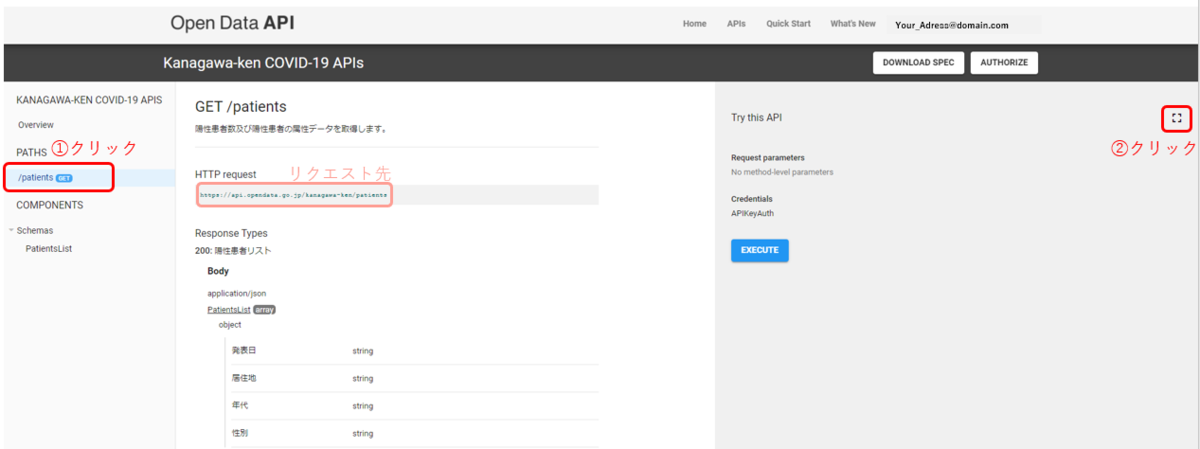
言語ごとにサンプルコードが載っており、そのまま使えるようになってます。
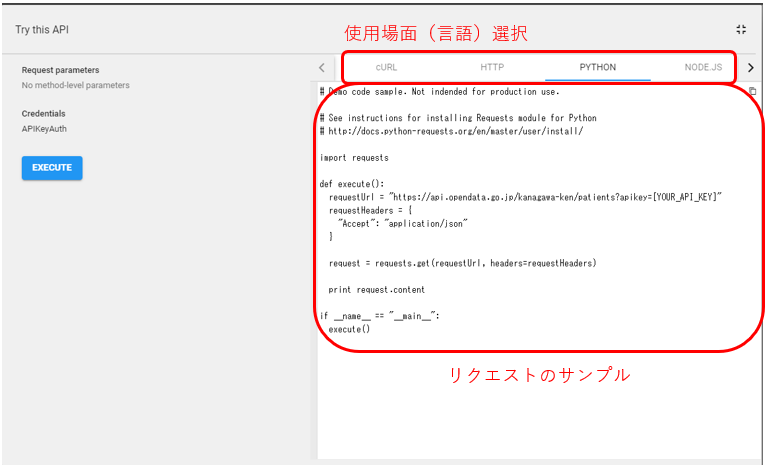
コード
import requests import pandas as pd api_key = "Your_API_key" #前項までで取得したAPI keyを渡す。 #ここ例では"神奈川県の 新型コロナ関連オープンデータAPI"のurlを指定している。 url = "https://api.opendata.go.jp/kanagawa-ken/patients?apikey={}" requestUrl = url.format(api_key) requestHeaders = { "Accept": "application/json" } request = requests.get(requestUrl, headers=requestHeaders) result_json = result_byte.decode() df = pd.read_json(result_json)
これでdfを出力してみると...
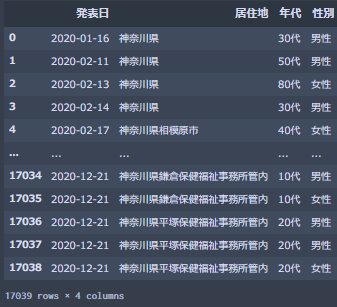
という感じで出来てますね。
おわりに
オープンデータAPIポータルの紹介、それから実際にPythonからAPI叩いてみたのでプロセスとコード、それから結果に関して紹介しました。
今回のオープンデータAPIですが、お題目の通りやはり地方自治体で所持しているデータを一元管理して誰でも利用できるように整えて公開している。というところが大きな価値だと思います。
また、「政府系のIT関連って面倒ばかりでなかなか利用しにくいのでは...」という先行イメージがありましたが、実際に使ってみたところ全くそのようなことはなく、逆にとても分かりやすい仕様になっていると思います。
まだオープンしたばかりということでコロナの情報だけですが、今後使えるAPI(情報)が増えていく事を期待したいです。
研究にももちろんビジネスにも活躍の場があるものになると思いますので、今後も使うことで応援できたらと思います。
【Tableauでガントチャート】を作る方法をわかりやすく解説!
こんにちはbudouです!
