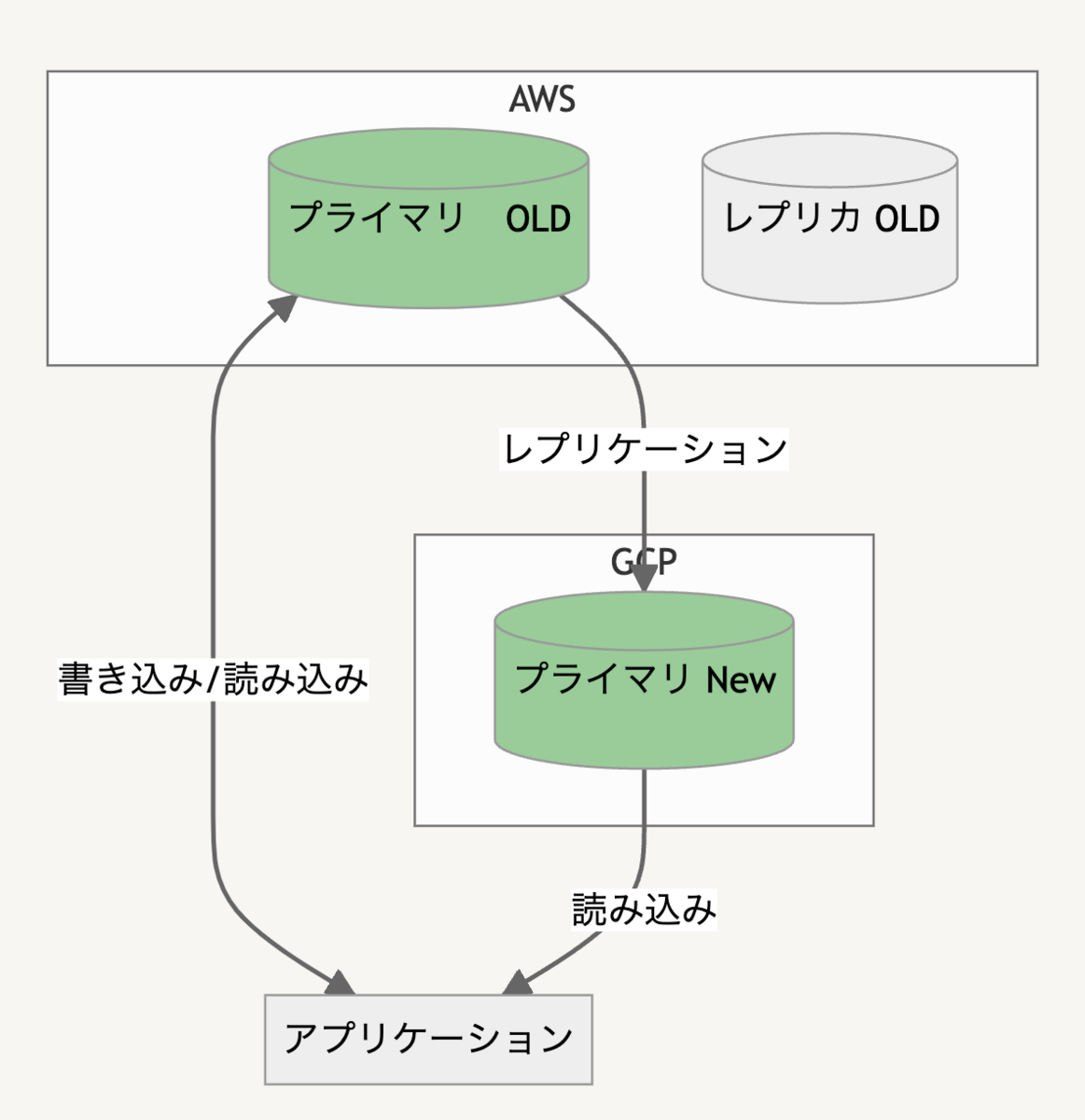
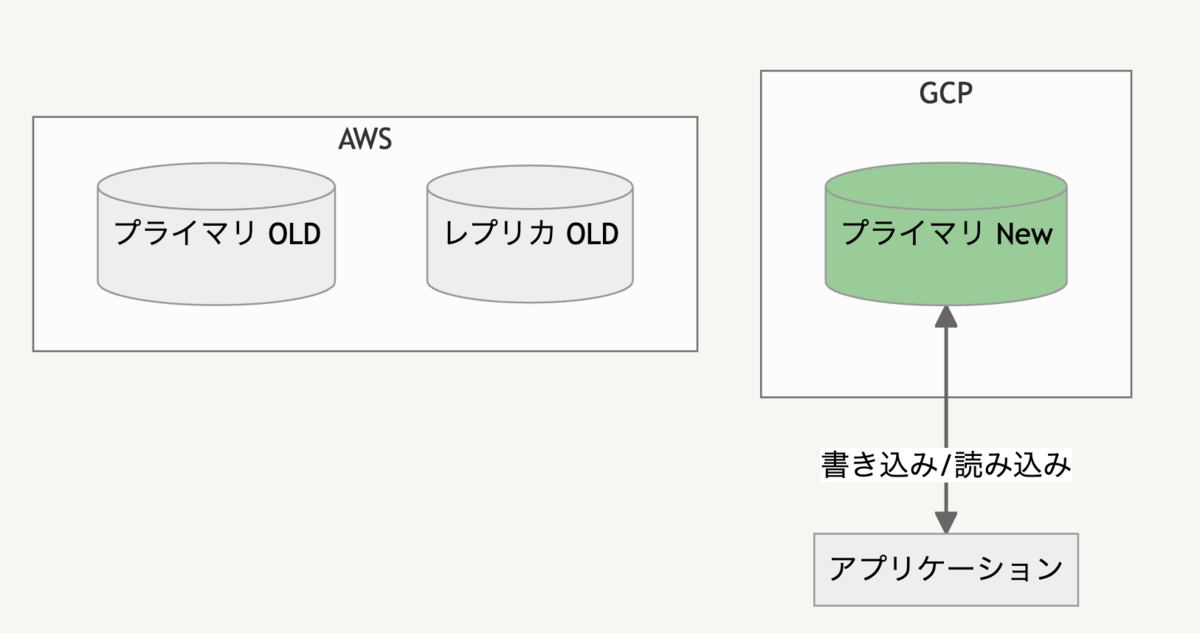
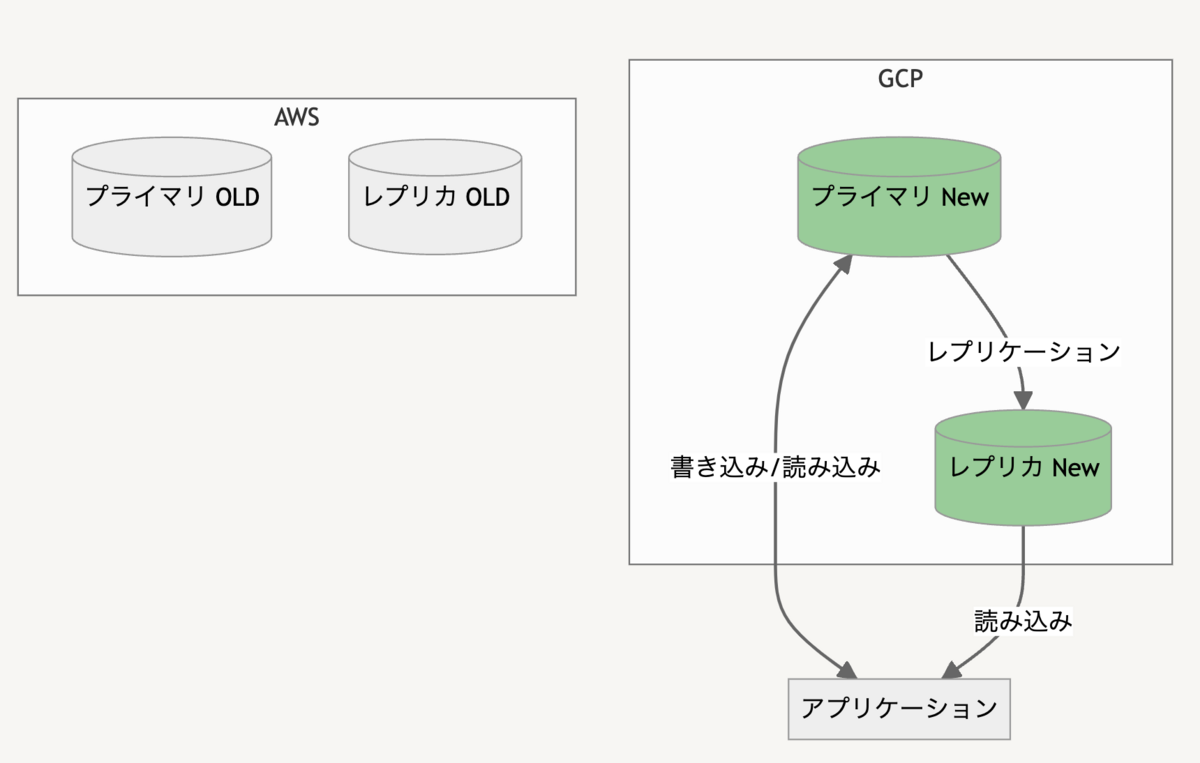
JX通信社CTOの小笠原(@yamitzky)です。4月19日に「AIコンペティション」を社内勉強会として開催したので、その取り組みを紹介します。
開催の目的
JX通信社では、AIで世界中のリスク情報を解析する「FASTALERT」という製品を開発しています。ただ、普段からエンジニアの全員がAI開発に取り組んでいるわけではなく、フロントエンドやバックエンドなど、AI以外のコンポーネントを開発しているエンジニアも多くいます。
