ヘンリーで SRE をやっている ![]() id:nabeop です。
id:nabeop です。
昨年からオフラインイベントも活況になってきています。登壇の準備段階や登壇時に気をつけておきたいポイントについてまとめて、技術勉強会 (ギベン)1でエンジニアが社外登壇するときに気をつけたいことの Tips 集みたいな感じで発表してみました。このときの発表の評判がよくて社外向け版もつくってみない?という声があったので書いてみました。
続きを読む株式会社ヘンリーでSREなどをやってる戸田(id:eller)です。弊社サービスはBackend for FrontendとしてApollo Serverを採用しています。
先月まではApollo Server v3を利用していましたがEOLが今年の10月に迫っていたため、v4へのアップグレードを実施しました。この記事では移行時に実施したことをご紹介いたします。
なお公式ドキュメントに主な変更点がまとまっていますので、類似の作業を予定されている方はそちらをまずご確認ください。
Apollo Server v4は graphql 16.7.0以降の利用を推奨しています。もしいま依存しているバージョンが古いなら、その更新から始めることをおすすめします。
弊社では graphql に加えて @graphql-tools/load と @graphql-tools/schema も使っており、更新が必要でした。これらの変更はApollo Serverの更新とは独立して事前に行ない、動作確認をしています。幸いにも性能への悪影響は観測されませんでした。
@apollo/server を導入するv3のときは以下のように数多くの依存を package.json に記述する必要がありました:
apollo-serverapollo-server-coreapollo-server-errorsapollo-server-expressapollo-server-plugin-baseapollo-server-typesしかしv4からは @apollo/server ひとつで足りるようになっています。コンテナの大きさには変化はなかったものの、依存管理コストが下がってとても嬉しい変更です。
なお @apollo/server-plugin-landing-page-graphql-playground に含まれる ApolloServerPluginLandingPageGraphQLPlayground はマイグレーション用に提供されているだけだそうです。弊社ではドキュメントに従って ApolloServerPluginLandingPageLocalDefault に置き換えました。
v3では ApolloError と GraphQLError の2つのエラーが存在しましたが、v4では GraphQLError に1本化されています。独自のエラー型を提供しなくなったわけですね。
弊社では ApolloError をcatchしていたり AuthenticationError を投げていたりしている箇所のコード書き換えを行っています。
v3では/.well-known/apollo/server-health を使ったHTTPレベルのヘルスチェックが提供されていましたが、v4ではこれがなくなりました。GraphQLレベルのヘルスチェックを使ったうえで apollo-require-preflight: true HTTPヘッダを設定する必要があります。
弊社ではCloud Runのstartup probeないしliveness probe、ならびにUptime Checkで利用するURLを変更し、GraphQLレベルに加えてDBサーバへの接続性なども確認しています。
Apollo Serverをv3からv4にアップグレードした際に実施したことを紹介しました。マイグレーションガイドが親切で、おおむね書いてある手順に従うだけで完了できました。性能上の問題も特に確認できておらず、更新後2週間近く経ちましたが安定して稼働できています。
この記事がApollo Server v3をご利用中の方の背中を押すきっかけになれれば幸いです。
株式会社ヘンリーでSREなどをやってる戸田(id:eller)です。最近の仕事のテーマはリスクコミュニケーションとサイト信頼性です。
弊社のビルドとデプロイは長らくCircle CIを使ってきました。一方でGitHub Actionsも強力なRunnerを使うハードルが下がったり、Circle CIのcontextsよりも使いやすいvariablesやsecretsの管理ができるようになってきたりしています。特にNodeJS開発界隈はGitHub ActionsがメジャーなCI/CD環境になってきている感触もあります。
今回は既存デプロイパイプライン整理のため、NextJSプロジェクトのデプロイパイプラインをGitHub Actionsで組み直しました。要点をご紹介いたしますので、どなたかの参考になれば幸いです。
gcloud run deploy や gcloud storage cp を実行するだけにして、変更のリードタイムを短縮する一環とします。ビルドとデプロイを分離するために、以下のようなワークフローが必要になります。弊社の組み方ですと対象環境ごとにコンテナイメージを作る必要があったため、ビルドマトリックスを利用しています。
graph LR
テスト
subgraph ビルド
development
staging
production
end
subgraph デプロイ
d-development[development]
d-staging[staging]
d-production[production]
end
development --> d-development
staging --> d-staging
production --> d-production
また弊社はアセットをCloud Storageにアップロードして、Cloud Load Balancingを経由してエンドユーザーに配布しています。Cloud Storageへのアップロードが即エンドユーザーに対する公開となるため、コンテナイメージはビルドフェーズにpushし、アセットはデプロイフェーズにアップロードさせたいところです。しかしどちらも next build コマンドによって作成するものであるため、アセットのアップロードをビルドフェーズではなくデプロイフェーズまで遅延させる必要がありました。
graph LR
subgraph ビルド
direction TB
build[job] --コンテナイメージ--> ar[(Artifact Registry)]
end
ビルド --アセットの受け渡し--> デプロイ
subgraph デプロイ
direction TB
deploy[job] --アセット--> gcs[(Cloud Storage)]
end
最後に、Pull Request(PR)作成時のワークフローではテストやビルドは行いたいもののコンテナイメージのアップロードはしたくない、またデプロイフェーズは実行する必要がないという特徴があります。こうした制御によってランニングコストを下げるとともに、エンジニアの開発体験を改善することができます。
今回の要件はほぼGitHub Actionsの基本機能で実現可能ですが、ビルドフェーズとデプロイフェーズの双方でビルドマトリックスを使っているところだけ注意が必要です。ジョブ同士の依存には jobs.*.needs を使いますが、ここでは matrix を参照できないからです。
jobs: build: strategy: matrix: env: - development - staging - production # ... deploy: strategy: matrix: env: - development - staging - production needs: - build[matrix.env] # このようには書けない