今回はタブローを使って、ガントチャートを作ってみたいと思います。
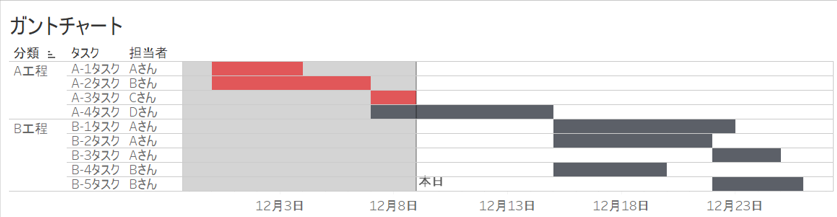
↑これを作りたいです。
はじめに
今でもプロジェクトの全体像を俯瞰するために使われるガントチャート。
エクセルで作ることも出来ますし、プロジェクト管理ツールなんかでもよく出てきます。そんなガントチャートをTableauで作ってみたら超簡単でしたのでご紹介出来ればと思います。
結論、必要なことは、
・列に日付ディメンションを入れて行に表示したいディメンションを入れる
・予定開始日と予定終了日の差を作成し、マークのサイズに入れる
・味付け
です。
今回用意したサンプルデータ
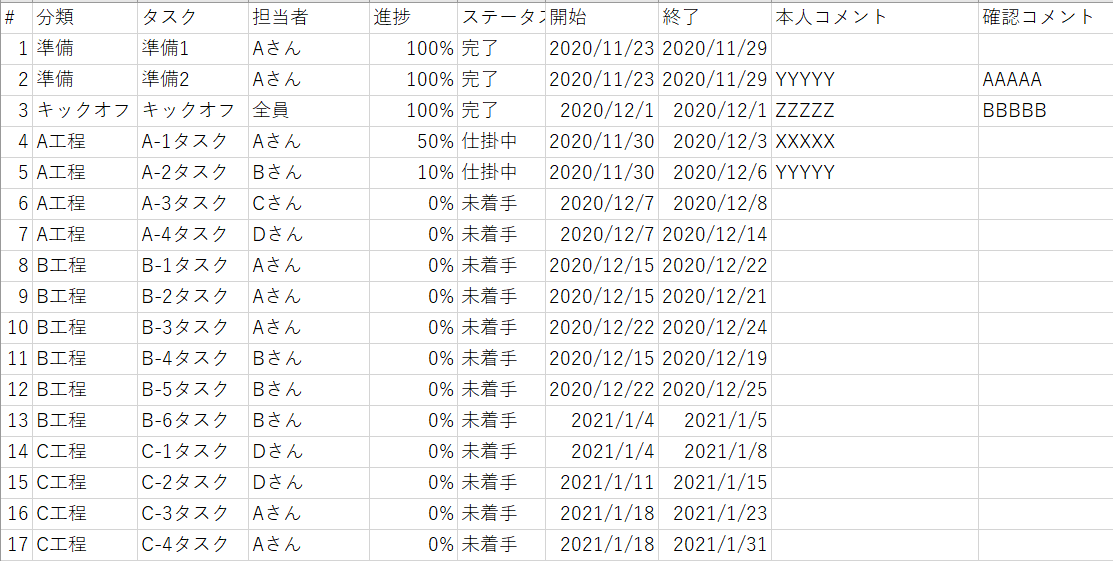
こんな感じのサンプルデータを用意しました。
よくある感じのWBSです。
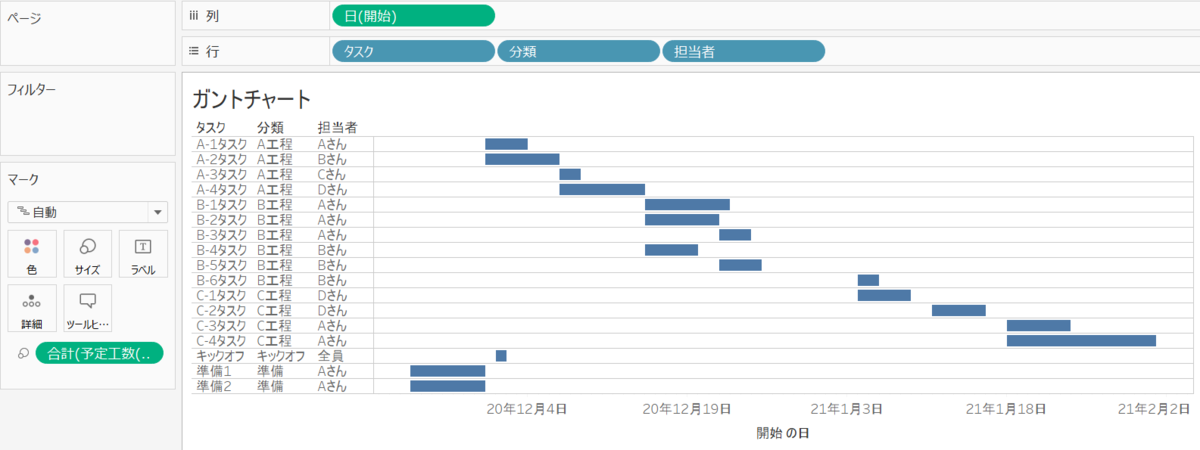
列に日付ディメンションを入れて行に表示したいディメンションを入れる
「開始」を列へ、
「タスク」「分類」「担当者」を行へ、それぞれドラック&ドロップで選択します。
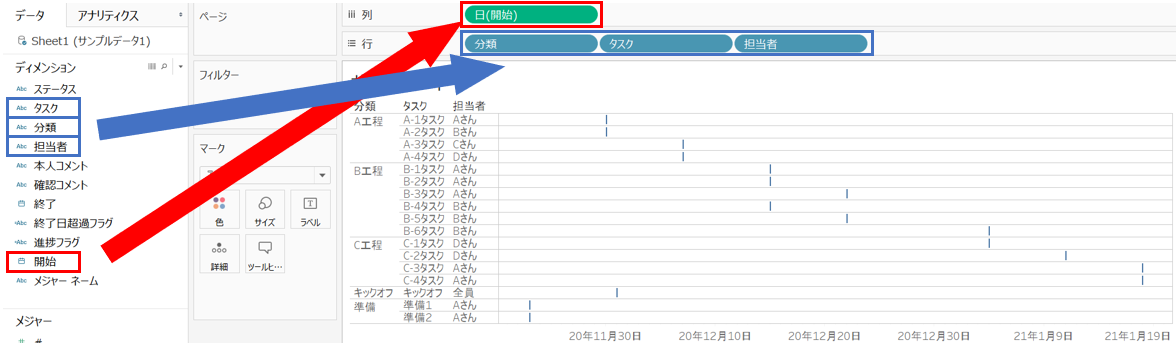
予定開始日と予定終了日の差を作成し、マークのサイズに入れる
開始日と終了日の日付の差を作成します。

DATEDIFF("day", [開始], [終了]) + 1
1を足しているのは、1/1~1/7を"1週間"としたい(7 -1 + 1 = 7日としたい)のとここでは同じです。
ここまででみてみると...
