機械学習_基礎と課題
- 特徴抽出
- 特徴選択
- 性能指標
- 混同行列
- 線形回帰
- ロジスティック回帰
- バッチ学習
- 過学習
- ハイパーパラメータの探索
- パラメータの最適化
- 検証集合
- 正則化(Regularization)
- Dropout(2014年)
- 荷重減衰(Weight decay)
- 正則化(Normalization)
特徴抽出
次元削減の一種で、分類に必要な特徴量を抽出することが可能であり、特徴はベクトルとして表現される.
特徴選択
学習に使用される説明変数を選択することを特徴選択という.
フィルタ法
相関係数で重要が高い特徴量を選択する.
ラッパー法
すべての説明変数を使って線形回帰を学習し、各変数の重要度を算出して、重要度が小さい説明変数を除いて、線形回帰を繰り返して学習して特徴量を選択する.
埋め込み法
線形回帰の損失関数にL1ノルム正則項を入れたアルゴリズムで学習して特徴量を選択する.
性能指標
活性化関数
- Sigmoid関数
def sigmoid(x): return 1.0 / (1.0 + np.exp(-x))
その関数の微分:
class Sigmoid: def __init__(self): self.out = None def forward(self, x): out = sigmoid(x) self.out = out return out def backward(self, dout): dx = dout * (1.0 - self.out) * self.out return dx
- Softmax関数

Softmax関数は、入力ベクトルの要素間の差にのみ依存する関数である.
オーバーフロー対策のため、
その関数の微分:

class Softmax: def __init__(self): self.params, self.grads = [], [] self.out = None def forward(self, x): self.out = softmax(x) return self.out def backward(self, out): dx = self.out*out sumdx = np.sum(dx, axis=1, keepdim=True) dx -= self.out*sumdx return dx def softmax(x): if x.ndim == 2: x = x - x.max(axis=1, keepdims=True) x = np.exp(x) x /= x.sum(axis=1, keepdims=True) elif x.dim == 1: x = x - np.max(x) x= np.exp(x) / np.sum(np.exp(x)) return x
混同行列
| 混同行列 | 予測Positive | 予測Negative |
|---|---|---|
| 正解_Positive | TP個 | FN個 |
| 正解_Negative | FP個 | TN個 |
Precision
Positiveと予測したもので実際Positiveであった割合.
Precision= TP/(TP+FP)
Recall
実際Positiveであるもの中で、どれぐらいPositiveが予測されるかという割合.
Recall = TP/(TP+FN)
F-measure
(2*Recall*Precision)/ (Recall + Precision)
物体検知アルゴリズムにおいて「任意のPredictied BBに検出されないGround-Truth BB」は、False Negativeである.
線形回帰
ロジスティック回帰
バッチ学習
①ミニバッチ学習との違い
- バッチ学習では、パラメータ初期値を決定的にもしくは確率的に定めた後、同じデータを繰り返しモデルに投入し学習させる.-> 目的関数はわからない.
- ミニバッチ学習では、エポック毎にミニバッチ内のデータを変更するため、イテレーションのたびに異なる目的関数を最適化する.
- >目的関数がイテレーションのたびに変わる.局所的な最小解にトラップされた場合でも、次のイテレーションで異なる目的関数の最適化のため、局所的最小解から抜け出せる可能性がある.
そのため、ミニバッチ学習は局所的最小解を必ず脱するとは限らないが、バッチ学習は大局的最小解に辿り着いくは限らない。
ミニバッチ学習やバッチ学習では、重みの更新が安定するため、比較的に大きな学習係数を設定できる.
→バッチサイズが小さいミニバッチ学習よりも比較的短い時間で学習を収束させる.
ハイパーパラメータの探索
パラメータの最適化を行う前にハイパーパラメータを決めなければならない変数である.(NNの層数や正則化のパラメータ)
- グリッドサーチ:ハイパラ毎に候補点設定、そのすべての組み合わせを探索する.
- ランダムサーチ:グリッドサーチより少ない探索回数でよい性能を示す点を見つかる.
- ベイズ最適化:
予測モデル(ガウス過程回帰)を構築し、獲得関数を用いて次の探索点を選択する.
なるべく少ない回数でより良い解を見つけたい場合に向いている手法で、ガウス過程回帰はベイズ推論手法であるため、ベイズ最適化と呼ばれる.
実験条件の探索として使われる.
パラメータの最適化
分かりやすい動画:GitHub - Jaewan-Yun/optimizer-visualization: Visualize Tensorflow's optimizers.
線形回帰のパラメータ最適化が凸最適化問題と考えられる場合、適切な条件で勾配法を用いれば、目的関数が最小になるパラメータを見つかること.(目的関数がパラメータによって微分可能であること)
確率的勾配降下法(SGD)
特徴:無作為に選びだされたデータ を用いて、目的関数が最小となるパラメータを勾配法によって探すことをSGDという.
課題:SGDの非効率な探索経路による.それは勾配の方向が本来の最小値ではない方向を指しているため.(それを解決するため、Momentumの導入)
パラメータθの更新式:
サンプルコード:
param[key] -= self.lr * grad[key] #lr: 学習率
例題:
| X | Y |
|---|---|
| -1.0 | 0.0 |
| 0 | 0.5 |
| 2.0 | 1.5 |
二乗和誤差:
1回目更新量:
(a, b) = (1.0 , 0 ) #初期値 lr = 0.1 # 学習率 learning rate (x, y) = (-1.0, 0.0) dL_da = lambda a, b: a * x * x + b * x - x * y dL_db = lambda a, b: b + a * x - y # (a, b)を1回更新する更新量を(da, db)とする da = -lr * dL_da(a, b) db = -lr * dL_db(a, b) print(da, db)# 答えを表示
2回目更新量:
(a, b) = (-0.1 , 0.1 ) #初期値 lr = 0.1 # 学習率 learning rate (x, y) = (0.0, 0.5) # 問題文における偏微分の定義で n = 1 とする dL_da = lambda a, b: a * x * x + b * x - x * y dL_db = lambda a, b: b + a * x - y # (a, b)を1回更新する更新量を(da, db)とする da = -lr * dL_da(a, b) db = -lr * dL_db(a, b) print(da, db)# 答えを表示
Momentum
特徴:大域的な最適解を解く.学習率の値が重要である小さすぎると学習時間が長い、大きいと発散する.