この問題に対応するため、今回は cloudposse/github-action-matrix-outputs-writeを採用しました。ビルドフェーズに含まれる各々のジョブからひとつずつアーティファクトをアップロードし、これを統合するジョブをデプロイフェーズの前に挟むことで、ビルド用ジョブとデプロイ用ジョブの間に依存関係を持たせつつ、不必要なデプロイ用ジョブを実行しない仕組みを実現しています:
jobs: build: # ... - uses: cloudposse/github-action-matrix-outputs-write@928e2a2d3d6ae4eb94010827489805c17c81181f # v0.4.2 if: steps.trigger-release.outputs.result == 'true' # リリースが必要な場合。後述 with: matrix-step-name: ${{ github.job }} matrix-key: ${{ matrix.env }} outputs: |- include: true # デプロイが必要な環境をリストアップしてmatrix用のJSONを出力する prepare: runs-on: ubuntu-latest needs: build steps: - uses: cloudposse/github-action-matrix-outputs-read@ea1c28d66c34b8400391ed74d510f66abc392d5e # v0.1.1 id: read with: matrix-step-name: build - uses: actions/github-script@v7 id: set-result with: script: | const input = JSON.parse(${{ toJSON(steps.read.outputs.result) }}); return input.include ? Object.keys(input.include) : []; outputs: result: "${{ steps.set-result.outputs.result }}" deploy: needs: prepare runs-on: ubuntu-latest if: join(fromJSON(needs.prepare.outputs.result), '') != '' strategy: matrix: env: ${{ fromJson(needs.prepare.outputs.result) }} environment: ${{ matrix.env }}
ジョブの依存関係は以下のようになります。
graph LR
テスト
subgraph ビルド
development
staging
production
end
subgraph デプロイ
d-development[development]
d-staging[staging]
d-production[production]
end
development & staging & production --> prepare --> d-development & d-staging & d-production
依存関係が表現できれば、ファイルの受け渡しは難しくありません。actions/upload-artifact と actions/download-artifact を利用して、 ${{ matrix.env }} をnameに含むアーティファクトをアップロード&ダウンロードするようにします。アーティファクトは一定時間で削除されますが、デプロイが充分に頻繁であれば問題にならないでしょう。
jobs: build: steps: # ... - uses: actions/upload-artifact@v4 with: name: next-static-${{ matrix.env }} path: .next/static # ... deploy: steps: # ... - uses: actions/download-artifact@v4 with: name: next-static-${{ matrix.env }} path: .next/static merge-multiple: true
弊社はGitflowを使って開発をしています。コンテナイメージのpushやデプロイフェーズの必要性を整理すると、以下のようになります:
これ以外のケース、例えばtopicブランチへの変更のpushやdevelopブランチに向けたPRの更新では、ビルドやテストは必要でもコンテナイメージのpushやデプロイの実行は不要です。この判断をGitHub Actions Workflowのフォーマットで表現することは可能ですが、単体テストを書きたいと考えたためJavaScriptファイルに切り出してactions/github-script で実行することとしました:
- run: | echo "head=${GITHUB_HEAD_REF:-${GITHUB_REF#refs/heads/}}" >> $GITHUB_OUTPUT id: extract-branch - uses: actions/github-script@v7 id: trigger-release with: result-encoding: string script: | const triggerRelease = require(".github/workflows/trigger-release"); const {HEAD_BRANCH, BASE_BRANCH, APP_ENV} = process.env; return triggerRelease(HEAD_BRANCH, BASE_BRANCH, APP_ENV); env: HEAD_BRANCH: ${{ steps.extract-branch.outputs.head }} BASE_BRANCH: ${{ github.base_ref }} APP_ENV: ${{ matrix.env }}
// .github/workflows/trigger-release.js /** * @param {string} head PRのHEAD、あるいはPUSHされたブランチの名前 * @param {string|undefined} base PRのBASEブランチの名前、あるいはundefined * @param {string} env development, staging, productionのいずれか */ module.exports = (head, base, env) => { const isPush = base === undefined || base.length === 0; if (env === "production") { return isPush && head === "master"; } else if (env === "staging") { return !isPush && head.startsWith("release/"); } else { return isPush && head === "develop"; } };
弊社のユースケースでは next build はコンテナイメージとアセットの双方を作成するのに必要なコマンドでありビルドフェーズに実行したいものでしたが、アセットのアップロードタイミングはデプロイ時にまで遅延させる必要がありました。またビルドマトリックスを利用するために、ビルドジョブとデプロイジョブの依存関係管理が複雑化していました。アーティファクトを利用することでこの2つの問題が解消できました。
またコンテナイメージのpushやデプロイフェーズの必要性を判断する条件は複雑化しがちですが、JavaScriptに切り出すことでVitestなどによる単体テストを書けるようになります。必要ならTypeScriptで書くこともできるでしょう。複雑化しやすいワークフローを制御するテクニックとして覚えておいて損はないと思います。