数年前まではDeep Learningなどの高度なAIを活用した製品開発は敷居の高いものでしたが、 近年ではAutoMLやAmazon SageMakerのようなマネージドなAI開発の仕組みや、生成AIの台頭など、AIを使ったサービス開発の難易度は日に日に下がっています。
そこで今回の勉強会では 「普段AI開発に関わってない人」をターゲットに、AIの分野や、AIを使ったプロダクト開発を身近に感じてもらうこと を目的として、AIのコンペティションを開催しました。
テーマ
なるべく実務に近いもの...ということで、弊社のニュースアプリ「NewsDigest」のタブ機能の改善をテーマに選定しました。NewsDigestには話題ごとのニュースを見れる機能(タブ機能)があります。しかし、「社会」「エンタメ」などをニュースをタブに分類するモデル自体は、やや古いものでした。
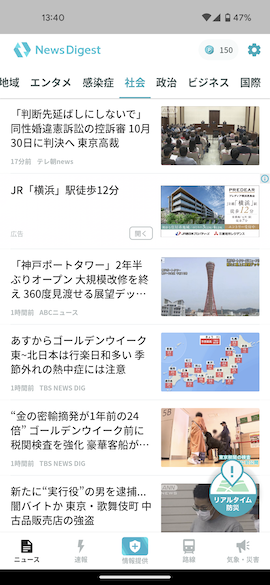