大きく学習して、どんとん小さく学習する(学習係数を徐々に下げていく).
パラメータθの更新式:
or
慣性項は直前のパラメータの更新量に比例する項であるため、
サンプルコード:
self.v[key] = self.momentum[key] * self.v[key] - self.lr * grads[key] #lr: 学習率
param[key] += self.v[key]
モメンタムありのとき2回目のパラメータの更新量
サンプルコード:
(a, b) = (-0.1 * 0.9, 0.1 * 0.9) #「前回の更新量」×「慣性項のパラメータ」 lr = 0.1 # 学習率 learning rate (x, y) = (0.0, 0.5) # 問題文における偏微分の定義で n = 1 とする dL_da = lambda a, b: a * x * x + b * x - x * y dL_db = lambda a, b: b + a * x - y # (a, b)を1回更新する更新量を(da, db)とする da = -lr * dL_da(a, b) + a db = -lr * dL_db(a, b) + b
Nesterov
パラメータθの更新式:
すなわち
サンプルコード
self.v[key] *= self.momentum
self.v[key]-=self.lr * grads[key]
param[key] += self.momentum* self.momentum* self.v[key]
param[key] -= (1+self.momentum) * self.lr * grads[key]
AdaGrad
特徴:AdaGradは各パラメータの要素ごとに学習率を調整して学習する.各要素の学習率を決めるため変数hとする.
勾配の絶対値の大きい要素に更新量を小さくし、勾配の絶対値の小さい要素に更新量を大きくすることで、学習率を調整する.
課題:AdaGradの更新量が0に近づく、パラメータは更新しない.(それを解決するため、RMSpropが開発された)
パラメータθの更新式:
サンプルコード:
for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * (1/np.sqrt(self.h[key]+1e-7)) * grads[key]
RMSProp
特徴:過去のすべての勾配を均一に加算しない.過去の勾配を徐々に忘れて、新しい勾配情報を大きく反映されるように加算する(指数移動平均)
- AdaGradに加えて、時間が経過するほど更新幅が小さくなるようにdecayを用いて学習率が計算される.
- grads[key]の要素が大きい場合、パラメータ更新幅が小さくなる.
- grads[key]が0に近い場合、更新回数が多くなるほど、パラメータ更新幅は大きくなる.
- self.decay_rateは0から1の値を取る。
パラメータθの更新式:
サンプルコード
self.h[key] *= self.decay_rate self.h[key] += (1-self.decay_rate)*grads[key]*grads[key] params[key] -= self.lr * (1/np.sqrt(self.h[key]+1e-7)) * grads[key]
Adam
特徴:
パラメータθの更新式:
サンプルコード
self.m[key] = self.rho1 * self.m[key] + (1-self.rho1)* grads[key] self.v[key] = self.rho2 * self.v[key] + (1-self.rho2)* grads[key]*grads[key] params[key] -= self.lr * m/ (np.sqrt(v) +self.epsilon)
検証集合
ホールドアウト法
k-分割交差検証
正則化(Regularization)
過剰適合を抑えることを目的にパラメータに何らかの制約を課すことを正則化という.
L2 Ridge
L2ノルムのWeight decayは で、損失関数に加算する.
λ:正規化の強さをコントロールするハイパラ.
- 大きくすると、大きな重みを取ることに強いペナルティを与える.
- パラメータが原点から離れることに対して、ペナルティを与える.
- 大きくすると、学習が失敗するようになった
- 小さくすると過学習が防げず、いずれの場合も学習がうまくいかなかった.
- ハイパーパラメータを大きな値に設定すると、すべての重みが限りなく0に近づく
- 「いくつかの回帰係数は0に近づくか、完全に0にならない」
L2ノルムは、||param||^2なのでその勾配が誤差の勾配に加えられる.
→2 * paramであるが、係数2は正則化の係数に吸収されても変わらないのでgrad +=rate +param と定義する.
L1 Lasso
大きくすると、学習が失敗するようになった.
- 小さくすると過学習が防げず、いずれの場合も学習がうまくいかなかった.
- 「いくつかの回帰係数は完全に0となる」
L1ノルムは、|param|なのでその勾配が誤差の勾配に加えられる.
→x = np.sign(param)
grad += rate *x
と定義する.signは符号関数である.
Early Stop
訓練時、エポック毎に検証誤差を算出し、検証誤差が前ステップの検証誤差より小さくならなかったら、1カウントとする.
検証誤差が最も小さくなる時点やその近辺で訓練を打ち切る.
Dropout(2014年)
- 訓練時、ユニットをランダムに消去しながらパラメータの最適化を行う.ユニットを消去する割合は定数として与える.
- Dropoutの予測結果を複数のネットワークのアンサンブル平均と解釈する.各ネットワークはパラメータを共有する.
- 各ユニットは確率pで存在していて、pを大きくすると、ランダムに消去されるユニットが少なくなる. p=1- dropout_ratio
- 訓練後、ユニットがすべて存在している.完全なネットワークによって予測する.各ユニットの出力には、確率Pをかける.