何とな~くガントチャートっぽくなりましたね!!
ここまで出来たらあとは良しなに改善を~というところですが、使えそうな味付けアイデアを追加でご紹介させて頂ければと思います。
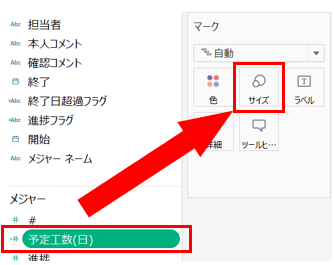
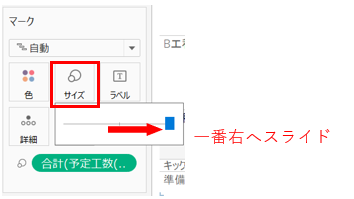
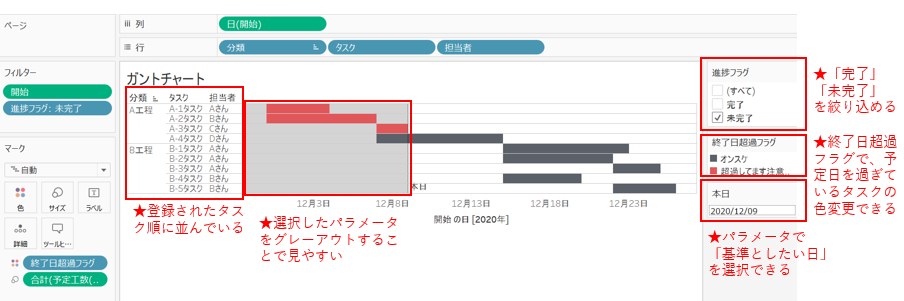
味付け
作ったフィールドを「サイズ」にドロップします。
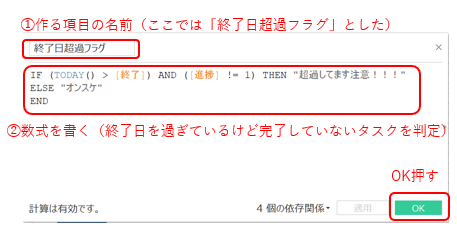
IF (TODAY() > [終了]) AND ([進捗] != 1)
THEN "超過してます注意!!!" ELSE "オンスケ"
END
「超過フラグ」を作成します。
(進捗を見て、「終了日を過ぎている」かつ「進捗が100%ではない」ところの判別をしています。)
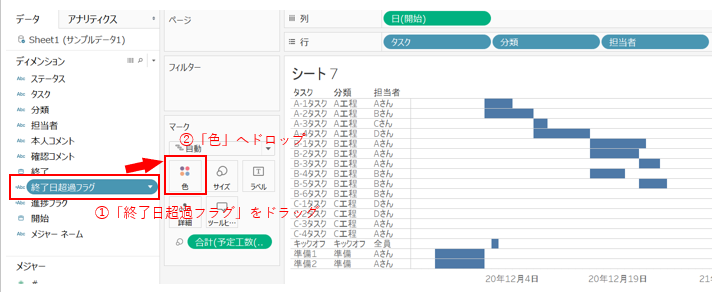
作成した「超過フラグ」を「色」にドロップします。
「日(開始)」をフィルターにつかい、表示される項目を絞り込みます。
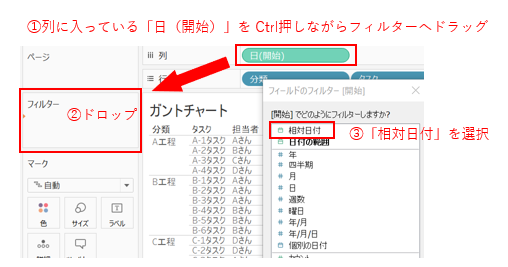