ヘンリーで SRE をやっている ![]() id:nabeop です。最近の仕事のテーマはサービスの可観測性の向上と信頼性の計測です。
id:nabeop です。最近の仕事のテーマはサービスの可観測性の向上と信頼性の計測です。
最近では可観測性の文脈では OpenTelemetry が話題に上がると思いますが、ヘンリーでも OpenTelemetry を導入してテレメトリデータを収集して、各種バックエンドに転送しています。分散トレース周りの話題については、以下のエントリがあります。
ヘンリーではマイクロサービスからのテレメトリデータは Cloud Run で構築した OpenTelemetry Collector で集約し、otelcol のパイプライン中で必要な処理を実施し、バックエンドに転送するアプローチを採用しています。
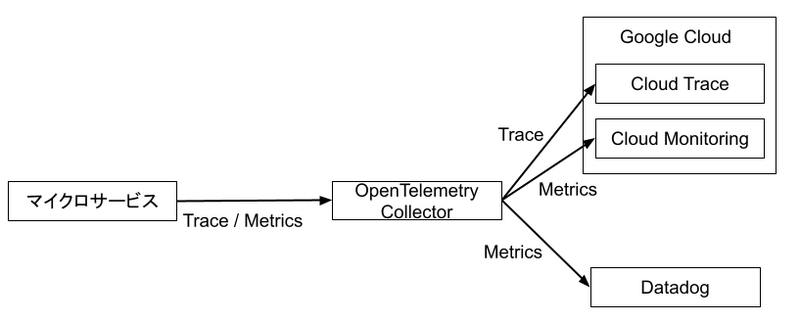
現在は監視基盤の移行期なので、メトリクスが Google Cloud と Datadog の両方に転送されていますが、将来的には Datadog に一本化される見込みです。
今回のエントリでは OpenTelemetry Collector 自体の可観測性をどのように確保しているかについて紹介します。
OpenTelemetry Collector のモニタリングについては以下のドキュメントが参考になります。
また、OpenTelemetry Collector 自体の可観測性の考え方についてはこのようなドキュメントがあります。このドキュメントでは実験的なアプローチとして OTLP でテレメトリデータを外部に転送するアプローチが紹介されています。今回は以下の理由から OTLP によるエクスポートを選択せず、Prometheus 方式で OpenTelemetry Collector の内部情報をエクスポートするアプローチを採用しました。
したがって、OpenTelemetry Collector の内部のメトリクスを Cloud Monitoring と Datadog の双方に転送する OpenTelemetry Collector の設定は以下のようになりました。
receivers: prometheus: config: scrape_configs: - job_name: otel-collector scrape_interval: 30s static_configs: - targets: ['0.0.0.0:8888'] processors: batch: send_batch_size: 8192 timeout: 15s transform/gcp: metric_statements: - context: datapoint statements: - set(attributes["exported_service_name"], attributes["service_name"]) - delete_key(attributes, "service_name") - set(attributes["exported_service_namespace"], attributes["service_namespace"]) - delete_key(attributes, "service_namespace") - set(attributes["exported_service_instance_id"], attributes["service_instance_id"]) - delete_key(attributes, "service_instance_id") - set(attributes["exported_instrumentation_source"], attributes["instrumentation_source"]) - delete_key(attributes, "instrumentation_source") - set(attributes["exported_instrumentation_version"], attributes["instrumentation_version"]) - delete_key(attributes, "instrumentation_version") exporters: googlecloud: datadog: api: site: datadoghq.com key: ${env:DD_API_KEY} service: telemetry: metrics: address: ":8888" pipelines: metrics/promethus-for-datadog: receivers: [prometheus] processors: [batch] exporters: [datadog] metrics/promethus-for-gcp: receivers: [prometheus] processors: [batch, transform/gcp] exporters: [googlecloud]
service の telemetry.metrics によって OpenTelemetry Collector の内部メトリクスを Prometheus 形式で 0.0.0.0:8888/tcp でエクスポートして、prometheus レシーバーで Prometheus 形式のテレメトリデータを収集しています。
また、Cloud Monitoring にメトリクスを転送しようとした際に「Duplicate label Key eccountered」というエラーが発生し、メトリクスデータの転送に失敗していたので、google exporter の README.md の記述を参考に transform プロセッサーで transform/gcp としてメトリクスの属性を exported_ プレフィックスをつけた属性名に置き換えています。
このようなパイプライによって、Datadog と Google Cloud の Cloud Monitoring の両方で OpenTemetry Collector の内部メトリクスが他のマイクロサービスと同様に観測できるようになりました。
今回のアプローチでは Prometheus 形式でエクスポートしていますが、前述の OpenTelemetry Collector の Observability のドキュメントでは実験的という立ち位置ですが、将来的に OTLP 形式に置き換わることが示唆されています。将来的に OTLP 形式が推奨となり、Prometheus 形式でのエクスポートが非推奨となった場合、メトリクス名もドット区切りの OTLP 形式に置き換わることが予想されるので、メトリクスデータの連続性が失われることが課題になりそうと思っています。
また、OpenTelemetry Collector のモニタリングのドキュメントでは転送時にエラーになった場合は otelcol_processor_dropped_spans や otelcol_processor_dropped_metric_points がカウントアップされるとありましたが、我々の環境ではこれらのメトリクスは生成されていませんでした。今は代替として otelcol_exporter_send_failed_spans や otelcol_exporter_send_failed_metric_points を監視するようにしています。
ヘンリーでは各種エンジニア職を積極的に採用しています。Henry が扱っている医療ドメインは複雑ですが、社会的にもやりがいがある領域だと思っています。複雑な仕組みを実装しているアプリケーションには可観測性は重要な要素です。一緒にシステムの可観測性を向上しつつ、複雑な領域の問題を解決してみませんか?