サンプルコード
class Dropout: """ http://arxiv.org/abs/1207.0580 """ def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None def forward(self, x, train_flg=True): if train_flg: self.mask = np.random.rand(*x.shape) > self.dropout_ratio return x * self.mask else: return x * (1.0 - self.dropout_ratio) def backward(self, dout): return dout * self.mask
#予測時にすべてのユニットを採用して、すべてのパラメータにユニットを消去しなかった割合を一律にかける.
def backward(self, dout):
return dout*self.mask
#逆伝播では順伝播に消去したユニットは勾配を伝えず、消化しなかったユニットは勾配をそのまま入力層側へ伝える.
|
荷重減衰(Weight decay)
重みパラメータの値が小さくなるように学習を行うことを目的とする.重みの値を小さくすることで、過学習が起きにくい.
正則化(Normalization)
訓練前に特徴量を特定のスケールに調整しておくことを正則化という
Batch Normalization(2015年)
重みの初期値を適切に設定すれば、各層のActivation分布は適度な広がりを持ち、学習がスムーズに行える。
>> Activationの分布を調整するのはBatch Normalizationである.
バッチ正則化を行う部分を1つの層として考える。バッチ正規化層のあるノードへの入力をhとすると、バッチ正規化層では、以下の式で正則化する
訓練時、バッチ正規化層への入力を用いて計算する.テスト時、バッチ正規化層への入力を用いて計算するのではなく、訓練時に計算しておいた移動平均値を使う.
また、バッチ正則化では、モデルの表現力を維持するために、正則化さらたh'を、パラメータのγとβを用いて、γh'+βに置き換える
サンプルコード
def forward(self, x, train_flg=True): if self.running_mean is None: N, D = x.shape self.running_mean = np.zeros(D) self.running_var = np.zeros(D) if train_flg: mu = x.mean(axis=0) # 平均 xc = x - mu # xをセンタリング var = np.mean(xc**2, axis=0) # 分散 std = np.sqrt(var + 10e-7) # スケーリング xn = xc / std self.batch_size = x.shape[0] self.xc = xc self.xn = xn self.std = std self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu # 平均値の加重平均 self.running_var = self.momentum * self.running_var + (1-self.momentum) * var #分散値の加重平均 else: xc = x - self.running_mean xn = xc / ((np.sqrt(self.running_var + 10e-7))) out = self.gamma * xn + self.beta return out
# 逆伝播メソッドの定義 def backward(self, dout): # 微分の計算 dbeta = dout.sum(axis=0) # 調整後の平均 dgamma = np.sum(self.xn * dout, axis=0) # 調整後の標準偏差 dxn = self.gamma * dout # 正規化後のデータ dxc = dxn / self.std # 偏差 dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0) # 標準偏差 dvar = 0.5 * dstd / self.std # 分散 dxc += (2.0 / self.batch_size) * self.xc * dvar # 偏差 dmu = np.sum(dxc, axis=0) # 平均 dx = dxc - dmu / self.batch_size # 入力データ # インスタンス変数に保存 self.dgamma = dgamma self.dbeta = dbeta return dx
<メリット>
1. 学習を速く進行させる(学習係数を大きくする)
2. 初期値に依存しない
3. 過学習を抑制する(Dropoutを減らす)
ミニバッチごとに正則化を行う.データの分布が平均0で分散が1になるように正規化
式

<問題点>
1. バッチ方向に平均と標準偏差を計算するため、データ数が1である.
2. オンライン学習の場合には適用する意味がない
3. ミニバッチごとのデータ数が極めて少ない場合に適していなくて、収束性が悪い.
Instance Normalization(2016年)
スタイル転送タスクにおいてInstance Normを用いることで、出力画像の質を高められるスタイル転送にこのInstance Normalization を導入した理由は、
スタイル転送の出力を観察すると、合成画像のコントトラストはコンテント画像(構造を担保するContent image)のコントラストに依存しないように見られたため.
深層学習_画像認識_基礎
畳み込み層
画像の場合、縦、横、チャンネルの3次元のデータをそのまま学習し、次に伝えることができる.
→3次元の空間情報も学習できるような層が畳み込み層である.
畳み込み層の演算
入力画像とフィルタとの各要素の積和演算を行う.
パディング
畳み込みによる出力サイズが小さくなって演算できなくなるため、入力データの周りに固定データを合わせて入力サイズを大きくして、出力サイズを調整する.
ストライド
入力画像に対してフィルタを1つずつずらしながら畳み込み演算を行うが、ずらす2つ、3つ設定することもできる.それはスライドと呼ぶ.
チャンネル
フィルターの数=チャンネルの数
処理後の画像サイズの計算式

プーリング層
畳み込み層で浮き出てきた特徴をぼやけさせ、他の似たような特徴と同じとみなして学習させる.重み係数を使わない.

im2col


def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return col
# im2colによる画像を変換 col = im2col(x, kh, kw, sh, sw, ph, pw) n, c, kh, kw, out_h, out_w = col.shape #適切な形に変形しmaxをとる col = col.reshape(n, c, kh*kw, out_h, out_w) y = col.max(axis = 2) # 各カーネルの領域ごとにmaxを取る or -------------------------------------------------------------------------- col = im2col(x, pool_h, pool_w, stride, pad, constant_values=0) col = col.reshape(-1, pool_h * pool_w) out_idx = np.argmax(col, axis=1) # 最大値のインデックスを求める out = np.max(col, axis=1) out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
機械学習_教師あり/なし学習
教師なし学習
主成分分析
特徴
教師なし学習であり、次元削減を行うための手法である.