例えば1年前のものが表示されていても使いにくいので、直近のものだけ表示させるようにするためです。
今回は四半期分だけ表示されていればオッケーとします。
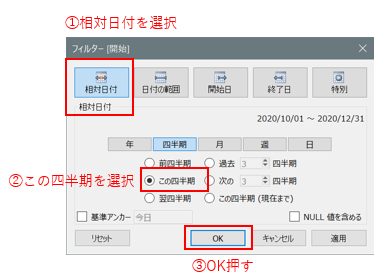
相対日付で表示されるようになりました。
次に、リファレンスラインを追加して、もっと見やすく整えていきたいと思います。
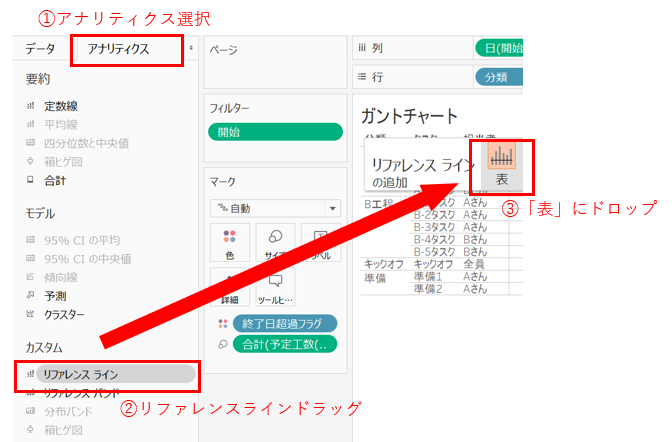
これにリファレンスラインの基準日を設定してあげて、
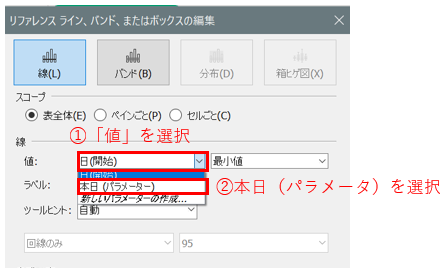
下を塗りつぶし設定して、
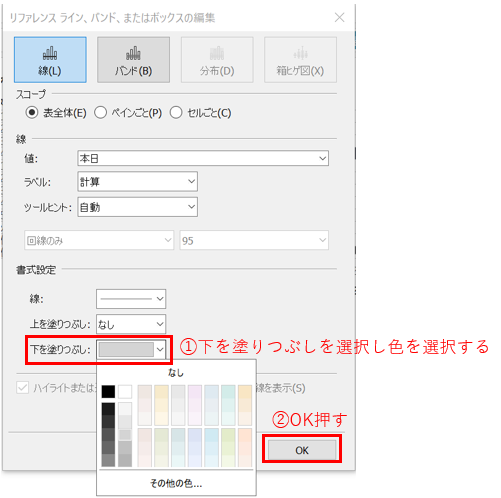
パラメーターコントロールを表示して選択できるようにしてあげると、↓のような感じで出来てきます。
もう結構きれいで使えそうな感じになりましたね。
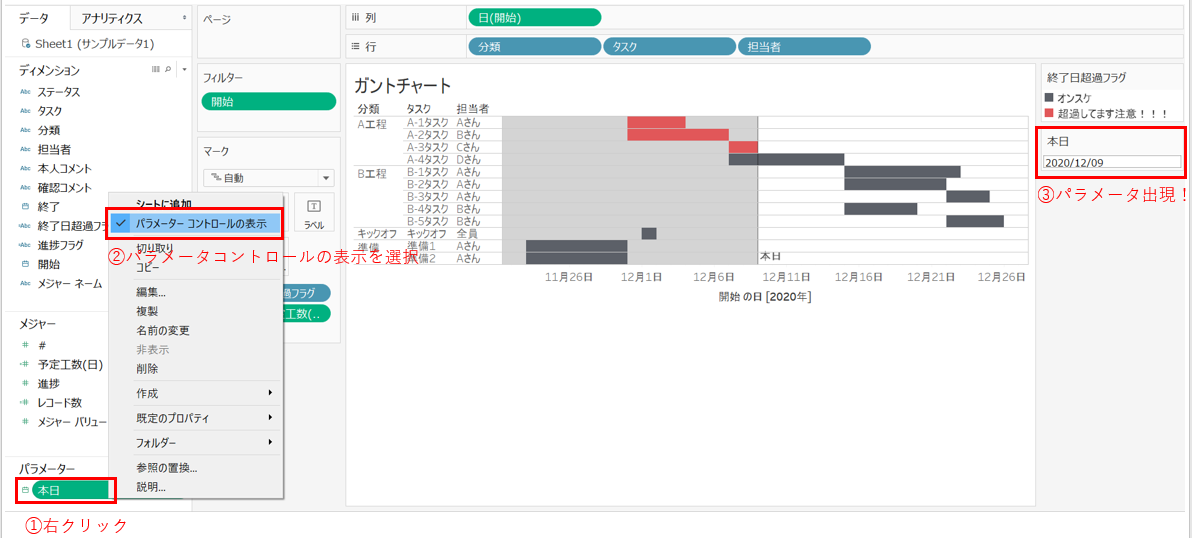
あともう少し、表示されている並び順を何とかしたいです。今の並びはなんだか意図しているものと違います。本当はタスクを作った順番(今回は開始日順と同じ並び)にしたい!