SDET / SREのsumirenです。 2023/12/21に開催されたmablers_JP オフラインMeetUpにヘンリーから登壇しました。その際の登壇内容について、こちらのエントリにサマリを記します。
当日のアーカイブは以下になります。よろしければぜひご覧ください。
イベントを運営・企画いただいた運営の皆様に感謝します。ありがとうございました。
ヘンリーは医療ドメインにディープダイブし、複雑な診療報酬制度に向き合っています。難解なドメインでお客様のペインに正しくアプローチするために、ヘンリーではドメインエキスパートが活躍しています。ヘンリーで活躍しているドメインエキスパートについては、こちらの記事も是非ご覧ください。
ドメインエキスパートの知見をサービスの品質に最大限活かすため、ヘンリーではドメインエキスパートがQAの役割も担っています。これにより、「実際には医療事務さんはこういう使い方をしない」であったり「この診察をしたときには、厳密にはこういう金額計算になる」といった業務への深い洞察をサービスの品質に活かすことを目指しています。
上記のドメインエキスパートの知見を自動テストにおいても活かすため、ヘンリーではローコード自動テストツールであるmablをドメインエキスパート中心で運用しています。
ローコード自動テストツールとはいえ、実際にmablを非エンジニア中心で運用しているケースは少ないのではないかと思います。ヘンリーでは様々な工夫をしながらこうした尖った運用を実現し、自動テストの領域においてもドメインエキスパートの知見を活用することに挑戦しています。
イベントでは、こうしたドメインエキスパート中心のmabl運用について、組織やプロセスの設計における工夫の事例をシェアさせていただきました。
ヘンリーの組織にはまだまだQAの課題があります。
ドメインへの理解度が高い一方、QA自体の専門性が不足しているため、一般的に検知しやすいバグが摘出できないこともあります。また、QA専任の方はいないため、長期的な品質戦略や計画を立てたり、品質のボトルネックを積極的に特定して課題解決を推進することもできていないと言えます。
制約の中で、ドメインエキスパートやSDET中心で定例や改善活動を回し、今自分たちにできるQAにチームで向き合っているというのが現状です。
そうした背景もあり、ヘンリーでは1人目のQAエンジニアを募集しています。ドメインエキスパートとQAエンジニアの専門性をシナジーさせることでサービスの品質をさらに高めたり、プロアクティブに品質戦略に臨む組織体制を作っていきたいと考えています。
興味を持っていただけましたら、ぜひカジュアル面談でお話させてください。よろしくお願いいたします。
ヘンリーで SRE をやっている ![]() id:nabeop です。
id:nabeop です。
そして、この12月、さらにシェアを増やすべく、有志の企画によりヘンリー史上初のアドベントカレンダーを行うことになりました。 Advent Calendar 2023をやるので2023年を振り返ってみます - 株式会社ヘンリー エンジニアブログ
そろそろ社員数も増えてきたし、アドベントカレンダーができるんじゃないか?という Slack の自分の分報チャンネルでつぶやいたら、あれよあれよという間に全社的な取り組みになって、25日間の枠が埋まりました。
ということで、今年のうちにアドベントカレンダーの感想のエントリを書いてみます。
アドベントカレンダーを始めるにあたり、せっかく2人の VPoE がいるので、開始と終了はそれぞれに担当してもらいたいと思っていたところでした。この一年で組織とサービス規模の両面が大きくなったというのが改めてわかりました。来年はもっと拡大する見込みなので、引き続きやっていきたいですね。
双方のソフトスキルに依存する話なので、むずいですよね。チームでも毎朝30分の Standup ミーティングをしていて、タスクの困りとかはそこで会話しているけど、自分が相手の困りを引き出せているかというと自信ないです。
僕は今年の6月にヘンリーに入社したので今年の後半しかいなかったですが、導入予定の医療機関様がすごいスピードで増えていく様子をみていました。来年も Henry をたくさんの医療機関様に導入いただいて、医療の DX 化を進めていきたいですね。
大きい会場で緊張しているところをダジャレで助けてもらいました!!だいたい発言から数分で面白いダジャレがついてくるので、瞬発力がすごいなと思っています。
あと、エントリのタイトルで「完走の感想」とダジャレにしていたので、カスタム URL も遊び心が欲しいなーと Slack のチャンネルでつぶやいたらシュッと「otucalendar」といい感じなワードを出してくれたので助かりました。
浸透圧だけでここまで語れるのすごすぎないですか!?