分散共分散行列の固有ベクトルの基に新たな座標軸を複数作成し、新たな座標軸から構成される低次元空間へデータを写像する.
寄与率:各主成分の固有値を固有値の総和で割った値
計算
2次元空間で(-2,2),(-1,-1),(0,0),(1,1),(2,-2)という5つのデータ点がある
第一主成分: (1/√2, -1/√2)
第二主成分: (1/√2, 1/√2)
(1/√2,-1/√2)のx軸とy軸をそれぞれのデータ点と掛けた和である
第1主成分によって張られる1次元空間へ5つのデータ点を射影すると
1/√2*(-2)-1/√2*(2)=-2√2
1/√2*(-1)-1/√2*(-1)=0
1/√2*0-1/√2*0=0
1/√2*1-1/√2*1=0
1/√2*2-1/√2*(-2)=2√2
第2主成分によって張られる1次元空間へ5つのデータ点を射影すると、
1/√2*(-2)+1/√2*(2)=0
1/√2*(-1)+1/√2*(-1)=-√2
1/√2*0+1/√2*0=0
1/√2*1+1/√2*1=√2
1/√2*2+1/√2*(-2)=0
第1主成分と第2主成分による張られる2次元空間へ5つデータ点を射影すると、
(-2√2,0),(0,√2),(0,0)(0,√2),(2√2,0)である。
再構成誤差は、2次元空間に射影することによりも、1次元空間に射影されるデータのほうが大きい.
http://ibis.t.u-tokyo.ac.jp/suzuki/lecture/2015/dataanalysis/L7.pdf
def pca(X, n_components): X = X - X.mean(axis=0) # データから平均を引く cov = np.cov(X, rowvar=False) # 共分散行列の作成 l, v = np.linalg.eig(cov) # 固有値と固有ベクトルを計算 l_index = np.argsort(l)[ : : -1] #★ 固有値を降順でソートするためのインデックスを求める v_ = v[ : , l_index] #★ 固有ベクトルを降順でソートする components = v_[ : , : n_components] #★ 固有ベクトルを取得する処理, 出力の次元数分の固有ベクトルを取り出し、低次元空間へ写像 T = np.dot(X, components) return T
n_componentsの個数だけ、固有ベクトルを切り出す
データを低次元空間に射影する
K-means
特徴
<アルゴリズム>
1. 各点xiに対してランダムにクラスタを割り振る
2. 各クラスタに割り当てられた点について重心を計算する
3. 各点について上記で計算された重心からの距離を計算し、距離が一番近いクラスタに割り当て直す
4. 2と3の工程を、割り当てられるクラスタが変化しなくなるまで行う
【E資格対策】k-meansの実装方法について詳しく見る
def init_centroid(X, k, n_data): # 各データ点の中からクラスタの重心となる点をk個ランダムに選択 permutation 重複なしランダムデータ idx = np.random.permutation(n_data)[:k] #★ centroids = X[idx] return centroids def compute_distances(X, k, n_data, centroids): distances = np.zeros((n_data, k)) for idx_centroids in range(k): #すべてのデータ点との距離の二乗を計算 dist = np.sqrt(np.sum((X - centroids[idx_centroids]) **2, axis=1)) #★ def k_means(X, k, max_iter=300): centroids = init_centroid(X, k, n_data) for epoch in range(max_iter): distances = compute_distances(X, k, n_data, centroids) new_cluster = np.argmin(distances, axis = 1) # ★新たな所属クラスタを計算 for idx_centroids in range(k): centroids[idx_centroids] = X[new_cluster == idx_centroids].mean(axis=0) #★
K-means++
特徴
K-means法でははじめてのセントロイドの位置が近い場合、うまく分類できないケースがある.
そのため、K-means++では各セントロイド同士の距離がなるべく遠くなるように決める.
probabilites = np.sum(distances, axis=1) / np.sum(distances) # 列ごとに演算行うためaxis=1
distancesのすべての要素の和でdistancesの要素を割ることで各要素は0から1の間に正則化される.
さらに、今までのセントロイドの距離を考慮して行ごとに和を取るで、初期化として選ばれる確率を表すProbabilitiesを得ることができる.
この初期値の選択方法を、ルーレット選択という呼ばれる.
closet_dist_sq = np.min(distance ** 2, axis =1) #各データ点と最も近い重心との距離に二乗を計算 weights = closet_dist_sq.sum() # 距離の二乗の和を計算 rand_vals = np.random.random_sample() * weights # [0,1)の乱数と距離の二乗和をかける candidate_ids = np.serchsorted(np.cumsum(closest_dist_sq), rand_vals) # 距離の二乗の累積和を計算し、rand_valsと最も値が近いデータ点のindexを取得
k-meansとk-means++を視覚的に理解する~Pythonにてスクラッチから~ - 医療職からデータサイエンティストへ
SVM
2クラス分類問題であり、決定的な出力をする分類器である.(他クラス分類や回帰にも使える)
特徴
1. ハードマージン
- マージンの最大となる境界のパラメータw,b を学習
- 識別面を構成するために使われるマージンの上にあるデータ点をサポートベクトルと呼ぶ.
- サポートベクトルの数は学習全数データより少なく、最小値は2である
- SVMの出力はそのままでは確率値として解釈できない、ロジスティック回帰のように事後的に境界面を調整できない.
- マージンの外側のデータは予測影響を与えない(それは、識別では決定境界から近い点のデータもしくはマージンの上の点が予測に利用されるため)
- SVMにおいて射影手法を利用して、特徴空間が高次元であるほど、表現力が上がるが、計算コストが高い。計算コストを抑制するため、カーネルトリックを導入
カーネルトリック: ガウシアンカーネル、多項式カーネル、Sigmoidカーネル
2.ソフトマージン
学習データが線形分離が不可能となる場合、すべての制約を満たすことができない.スラック変数を導入して誤分類を許容する.