並び替えの際は、「並び替えをさせたい項目」に対して設定を行います。特に表の場合は"一番左側に設定した親項目"さえ並び替えられれば子はその順番に従います。
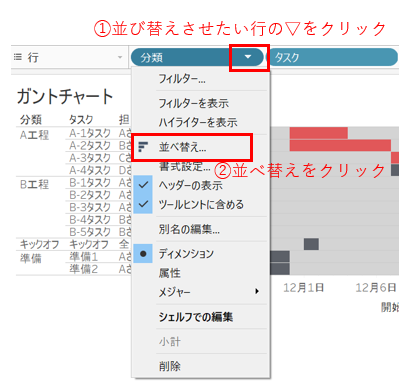
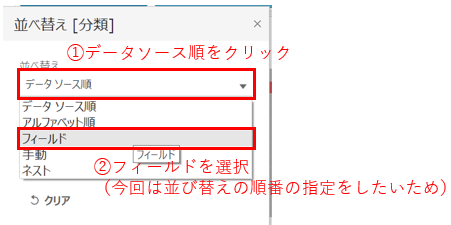
続けて、
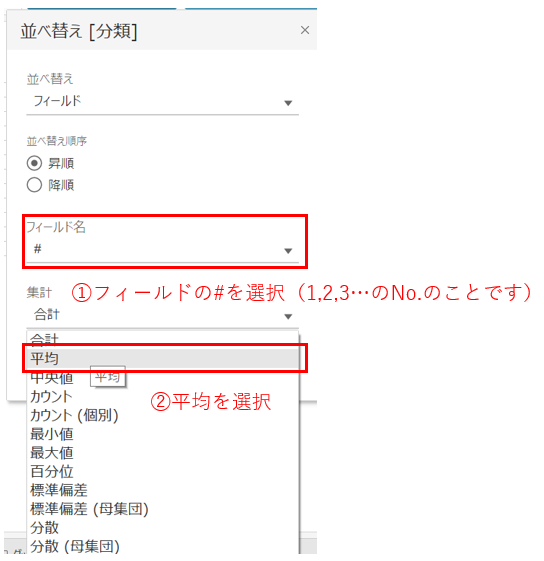
これで並び替えは出来ているので、続けて「進捗フラグ」を作成し、「完了したタスク」を表示するかしないか選択できるようにしたいと思います。
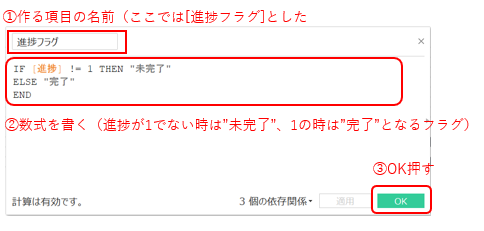
IF [進捗] != 1 THEN "未完了"
ELSE "完了"
END
進捗が1(100%)になっていないものを”未完了"とし、1(100%)になっているものを"完了"とします。
最後に、作成した「進捗フラグ」をフィルターに入れて終わり。
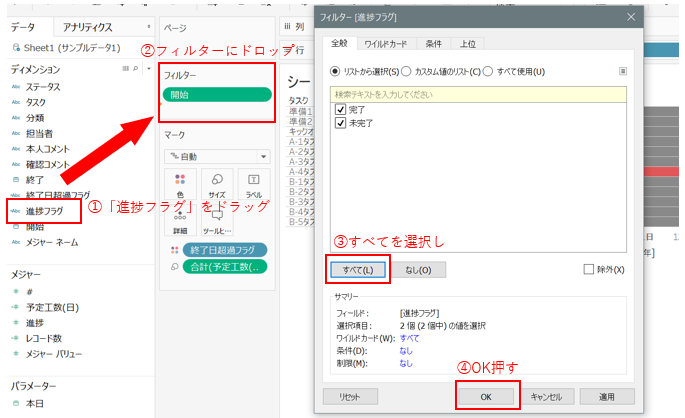
できた~
おわりに
よく使うガントチャートをタブローで表現してみました。 実際にタブローを業務に取り入れられているところは最近増えてきていると思いますので、「一か所管理」の意味でも、タブローガントチャートで進捗管理してみるのもありなのではないでしょうか。
Gスプレッドシートなどでデータは管理してチャートを最新にした上で、作ったvizをそのままストーリーに組み込んだり(進捗管理なので頭の方に持ってきたり)みたいな使い方が出来そうです!
以上、よろしくお願いします。
【Tableau使い方】複数メジャーをグラフ化
こんにちはbudouです!
今回はタブローを使って5秒で「複数メジャーをグラフ化する」方法に関して書いていきたいと思います。
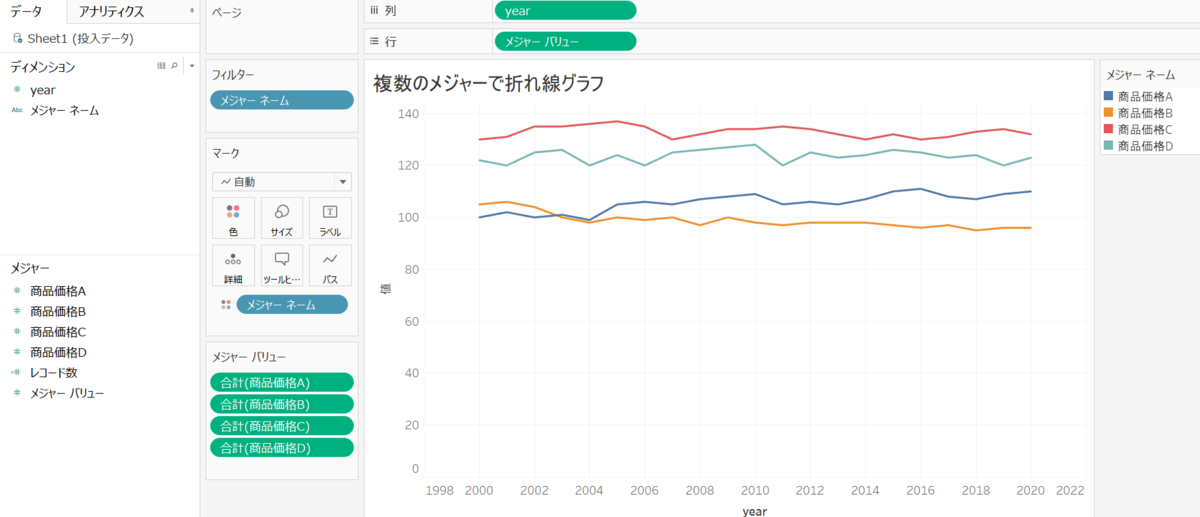
↑これを作りたいです。
やり方を知らないと、↓のようになってしまうと思います。