弊社の特徴として、Henry を導入いただくにあたって、医療期間様の業務の深いところまで理解して、導入の価値を最大化することを目指しています。今まではカスタマーサクセス (CS) という職種でしたが、より実態に合わせるようにパートナーグロース (PG) と職種名を変えました。その背景と今後の展望まで書かれているので、興味のある方はぜひ読んでもらいたいですね。
入社していきなりたくさんの医療機関様にインタービューをして、その内容が日々 Slack にながれてきて、とても頼もしいなーと思ってみていました。
数ヶ月くらい技術勉強会をやってきて、Slack でも「これギベンで話したら面白くないです?」みたいな会話がされていて根付いてきたなーと思っています。こういう取り組みはどんどんやっていきたいですね。
一緒に OpenTelemetry の導入をしているんですけど、このエントリを読んで思ったよりもハマりポイントがあるなーと改めて思いました。ただ、問題に向き合うことで OpenTelemetry のトレースのプロパゲーション周りの理解が深まってよかったです。
PC で仕事をすることが普通だと思っていたけど、業種によってはそうではない、ということが驚きでした。Henry を導入していただくことによって、DX 化の促進にもなると嬉しいなと思いました。
blogsync は個人的にも使っているので、メンテしてもらってありがたい!このブログも blogsync での自動化をしたいなーと思って途中まで作業していたけど、忙しくて手が動かせてないことを思い出しました。
PG の業務範囲は広いので、キャリアパスが多岐にわたるということですね。この中から各自にあったキャリアパスで成長してもらえそう。
PG という職種についてのエントリを読んでいたので、PG として活躍されている人の実体験も合わさって、PG という職種の解像度があがりました。
いつもお世話になっています!!!いろんなところに認知負荷があるんだということを知れました。
退路を立ちつつ、ちゃんと有言実行していてかっこいい!!!開発チームでレセプト関係の会話を聞くことはありますが、複雑すぎて理解できる気がしないので、プロは凄いなーと思っています。
一時期は朝にコーヒーを飲まないと夕方には頭痛がするくらいコーヒー好きな状態でしたが、淹れ方はここまでこだわれるとは思ってもなかったです。深い世界だ。
仕事でも関わることが多くて、関わるたびに圧倒されるくらい優秀な人です。そんな人が「自分がワントップにならなくて済むぐらいに激強メンバーが揃っている」という組織、どこだろう...?
弊社では Kotlin がメインの言語になっているけど、僕自身はあんまり触れていないので、まずは気軽に Kotlin Scripting で色々試行錯誤してみるのもいいかなーと思いました。
一年で1.5倍の組織規模になったけど、その時々でより良い組織になるように色々されていてありがたいです。あと、猫が可愛い。
複雑なドメインを扱っていてつらみはあるけど、課題が複雑であるほど、解いた時の達成感は大きいですよね。SRE としても複雑な問題に日々直面していますが、直面するたびにわくわくしています。
便利になるように個人的に作っていたツールがプロダクトに取りこまれてめっちゃいいですね。
会社の DemoDay で実際に動いているとこを見せてもらった時にも思ったけど、技術説明とかも含めて解説されると、これだけのモノを個人でガッと作っちゃうの、すごくない!?となっちゃう
異なる医療ドメインのキャッチアップをプログラミング言語の習得に例えられてイメージしやすかったです。
僕も最初に複雑な医療ドメインをキャッチアップすることに苦労したけど、こういうアプローチもあるんですね。とくにチャンキングの件が参考になりました。
アドベントカレンダーのいくつかのエントリで触れられていた通り、ヘンリーは今年だけで組織が1.5倍になるほど拡大したけど、来年は今年よりも拡大する見込みなので色々考えることがある!自分にとっても経験したことがない規模で拡大するので今からわくわくしています。
最初は25日分のうち8割くらい埋まれば御の字かなーと思って発案したけど、蓋を開けてみたら、あっという間に25日分が集まって、2トラック分やるか...?みたいな会話もされてびっくりしました。また、職種にかかわらずいろんな方に参加してもらえたことも嬉しかったです。エントリの内容も趣味から仕事までバラエティに富んでいてヘンリーのメンバーらしいアドベントカレンダーになったのではないかと思っています。
ヘンリーは来年も拡大しつづけているので、来年のアドベントカレンダーは本当に2トラック分になるかもしれないですね。
そんなヘンリーではさまざまな職種で募集をしています。一緒に日本の医療の DX 化を推進していきませんか?
VP of Engineeringのid:Songmuです。このエントリーは株式会社ヘンリー Advent Calendar 2023、最終日の記事です。
ヘンリーは今年、本丸の病院向け電子カルテ・レセコンシステムのサービスを開始し、順調に事業が立ち上がっています。早くも業界でもユニークなポジションを獲得し、注目度も上がっています。
そんな中アクセルを踏む決断をし、来年は組織として100人採用に踏み切ることになりました。
ビジネスを勝ち切るためのアクセルを踏むフェーズにおいて、自分がVPoEとして採用や組織開発に主体的にチャレンジできる立場にいることは喜ばしいことです。その中で自分が考えていることを書き出していきます。
「面白法人でありながら上場することに意味と面白さがある」
2011年頃、当時私が所属していたカヤック社で代表の柳澤さんが度々こう言っていました。カヤックとして上場を意識し始めた頃です。もともと上場を狙っていた会社ではなかったこともあり、上場は多くのイチ従業員達にとってはどこか他人事で、正直その意義への実感は薄かったと思います。そんな中、その意義を定期的に言葉にし、社員にも考えてもらう示唆を与えていたのは印象に残っています。
世界の片隅で面白そうなことをやっていても自己満足に過ぎず、会社の面白さとそれに伴う価値をもっと広く世に問う事に意味があり、その一つとして上場がある。私はそのように解釈していました。
また、DeNAの南場さんの「不格好経営」に以下のような一節があります。「公器」と言う言葉を私が意識するようになった一節です。
南場カンパニーにしたいのか、それとも公器として育てていきたいのか (中略) 熟考の上、決意した。社会の公器として発展させるために責任を果たす 南場智子. 不格好経営 (p.143) Kindle版.