SVMにおいて最小化する目的関数Lの数式
- Cが
になると、マージン内に訓練データが入ることで、誤分類を一切許容しない
- Cが0になると、誤分類が許容しやすく、誤分類が多くなる.
- Cが小さいすると、過学習を抑制できる.
- Cが大きくすると、誤分類の許容が大きくなる.テストの正解率が低くなる.完全に分離することで汎用性能が小さいくなる.

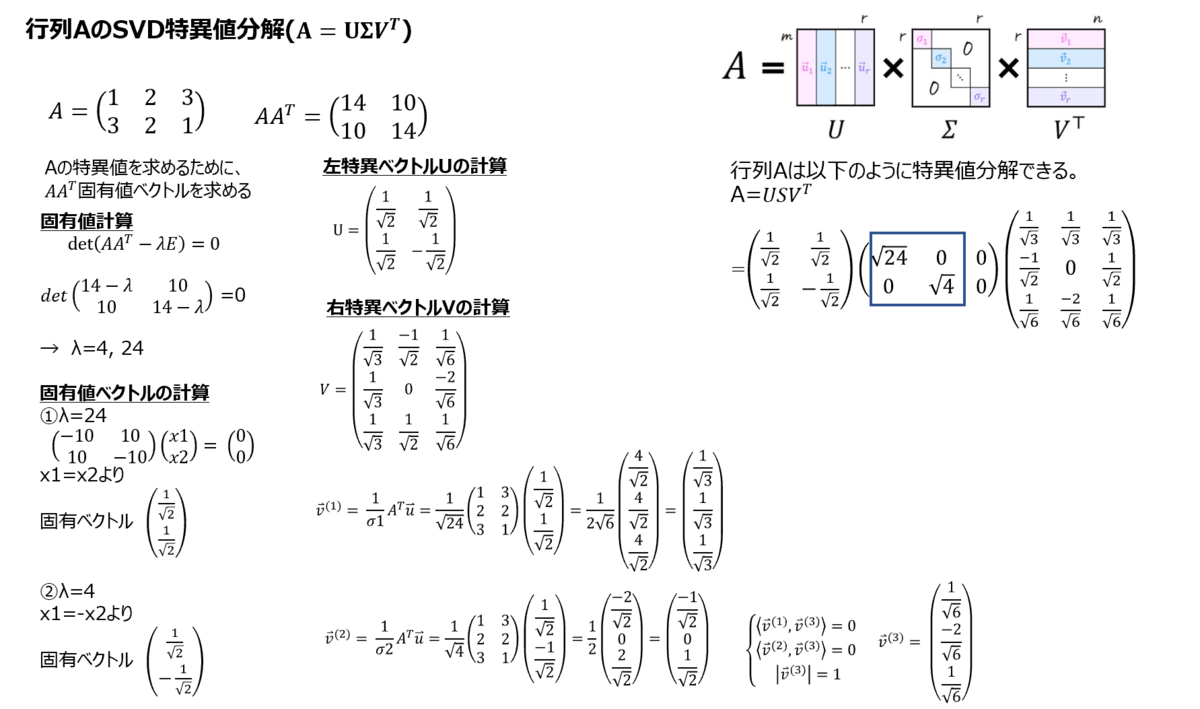





深層学習_自然言語処理
Word2vec(2013年)
次元の呪いを回避する目的や単語ベクトルの空間に意味を与えるため、単語を分散表現に変換する方法の1つとして、Word2vecである。
埋め込み行列を獲得するため方法として、CBOW(Continuous Bag-of-words)とSkip-gramが用意される.
・CBOW:前後の単語からある単語を予測するためのNN周辺の単語から対象となる1単語を予測するモデル
・skip-gram:ある単語が与えられたときに、その周辺の単語を予測するためのNN対象となる1単語から周辺単語を予測するモデル.skip-gramはCBOWより計算コストが高いが、得られる埋め込み行列の質が良い.
入力層側の重みWinを単語埋め込み行列として利用する.
負例サンプリングによる計算の軽量化である.
出力層では、すべての語彙を対象して、Softmax関数と交差エントロピー誤差関数を計算する.
コーパスの中から単語の出現頻度に基づいてサンプリングする
GNMT(2016年) paper
工夫点:
・LSTMレイヤの多層化
・双方向LSTM層
・Skip Connection
・複数GPUでの分散学習
・予測の高速化(量子化)
GNMTデータ並列は、重みの更新は非同期で実行される.
RNNを用いた言語モデル
Seq2seq
RNNを用いたEncoder-Decorderモデルの一種で、機械翻訳に使われる.
機械翻訳タスクで、入力は複数の単語から文章まで、それぞれの単語はone-hotベクトルで表現される.
入力である文章を時系列の情報を持つ特徴量へとエンコードする関数である.
def encode(words, E, W, U, b): hidden_size = W.shape[0] h = np.zeros(hidden_size) for w in words: e = E.dot(W) h = _activation(W.dot(e) + U.dot(h) + b) return h
エンコーダとデコーダがつながって、エンコーダの計算が終わると、エンコーダの最後の隠れ状態がデコーダの1時刻目の隠れ層に伝わる.
ただし、長い系列のデータを学習す時、エンコーダの初期に入力された情報がデコーダまで伝わりづらくなる問題に対して、Global-Attentionが導入される.
デコーダの対象時刻の隠れ層の出力とエンコーダの各時刻の隠れ層の出力から重みベクトルatを算出し、重みベクトルとそれをかけて、Ctを得て、デコーダの計算で利用される.