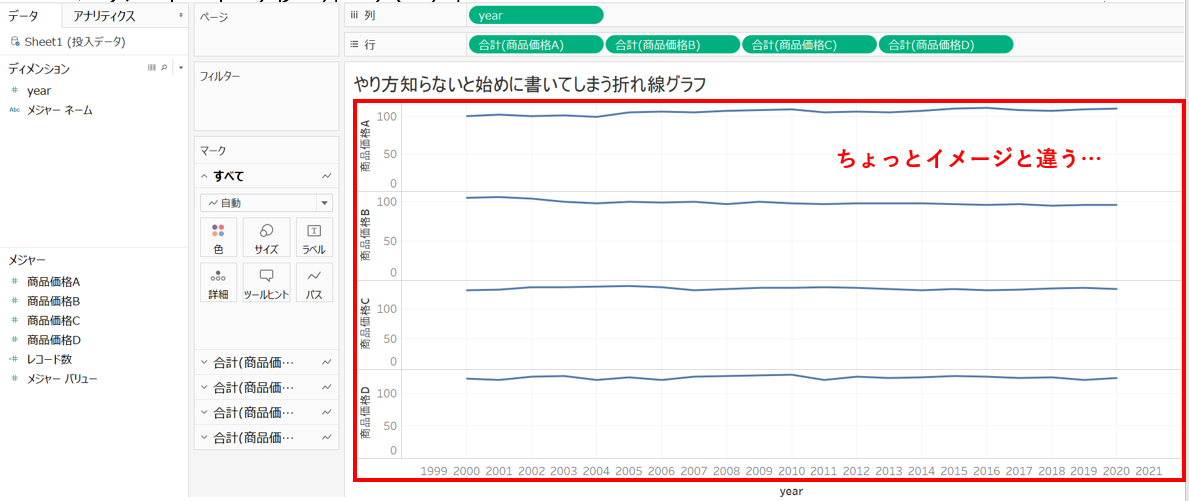
はじめに
「商品A、商品B、商品Cの価格を合わせて見たい(もしくはもっと多くの)」
「3つ以上の軸を使って可視化したい」
と思ったりすることが良くあるかと思います。 ところが、タブローにもちょっと癖があって、 以前3つ以上のカラム(メジャー)を一つのグラフに納めたいのに出来ない!と困ることがありました。
そんなときどうするか?というところで一つの解決策をお伝え出来たらと思います。
知っていれば5秒くらいで出来ます。 必要なことは、
・一つのメジャーで見たいグラフを作る
・追加したいメジャーをy軸に落とす
です。
一つのメジャーで見たいグラフを作る
今回よくあるケースとして、「複数のカラムがあるときにどうやって一つのグラフに納める?」となるケースとして、 「年度単位の価格の推移を折れ線グラフで」を見るケースをご紹介します。
サンプルとして下記のようなデータを用意しました。
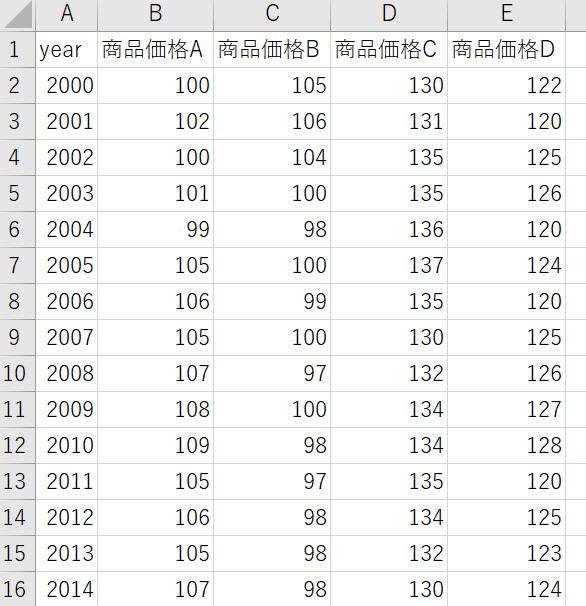
このデータの一つのメジャーを使ってまず折れ線グラフを描きます。
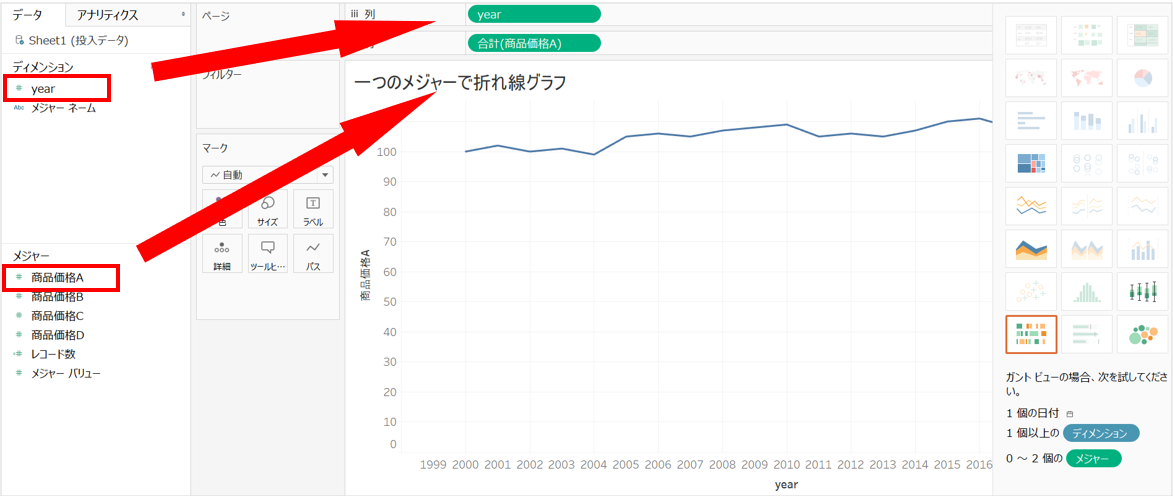
追加したいメジャーをy軸に落とす
次に、同じグラフに追加したいグラフをy軸に落とします。
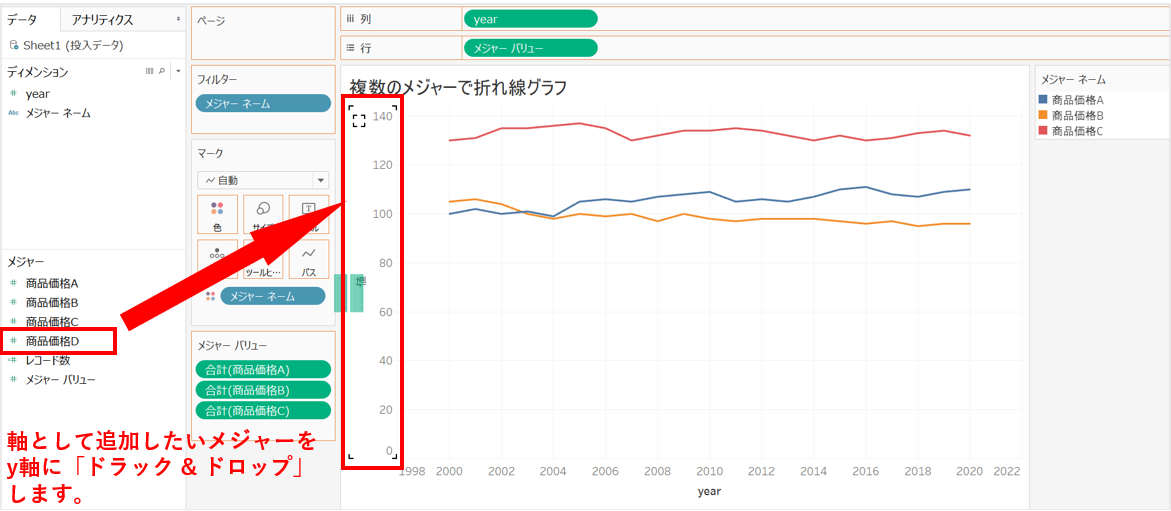
これをしていくと...
完成しました!
同じ方法で棒グラフなどでの複数軸の追加を行うことが出来ます!
おわりに
「複数メジャーをグラフ化する」方法の紹介をさせて頂きました。 知っていれば5秒。 知らないと延々と出来なくて苦しむ... というところで僕も苦しんだことがありました。。
Tableauユーザーの助けに少しでも慣れれば幸いです。
以上、よろしくお願いします。
【Twitter分析】ハニーレモンソーダの話題を分析してみた!
こんにちはbudouです!