公器と公開会社であることは異なりますし、ここでその関連が語られているわけではありません。ただ、イチ企業が公器足るためには、公開会社であることは多くの場合必要条件でしょう。
自分たちに公共性の高いミッションがあり、その意義を信じていて、広く世の中に価値をもたらしたい、つまり公器足りたいのであれば、その正当性を公に問う必要があります。個人の自己満足や局所的な箱庭作りに陥っていないかも世の中に評価してもらうということです。上場して公開会社になることは、そのための手段でもあります。
公開して自分たちの価値を問う、というのは実はOSSの精神にも類似する部分があると感じます。
ヘンリー社も「社会課題を解決し続け、より良いセカイを創る」「人類の医療・介護インフラを創る」というミッションを掲げているので公器を志向しているはずです。
スタートアップにそういう志がある場合、単純に少数精鋭での高い利益率を追い求めるだけだけではなく、その絶対量も意識しないといけません。そのドメインやマーケットに変革を起こすのであれば、広くその領域を取りに行く必要があるからです。現実問題としてWinner takes allの傾向は強く、新規領域で先行者利益で突破するにしても、既存領域でゲリラ的にシェアを拡大するにしても、スピードが必要です。そうしないとマーケットを育てられなかったり、他社に押し負けたりしてジリ貧になる可能性が高いのです。
急成長が必要です。
私も何度か経験がありますが、事業やプロダクトが立ち上がった時期の熱狂は何事にも代えがたい快感です。特に、プロダクトリリース後に手応えを感じ始めた頃などは、それまでの苦しみがあった分、その喜びは格別です。
まだ少人数で、メンバー間に部活や研究室のような一体感があり、ミッションも何も言わずとも行き届くツーカーの関係が築かれています。
また、全員が事業やプロダクトの全貌を大体把握しており、プロダクトのどこを変更すればどのような影響があるか大体想像でき、自分の決断の結果がダイレクトに自分に返ってくるので自分ごと化しやすい。そういう全能感があります。
この、一体感と全能感が、この時期の熱狂の源泉です。
ただ、この段階はあくまでもスタートを切れただけであり、この後は急成長をする必要があることは先に述べました。そして、組織が大きくなるにつれて熱狂は薄れていってしまうものです。
また、この熱狂の快感にやられてしまった人間は、全員に全貌を把握してもらいパワープレーでゴリ押すことを志向しがちです。認知能力の高いメンバーを揃えて一つのチームでなんとかしようとする。システムの話だけで言うと、何十人も開発者がいるのに、一つのモノリシックなシステムを触らせるようなことです。私自身にもそういった傾向を自覚しています。
これまで大企業、百人弱から数百人規模のベンチャー、スタートアップなどに関わる中で、私は熱狂が失われる局面を多く見てきました。以下は自分の周りで起きたことや起きそうになったこと、友人から聞いたことの一部です。
多くの人が全体観を持てず、全体最適を考えて行動できなくなり、局所最適に陥ることで起きる問題がほとんどです。
私がこれまで所属した組織はいずれも自分を育ててくれて愛着がありますし、今でも仲良くさせてもらっています。幸せなことに、どの組織も悪人はいなかった。他人を蹴落として自分の利益とするような人はいませんでした。それぞれがベストを尽くそうとしていた。ネガティブなことだけ羅列したので印象が悪くなり申し訳ないですが、実際はかなり上手くやっていたと思います。どこも事業継続しているし、上場している企業もあります。
ただ、それでも個人的に歯がゆかったり、悲しい思いをすることも多くありました。当時の自分が、当事者として関わりきれなかったり力不足だったことも反省材料として残っています。
ヘンリー社では、VPoEとして組織開発の当事者としてそれらの課題に主体的に関わるチャンスを得られています。これは私のキャリアにおけるリベンジの機会でもあるのです。
健全に組織を拡大しつつ熱狂を失わないようにできるか、組織が大きくなる中で文化が壊れないようにしつつも事業の成長速度と人が増える速度を同じ角度に保てるか、それらの実現が私のヘンリーにおける大きな野望の一つです。
ヘンリーは事業とプロダクトを大きく伸ばしており、周囲からも急成長を期待されています。野望を実現する舞台が整っているし、実現させないといけない局面でもあるのです。
結局、組織拡大においてパワープレーは持続性に欠けます。組織やシステムを権限分離して、独立性や自律性を高める話には向き合わざるを得ません。
なるべくシステムはモノリシックにして、単一チームでのパワープレーを維持したかった自分にとって、チームトポロジーは身につまされる本でした。認知負荷の限界があることを認め、それをどのように構造的に解決するか、という視点をこの本から得られました。
しかし、認知負荷の存在を認めつつもどう立ち向かっていくかがチームトポロジーなのであって、認知負荷に日和ってブレーキを踏み合っていたら意味がありません。局所最適に陥らず、チームが増えてコミュニケーションパスが複雑化してもスピードを落とさないようにしないといけません。
何事も境界をきれいに切ろうとすると、絶対に隙間が生まれてしまいます。境界部分のオーバーラップとインタラクション設計が重要です。人間、境界が見えてしまうと、どうしてもその手前でブレーキをかけることが増え、そこにポテンヒットが集まってしまう。組織においてそれが起こることは「技術の創造と設計」の以下の図がよく表しています。