Attention
Q,K,V
Soft-Attention : softmax関数で確率分布を求めてその確率分布を用いて重みつき平均を求める方法である.
Hard-Attention: softmax関数で確率分布を求めてその確率分布に従って抽出された1点だけを得る方法である.<コード>
デコーダの隠れ状態のサイズ Nx H
h.reshape(N,1,H).repeat(T, axis=1)
アテンションの重みは N X Nとなる.
H方向に合計np.sum(t, axis=2)
Transformer(2017年)
Attention:
従来の畳み込み層や回帰結合層より優れた点として、
①Attentionを使用すると各要素同士がどれほど反応したかを数値化して可視化することできる.
②Attentionは依存関係を学習するのは得意だが、回帰結合層の一種ではない.
③入力層と出力層のすべてがネットワークでつながっているため、長い系列であっても依存関係を学習できる.
④Attentionは並列に計算できるので回帰結合層より計算がはやい.
1.Self-Attention:同じ情報源から計算するもの、同じ文章内の単語間の関係をとらえる. 一つの分散表現をKey, Value, Queryの三つに分割して獲得する.
2.Source-Target-Attention: keyとValueがエンコーダ側の情報、Queryがデコーダ側の情報で分ける。2つの系列間の対応関係をとらえる. 二つ分散表現を使用し、一つkeyとValue、残りQuery
3. Multi-head-Attention:複数個のスケール・ドットプロダクト・アテンションを並列に配置したもの
①エンコーダでのMulti-head attentionでは、QueryとKeyとValueはすべて直前のエンコーダの出力から伝わってくる.(self attention)
②デコーダ
・1つ目はSelf attentionだが、予測すべき単語の情報が予測時に利用されないようにするためにマスクがかけられる.マスクがかけられた場所の値は、Softmax関数に入力される前に -∞に置き換えられる.
・2つ目はMulti-head attentionでは、keyとValueはエンコーダ、Queryはデコーダから伝わってくる.
RNNの再帰的処理やWaveNet畳み込みが存在しないため、系列順序の情報を知るため、Position embeddingを導入し、単語の順序の情報を埋め込まれるベクトルで、単語埋め込みベクトルに加えられる.
BERT(2019年) paper
Bidirectional Encoder Representations from Transformers

[事前学習] 教師なし学習
①単語マスク問題をとくことで、局所的な特徴を捉える.
②次の文かどうかを予測する問題を解くと、大域的な特徴を捉える.
[ファインチューニング] 教師あり学習
Token embeddings :単語の違いを表す情報
Segment embeddings:文の違いを表す情報
Position embeddings: 単語の順序を表す情報

特徴:
- Transformer のエンコーダー部分を使っている
- 新しいタスクに対してファインチューニングが必要
- 双方向Transformer
- 文の中のどの位置の単語もマスクされる可能性があり、マスクした前の単語も後ろの単語にも注目する必要がある
GPT-n(2020年) paper
特徴
- Transformerのデコーダー部分を使っている
- ファインチューニングをしない
- 単一方向の Transformer
- 常に次の単語を予測するため、双方向ではない
WaveNet(2016年) Googleにより提案音声処理paper
- pixelCNNアーキテクチャに基づく音声生成モデルである.
- 同時確率分布の数式は、各音声サンプルがtより前のすべての時刻ステップにおける音声サンプルによって条件付けられること.
- WaveNetではコーザル畳み込み(causal convolution)とダイレイト畳み込み (dilated conv)を組み合わせたものを用いる.
- コーザル畳み込み:
過去の時刻ステップだけを用いて畳み込み.
モデルがデータの時間順序を破らないことを保証できる再帰結合を持たないため、RNNを訓練する場合よりも計算が高速になる.
画像処理も同等な手法にマスク畳み込みがある.受容野を広くには、多くの層/大きな畳み込みフィルタが必要.
- ダイレイト畳み込み:
少ないパラメータで広い範囲の畳み込み受容野を広げるため使う.フィルタとの積を取る相手の間隔をあける畳み込みのこと.
フィルタを適用する入力データの場所を数ステップずつスキップし、フィルタをその長さに比べて長い領域に適用する.
(拡大度Dilationは、出力層に向かうほど大きくなる)
メル尺度
CTC
機械翻訳の精度指標BLEUsがある.BLEUでは機械翻訳が参照翻訳より短い場合にペナルティを与え、参照翻訳より長い場合はペナルティを与えないBPを用いてること.
[例]
機械翻訳と参照翻訳がある. n=2のn-gramで分割した時のmodified n-gram precisionは10/17である.

機械翻訳の精度を算出するとき、よくn=1~4におけるmodified n-gram precisionの値の対数加重平均とBPを用いる.機械翻訳の精度を加重平均ではなく対数加重平均で評価するメリットとして、
機械翻訳の妥当性と流暢性を考慮した安定的な評価ができる.nは指数的に小さいなる傾向があるため、対数加重平均をとってスコアを平坦化する.nが小さい時のスコアは妥当性、nが大きい時のスコアは流暢性を評価している.
BLEUではmodified n-gram precisionを計算しているが、c>rの時、modified n-gram precisionの値は小さくなり、実質的にペナルティとなっている.
深層学習_生成モデル
識別モデルと生成モデル
オートエンコーダ
VAE(2013年)
Variational AutoEncoder 変分自己符号化器:生成モデルの一つ
p(z):平均ゼロベクトル、分散共分散行列が単位行列であるような多変量標準正規分布の対角成分を出力するNN
[VAEの変分下界]
対数尤度logp(x)を最大化する代わりに、下界Lを最大化するように学習を行う.