今回はTwitter分析の一例をご紹介したいと思います。
はじめに
未だにこんな会話からお仕事が始まることがあります。。

その時は、特定の条件でツイートを集めてきて、絵にかいてみるのをお勧めします。 何よりも早いですし直感的に分かりやすいです。
今回はその一例として、 「トレンド入りした話題ではどんなツイートが多いのか?」という観点で実際に見てみたいと思います。
ということで、先日トレンド入りしていたハニーレモンソーダのツイートを集めて分析してみました。 トレンド入りしていた際はどのような話題で盛り上がっていたのでしょうか??
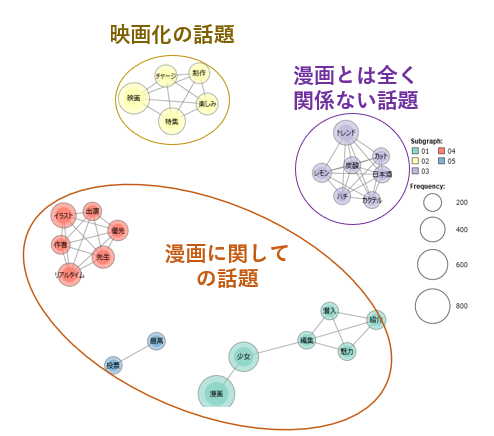
結論、
・映画化の話題
・漫画の話題
・漫画とは全く関係ない話題
に分かれていることが見えました。
個人的には「漫画に関係ない」で盛り上がっているのが面白かったですw
ハニーレモンソーダのトレンドイン!
ハニーレモンソーダは、『りぼん』より2016年から連載されている人気漫画で、今回映画化が決まって話題になっている作品です。
トレンドインしていたとき。
データ収集のルール
ツイートの中に「ハニーレモン」「ハニレモ」を含むツイートを回収
データ収集の期間と件数
検証期間:2020/11/4 12:00 ~ 2020/11/6 12:00 の2日間
件数:4195件 でした。
どんな単語がツイートに含まれているのかを見てみよう
今回は、回収した4195件のツイート対して、共起ネットワーク図を描いて可視化してみました。 その上で結果を見てみると、
・「映画化の話題」でリツイート飛びまくるグループ
・「漫画の話題」で盛り上がるグループ
・「漫画とは全く関係ない話題」が行きかうグループ
と3つのグループに分かれていました。
このように見てみると、どんな話題に関してツイートが盛り上がったのかが分かりやすく見ることが出来ますね。 *1
どんなリツイートが多かった?
さらに、この中で「リツイート」の割合はどうだったかというと...