システム設計におけるレイヤードアーキテクチャーも、境界をきれいに切り分けようとすると、逆に隙間だらけで融通の効かないスカスカのバームクーヘンになる危険性があります。
チームトポロジーもレイヤードアーキテクチャーも大事なプラクティスではありますが、形式張って進めすぎると、多くの衰退した大企業が歩んできた轍を踏むことになりかねません。組織の「成熟」を早め、いわゆる大企業病を加速させてしまう諸刃の剣であるように思えるのです。
私としては、境界の手前でブレーキを踏まず、その上での健全な衝突が発生することを良しとしたい。同時にお互いにストレスを抱え合うような、感情的で無駄な軋轢が起きてほしくないとも思っています。
このようなスタートアップが抱える一種の矛盾に立ち向かうために、個人的に意識している考えを幾つか挙げて行きます。
人間には状況を把握するために二項対立で物事を整理したがる傾向があるように感じます。これはある対象が有害か無害かを瞬時に決断できないと自身の生死に関わったような太古の時代ならともかく、現代では悪癖とも言えます。これは名著「知識創造企業」で似非ダイコトミーとも表現されています。
先に述べたように、組織拡大においては、チームを分割して自律性と独立性と担保しつつも、それぞれが全体観を失ってはいけません。また、少数精鋭の方がスピードが出せるのは間違いないので、精鋭部隊を維持しながら組織を大きくしなければなりません。
それに限らず、スタートアップでは多くの困難な両立を実現する必要があります。「要はバランス」とか言わずに、まずは両取りを考えなくてはいけません。「知識創造企業」ではダイナミックな統合と言われているものです。「要はバランス」とかいい出した時点で二項対立に囚われており、その軸でしか考えられなくなるのです。
このエントリーのタイトルの、熱狂と急成長の両立も、私が実現したい困難な両取りのチャレンジです。
スタートアップはそれ自体、内集団バイアスが高まりやすい傾向があります。そして、チームが分割され、他チームと断絶されたときにチーム内での内集団バイアスも高まりやすくなります。場合によっては外への価値提供よりも自分たちを守ることが優先され過ぎ、ともすればカルト的にもなり危険です。
組織は内向きになりすぎず、外とのつながりを常に意識しなくてはいけません。企業やチームにおいては、自分達の業務や活動が最終的にどのような顧客や世の中への価値提供につながっているのかというバリューストリームを意識するということです。
これは、全チーム、全社員が意識できることが理想です。自分たちは守りの仕事だから関係ないなどと思ってはいけないし、そう思われてしまうのであれば組織設計の失敗です。
多くの技術トレンドがそうであるように、分散と集中が螺旋のように繰り返されます。組織においても同様で、チームを分割するだけだと、無駄にチームが増えていくだけです。時には統合して分割し直すプロセスも必要でしょう。
これは、書籍「両利きの経営」のタイトルそのままです。既存事業を深めて伸ばすための「知の深化」と、新規事業のイノベーションを生み出すための「知の探索」を両立する考え方です。この「深化」と「探索」の両軸の考え方は、普段の組織の業務設計の中でも応用が効く有用な分類だと感じています。
独立性と自律性を高めた結果、無味乾燥な業務にまで分割されたら、それは果たして業務を行う当人は幸せでしょうか。具体例としては過度なマイクロサービス化はエンジニアのモチベーションを奪いかねないといったことです。
これを私は「銀河鉄道999」からあやかって「鉄郎のネジ問題」と呼んでいます。色々考慮して行き着いた先が、無味乾燥で代替可能なパーツになることだとしたら笑えない話です。それが本当にあなたの欲しかった完全無欠な機械の体なのですか?という話です。
チームを分割するにしても、チームメンバーが創造性が発揮できてバリューストリームへの接続を意識できるレベルにとどめ置くべきでしょう。

私は仕事においてお見合い落球が発生することが大嫌いです。そういう狭間に落ちそうになっているボールを積極的に取りに行く人が評価されて欲しいと思います。
そういう狭間の業務は、多くの人の死角に入っていたから狭間に落ちそうになっている訳で、目標設定のスコープからは漏れているものです。なので、目標に囚われすぎると、そういった業務を拾いに行くインセンティブはありません。これもまた悪しき局所最適です。
目標設定は大事ですが、それに囚われすぎ、全体最適な行動を取ることが称賛される風土作りや、インセンティブ設計をしたいと考えています。
これらの考えを元に、これまでとこれから私がどのようなアクションを取っていくかについて述べ、このエントリーを締めようと思います。
組織の急成長の当事者として立ち会え、貢献できることは充実感が高く、得難い経験になるでしょう。しかし、時には痛みが出ることもあるでしょう。成長痛と言われることもありますし、そんな綺麗事では済まないケースもあるかもしれません。
そんな困難な状況ではミッションへの共感と高め、全員がそれを実現したいと思えるか、思ってもらえるかが大事です。最初の方に述べたように、公共性の高いミッションを掲げ、公器足るために急成長を志向しているわけですから、ミッションに共感して納得してもらう必要があるからです。
そんなチャレンジングな状況を楽しめるかどうかも大事です。そういう状況を乗り越えた先にはそれぞれのメンバーの成長もやってきます。それぞれの社会人としての価値も上がり、より面白くチャレンジングでリターンのある仕事がやってくるようになるはずです。