<Lの第1項>デコーダから再構成されたデータに関する対数尤度. 復元誤差(reconstrunction error)、入力と出力の差を小さくする.
<Lの第2項>p(z|x)のp(z)に対するKLダイバージェンスエンコーダとデコーダの間に潜在変数zのサンプリングが入るため、エンコーダまで誤差逆伝播を適用するのは難しい.
エンコーダからのサンプリングを実行する.このサンプリング方法をreparametrization trick リパラメタリゼーショントリックと呼ばれる.
はデコーダの出力xを使った二乗損失に置き換えることができる.
AutoEncoder, VAE, CVAEの比較 〜なぜVAEは連続的な画像を生成できるのか?〜 - Qiita
VQ-VAE
GAN(2014年)
ミニマックスゲームの数式
損失関数
通常のGANでは以下の価値関数の最適化を行う.
本物データの確率密度分布pdata(x)と生成データの確率密度分布pz(x)が固定される場合、最適な識別関数D(x)は

DをだますG、GをだまされないDを目指す.DとGを学習させていく.
もし、最適な生成器と識別器の両方が得られた場合、識別器の出力は0.5となる.
self.update_discriminator(noize, batch_train_data) self.update_generator(noize)
Dの更新よりもGの更新の方が勾配消失問題が起きやすい.
Discriminatorの出力層から逆伝播するため、入力層に近いGenerator側の勾配が小さくなる可能性が高くなる.
DCGAN(2015年)
Generatorに入力のノイズとしてのベクトルだけを与えて、Discriminatorが生成画像の真偽の判別を行う.
GANは優れた生成能力を持つが、学習が難しい.
CANの枠組みをCNNに適用した深層畳み込みGANはDCGANである.
学習を安定化させるため、以下の提案が導入される.
- プーリング処理の代わりに、ストライドを2以上に設定した設定した畳み込み層や逆畳み込み層を用いる
- 生成器と識別器の両方にバッチ正規化を使用する
- 生成器の活性化関数は、最終層にtanh, それ以外にReLUを使用する
- 識別器の活性化関数にLeaky ReLUを使用する
- 全結合層を使用しない
(識別器と生成器ともバッチが正規化される)
conv4=Conv2DTranspose(3,(5,5),(2,2),"same",activation="tanh",kernel_initinalizer=self.w_init)(conv3)
[Discriminatorの特徴]
- 中間層以外の活性化関数にLeakyReLUを用いる
- Batch Normalizationを頻繁に入れる
- Pooring層の代わりにStride=2の畳み込み層を使う
- 全結合層(Affiine Layer)を使用しない
Conditional GAN(2014年)
訓練時に教師データのラベル情報を用いて、生成するクラスを指定できる
生成するデータに関する条件を与えることで、その条件に従うデータを生成することを可能としたGANである.条件には、クラスラベルや文章などのベクトル表現を用いる.
LAPGAN
低解像度な画像を生成するGANを訓練することはもっと簡単なとき、LAPGANは使用される
低解像度と高解像度の画像の差を学習し、画像を高解像度にする.
訓練時、Generator,Gに低解像度の画像を入力し、低解像度と高解像度の画像の差を生成し、
Discriminatorが本物か生成されたものか判定. 高解像度の画像を作成することに成功した.画像を生成するモデルとして発案されたが、近年で画像や音楽のタスクに応用される.
ACGAN
Generatorに入力ノイズとしてのベクトルと入力画像のクラス情報を同時に与え、Discriminatorが生成画像の真偽に加えてクラスの判別も行う
SNGAN
新しい正則化であるSpectral normalizationsを提案したもの
pix2pix(2017年)
Conditional GANの条件を画像とすることで、スタイル変換を実現したのはpix2pixである.
- pix2pixは、ConditionalGANの目的関数V(G,D)にL(G)を追加することで、画像の大域的な情報を捉えられるようになり、より違和感のない画像を生成するを使用することに成功する.
- 識別器が画像の高周波数の構造を捉えられるように、画像の中でNxNのバッチがそれぞれ本物か疑物かを判定するようにする.ここで、バッチサイズよりも離れた場所にあるピクセル間は独立であることを仮定する.
- pix2pixは変換前画像と変換後画像のペアを用意する必要がある.片方しかない場合、CycleGAN(2017年)と呼ばれる.
- L1損失やL2損失は、画像の低周波数の構造をよく捉えるが、画像の高周波数の構造(細かい構造)をよく捉えられず、画像がぼやける欠点がある.その欠点を解消するため、pix2pixは画像の局所的なパッチの構造に注意を向ける.この認識気をPatchGANと呼ぶ.
- pix2pixは文章の描写から高解像度の画像への変換を行わない.(エッジのスケッチからカラー画像、昼の写真から夜の写真、航空写真と地図の変換)のスタイル変換に応用できる.文章の描写から高解像度の画像への変換のは、stackGAN(2017年)
- エッジからカラー写真への変換タスク学習の場合、エッジの画像を条件として生成器、識別器それぞれに与えるという動作になる.U-Net(2015年)を生成器に用いる.Skip Connectionを用いてエンコーダの情報をデコーダへ渡し、連結するため、白黒画像からカラー画像への変換タスクでは生成器において、入出力画像間でエッジの位置を共有するという処理する.
- pix2pixの応用として、画像にキャプションをつけることは入力画像から出力画像に変換できない.線画に対して自動で着色、一部を背景から補完、入力画像から高画質に変換
強化学習
動的計画法(DP法)
特徴:環境の完全なモデルがマルコフ決定過程として与えられる場合にのみ適用できる方法である.
すべての遷移の完全な確率分布を必要とするため、適応できる問題が限られる.