リツイートが多かったツイートは、
「映画化の話題」
みなさん #今夜くらべてみました 📺#りぼん 特集🎀で公式もときめきチャージしました🥰
— 映画『ハニーレモンソーダ』公式 (@honeylemon_eiga) 2020年11月4日
映画 #ハニレモ 🍋も来年の夏に向けて制作中です🎬💪🏻
お楽しみに🍹✨#ハニーレモンソーダ
「漫画の話題」
【村田真優先生描き下ろしイラスト!】
— 今夜くらべてみました(日本テレビ) (@ntvkonkurabe) 2020年11月4日
「 #ハニーレモンソーダ 」の作者 #村田真優 先生が、出演者のイラストを描いてくれました♪
▼スマホでもリアルタイムで見れますよ♪https://t.co/3uIJBdWsHR#りぼん @ribon60th#今夜くらべてみました pic.twitter.com/rcxmYYa8Re
「漫画とは全く関係ない話題」
こちらはトレンド入りしていないほうの "ハニーレモンソーダ" です。酒カクテルです。日本酒60ml、ハチミツ10g、炭酸30ml、カットレモンで幸せになれます。 pic.twitter.com/s07jwYMEJM
— お酒ならKURAND (@KURAND_INFO) 2020年11月4日
おわりに
以上、Twitter分析の一例として、共起ネットワークを用いて特定のツイートの中の「話題」を可視化してみる。 ということをやってみました。
社内で「自社のTwitter分析してみて」などと言われてしまい、 「どうやろうかな」と悩まれている方などの参考になりますと幸いです。
参考
今回共起ネットワークを描くのに利用させて頂きましたツールはKHコーダーです。
下記のサイトなどをご覧いただけますと分かりやすいです。
テキストマイニングはKH Coderがおすすめ! - 統計ER
*1:ここでの共起ネットワークは「一つのツイートの中で一緒に登場する単語は何か」を分かりやすく可視化したもので、線で繋がっている単語同士が一つのツイートの中で一緒に出てきたものとして表現されてます。
【Twiiter分析】竹花貴騎詐欺事件に関してTwitterの炎上分析してみた
こんにちはbudouです!
今回は最近Twitterで話題になった「あの」問題に関してデータの視点で見てみたいと思います!!

はじめに
Twitterで詐欺事件として話題になった「竹花貴騎さん」ですが、色々と話題になった中でTTMつよしさんがご自身YouTube↓↓
まだ話したい「竹花貴騎経歴詐称の擁護派はやばい」って思う理由
こちらの(5:00辺りから)中で、
「竹花擁護派」は結果を出していなさそうな人(影響力が少ない?)
という事を仰っていたので、こちらを実際のTwitterを見ながら深掘りしていけたらと思います!
結論:実は 「竹花援護派」は「竹花否定派」よりも、影響力が少ない人の集まりだった!
目次
分析を行う上での前提
検証期間:2020/10/31~2020/11/1の二日間
竹花擁護派:ツイートの内容をネガポジ分類した上でポジティブな意見が多い人を擁護派と今回は定義した
竹花否定派:竹花擁護は以外の人を竹花否定派として定義した
結果を出している事:フォロワー数で判断
データ収集
データ収集のルール
ツイートの中に下記5つの単語どれか一つでも含まれているものを今回の解析の対象とした。
- "竹花"
- "竹花貴騎"
- "MUP"
- "MUPカレッジ"
- "竹花財団"
データ収集の期間
2020/10/31~2020/11/1の2日間
※「2日間」に意味はありません。もっと過去から集めたかったのですが、収集慣れてなくて今回二日間になっちゃいました。次にやるときはもう少し長めに取れたらと思います。
結果として、5343件のツイートを集めることが出来ました。

データ前処理
データ前処理1.今回のテーマに対して不要なツイートを削除
アカウント名にmupと入っていて「竹花問題と無関係のツイート」を削除
単純にRTだけしているツイートを削除
データ前処理2.ユーザー単位にネガティブな事を多くツイートしている人と、ポジティブな事をツイートしている人を分ける。
今回は、ネガポジ分類を楽に出来るようにして下さったこちらosetiを利用させて頂きました。
上手く出来るかどうか不安だったのですが...
・動画が非公開になってた。ぴえん。
・熱く語る姿は魂を揺さぶられます!引き続き学びの場を提供してください!
・今はしんどいかもですが、頑張ってほしいです。
取れてる取れてる*1 (* ̄m ̄)ムフフフ
でも見た感じの所感として、60..70%くらいしか擁護派の意見はちゃんと取れてないかな。(否定派の意見も交じっている)という感じでした。ツイートの分類難しい..。
データ前処理3.大型インフルエンサーを除く
今回は「フォロワー数が多い」をTTMつよしさんの言われている"結果を出している事"としたいと思いますので、スーパーインフルエンサーを除く。群衆を乱す5000人以上フォロワーがついている人を群衆と一緒に混ぜると色々と乱されてしまうので...除外!
ここまでで最終的に、
否定派:682人
擁護派:166人
と分けることが出来ました。*2

結果.「竹花擁護派」「竹花否定派」においてフォロワー数に違いはあるのか?
ここまでで2つのグループの整理が出来ました。
この二つのグループ間のフォロワー数において、違いがあるのか?というの統計検定を用いて見てみたいと思います。
・
・
・
(結論先に書いてるのでもったいぶる意味はないか。。)
t値:2.056
P値:0.040
ということで、5%水準で見たときに統計的に有意に差がある。ということが言えそうです。
※t値、P値の説明はこの辺をご参照ください。
おわりに
「竹花問題」として炎上案件となった本件に対してYouTubeサーフィンしているときに面白いなと思ったTTMつよしさんが仰っていた、
「竹花擁護派」は結果を出していなさそうな人
「竹花否定派」は結果を出していそうな人
に関して少しだけ深掘りしてみましたが如何でしたでしょうか。
結論として、本件擁護している人は、比較的影響力の少ない人(フォロワー数少ない人)が多そうだ。 ということが見えて面白かったです。