生存者バイアス的な部分がありますが、だからこそ、全員が生き残れるように、誰かに負荷が偏らないように、一丸となって乗り越えられるようにインセンティブ含めて設計する必要があります。
また、行動指針としてのバリューを浸透させていく必要があります。各人のベクトルを合わせて合力を最大化するためです。
その浸透の一環として少し前に社内でバリューについて考えるワークショップを実施しました。
ミッションもそうでありますが、バリューは言葉だけだと曖昧です。そして「エラい」人が「分かっていない」人に説明を尽くそうとするほど、説明された側からすると、他人から押し付けられたモノ感が強まり、自分ゴト化が困難になります。
こういったものは実は曖昧でよく、各人が解釈することで、コンテキストが醸成されます。バリューは特に、ミッション実現のために、メンバー各位が大事にしたいことが抽出されたものでもあるため、全員にオーナーシップを持ってもらう必要があります。
メンバーに解釈してもらわずに放置すると、バリューはすぐに形骸化します。バリューを自分たちのものだと思ってもらえるように、定期的なワークショップなどを通してメンテナンスやアップデートをしていきたいと考えています。
1978年、ホンダのトップは「冒険しよう」というスローガンで新しいコンセプトカーの開発を打ち出した。 (中略) ホンダのトップが与えた使命の曖昧さは、開発チーム内に混乱を引き起こした。逆説的に聞こえるかもしれないが、この混乱が実は、全く新しいクルマをめざすというきわめてはっきりした方向感覚をもたらした。 野中 郁次郎; 竹内 弘高. 知識創造企業(新装版) (pp.38-39). 東洋経済新報社. Kindle 版.
私が、ヘンリーの中で持っているメインのミッションが、エンジニア含めたプロダクトチーム全体の採用です。
採用においてはそれぞれの専門性に加えて、先に述べたミッション・バリューへの共感が大事です。ミスマッチによる採用失敗のダメージは大きく後を引くため、採用基準は妥協してはいけません。
私は、エンジニア採用を中心に採用には10年近く携わってきましたが、自分が採用に関わったエンジニアについては、失敗したことはほぼ無いと思っています。これは自分の中での自慢です。
ただ、一年で100人を超えるような採用ペースには携わったことはありませんし、そういうペースで多くの魅力的な人材を採用している企業に対して羨望の眼差しを向けてきました。
優秀な人が綺羅星のように集まり、それぞれがコラボレーションして思いもよらぬ価値を生み出せる環境は魅力的です。それを実現したいと考えています。
「評価」というとアレルギー反応を起こしてしまう人が多いと思いますが、大事なのはフィードバックサイクルです。それを設計して改善し続け、それを回して経験学習を促進させ、個人や組織の成長につなげることです。
ここでも大事なのはミッションに共感し、バリューに沿った行動が取れているか、そして、各人がバリューストリームのどこにいるかを意識することだと考えています。外向きへの価値提供が意識されないと内集団バイアスが強まる危険性があることはすでに述べました。
自分たちがどのような価値を生み出しているかを意識し、それを表明する。それに対して周りからフィードバックをもらう。フィードバックには当然称賛も含まれます。その繰り返しが大事です。
それらを踏まえた評価設計にも取り組んでいきますが、あまりにも大きなテーマなので、それはまた別の機会。
最後に自戒ですが、組織開発的なアクションはやりすぎてしまうことも多く、得てしてオーバーエンジニアリング的になりがちです。プロダクト開発における作りすぎ、いわゆる「ビルドトラップ」と言われる事象が発生しやすいのです。
プロダクト開発がそうであるように、やった方が良いことはたくさんありますが、その中で今やるべきことは一握りしかありません。また、内向きな指向が強まると、自分たちの行動を正当化しすぎる内集団バイアスにもつながり兼ねません。組織開発の営みも、やはり組織の体外的な価値提供にどのようにつながっているかを意識することが大事です。
自分たちのやっていることを正しいと信じて行動しつつ、それを常に疑い続ける。そのように矛盾を内在していきたいと私自身は考えています。
本エントリーは、ヘンリーという有力な舞台の上で、私の過去に対するリベンジを果たしたい、という私の個人的な物語でもありました。スタートアップの熱狂を維持しながら中身の伴った急成長を実現したいし、世の中に価値を提供し続けられる組織づくりをしたいと考えています。
ヘンリーはまだ100人に満たないスタートアップですが、事業が立ち上がり、マーケットにも受け入れられ始めています。メインの仮説検証は終わり、価値を届けるサイクルを回し始められています。事業の確度も高くなり、各人が価値提供を実感してフォーカスしやすい状況です。
自分たちでも信じがたいことですが、ヘンリーは病院向け電子カルテ・レセコン領域において、信じられないくらいユニークで有力なポジショニングができています。そしてまだまだ課題は山積みです。カジュアル面談に来ていただいたらその辺りのお話をさせていただきます。
このような状況の中で、一緒にヘンリーで世の中への価値提供に取り組んでくれる方を募集しています。単に興味があって話してみたいというのも歓迎なので、まずは連絡をお待ちしています。