1. 方策勾配法
勾配降下法では符号がマイナス(誤差を小さく)だが、方策勾配法では符号がプラス(報酬を大きく)である.
③方策をパラメータθで直接モデル化し、期待収益J(θ)を目的関数として勾配を用いて最適化する.学習率をηと置くと、方策勾配法は以下のように表される.
方策勾配定理は以下の式となる.
勾配を方策勾配定理を用いて表すと、のようになる.
変形すると、勾配]
![]()
2. 価値反復法
報酬のサンプリング
1. TD法
TD学習:目標の価値と現在の価値のずれを修正していくことで、価値関数を推定する.(SarsaとQ学習)
Sarsa
Sarseにおける行動価値関数の更新式:
Q学習
Sarseにおける行動価値関数の更新式:
A3C
2. モンテカルロ法(MC法)
Q学習やSarsaとは違い、Q値の更新のときに「次の時点のQ値」を使わない.
行動の修正を行う方法として、tとt+1の差異のような行動1回での差異ではなく、t+2,t+3・・・Tまでの1エピソードでの差異を求めること.
![]()
行動の修正を実績に基づいて行うため、エピソードが終わるまでは修正できない.(1回の行動の直後に予測で修正できない)
従って、修正の妥当性が得られるが、修正スピードが遅い.
強化学習アルゴリズム
Q学習 DQN Deep Q-Networks(2013年)
Atari2600の中の7つゲームを学習させたところ、ゲームごとにチューニングせずに、専門家の能力に達成した.
畳み込みNNを用いて行動価値が目標として、行動価値に近づく学習する.
それまで安定した学習できなかったが、DQNは学習を安定させた.
学習安定の工夫点3つ:
①体験再生, ②目標Q-networksの固定, ③報酬のクリッピング①体験再生
i)パラメータの更新時、同じ経験を何回も学習に使えるため、データの効率がオンライン学習より良い.
ii)ランダムに取り出された経験を用いて、損失を計算するため、入力系列の相関を断ち切ることができ、更新の分散を軽減できる.iii)過去の様々な状態で行動分布が平均化されため、直前に取得したデータが次の行動の決定に及ぼす影響を軽減できるて、パラメータの振動を避ける.②目標Q-networksの固定
「価値関数が小さく更新されただけでも選ばれる行動が大きく変わってしまう」の問題に対して、目標値の算出に用いるQ-networksのパラメータを固定して、一定周期で更新して学習を安定させる.
損失関数は以下の式で表せる.
]
目標値の項は、
は目標QNetworksで固定されるパラメータである.
更新式
第1項が現在のQ値、第2項が新しいQ値にあたり、その二項が 1−αと α で足し合わされるため、現在のQ値を第2項にむかって αぶんだけ近づける更新する.
エージェントは自由に行動を選ぶことができるため、現在推定されている価値のmax値をもって価値の見積もりとする.
特徴
- SARSAと異なり、行動価値関数Qの更新が行動の決定方法に依存しない.
- SARSAよりも行動価値関数の収束が速くなるが保証しない.
- 「行動を決定する方策」と「行動価値関数の更新に用いる方策」が異なる.
- 行動価値関数を更新すると、行動価値が小さい探索結果は反映にくい.
SARSA サルサ
Q学習では、期待値の見積もりを現在推定されている値の最大値で置き換えるが、
Sarsa の場合、実際に行動してみたらどうなったかを使って期待値の見積もりを置き換える.
そのため、Sarsa では現在の価値を更新するためには、エージェントが実際にもう一度行動をおこなう必要がある.
更新式
特徴
- 行動価値関数を更新するとき、行動価値の小さい探索結果も反映されやすいという特徴があるが、計算が不安定になりやすい.
- Q学習も同じ、経験していない「状態と行動の組み合わせ」に対する行動価値関数は更新されない.
- 方策オン型の手法で、「行動を決定する方策」と「行動価値関数の更新に用いる方策」は同一のものである.
- 方策勾配法は用いられない.確率的方策
のパラメータθを勾配法で更新していく.
マルコフ決定過程

参考先:CS 294 Deep Reinforcement Learning, Fall 2017
ある期間で得られる報酬の累積を収益という.時刻tでの収益Gtは、時刻t+1以降の報酬の割引累積和であり、0<γ<1を満たす割引率γを用いると
となる.
状態価値と行動価値の関係は、 となる.時刻tにおいて選択可能なすべての行動aに関する期待値をとると、状態価値関数V(s)になる
強化学習まとめ① 〜有限マルコフ決定過程(Finite MDP)〜 - あつまれ統計の森
状態価値関数の導出とBellman方程式:
]]
価値関数は、直近の報酬に1ステップ先の価値関数を足したものである.
ただし、方策および遷移確率で未来のとりうる値は枝分かれするので、その期待値をとる.
行動価値関数の導出とBellman方程式:
]]
AlphaGo (2015年)
[学習]
畳み込みニューラルネットワークでモデル化した状態価値関数および方策関数を用いることで、探索の際の深さと幅を減らす.
学習過程が3つのステージで構成される.
第1ステージ、教師あり学習によって囲碁の熟年者の手をNNに学習させる。これをSL(Supervised Learning)方策ネットワークと呼ぶ.
ネットワークのパラメータθの更新式は以下である。
- SLポリシーネットワークのパラメータ更新
- RLポリシーネットワークのパラメータ更新
- バリューネットワークのパラメータ更新
[対局]
モンテカルロ木探索手法で相手の手を読む. 方策ネットワークと価値ネットワークを用いる.
AlphaGo実戦(対局)時の数式
暫定勝率=Q(s,a) + u(s,a)
参考文献
深層学習 Day 4 - 強化学習、AlphaGo のまとめ - Qiita