今回のコンペは「ニュース記事を解析し、タブを分類するモデルを作る」というテーマで開催し、タブ分類の正解率を競いました。
タイトルには「生成AI」と書きましたが、 手法自体は生成AI(プロンプト)でも、古典的な機械学習的手法でも、ノーコードでも、ルールベースでもエクセルでも何でもOK としています。今回の記事では「モデル」という表現に統一します。
事前準備
コンペは2時間の限られた時間で開催したため、勉強会の事前準備として、以下のものを用意しています。*1
- 学習用データ・・・後述するサンプルコードでは利用していませんが、パラメータの学習を要するAI用に一応用意しました
- 評価用データ・・・各自が作ったモデルの精度をポータルサイトで確認するためのサンプルデータ
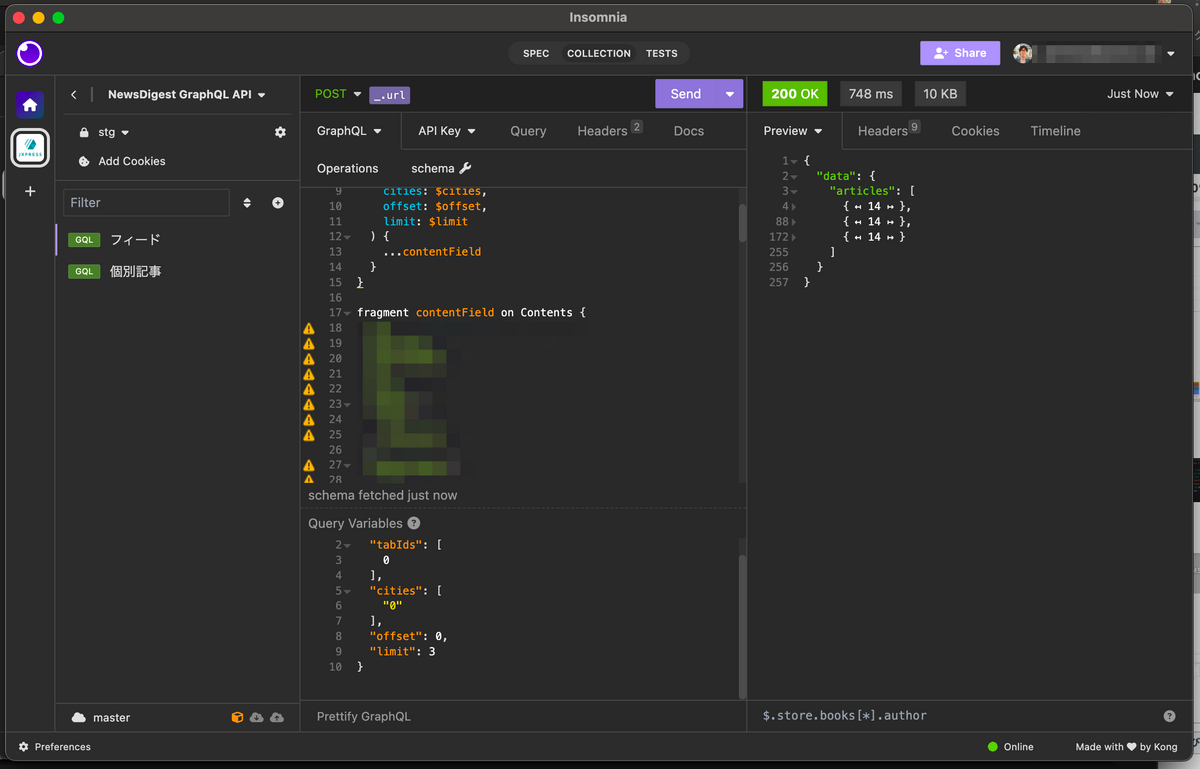
- ポータルサイト・・・NewsDigest風のUIで定性的な精度チェックをしたり、精度を定量的に確認するためのWebサイト
- Pythonのサンプルコード
「実サービスでの運用」という点に近づけるため、次のような工夫しました。
- あえて評価用データの正解ラベル等は開示しない。実際には自分で正解データを作らないといけないことも多いため
- ポータルサイトでの定性的な確認をしやすいようにした。定量データが実際サービスで求められる品質や体験と乖離することもあるため
ポータルサイト
Gemini 1.5 Pro にお願いをして、ポータルサイトを作りました(Next.js/bun/Tailwind CSS/Cloud Runを利用)。解析結果のCSVをアップロードすると、タブに分類された記事を定性的に確認したり、精度チェックをしたりすることができます。このポータルサイトを見て、プロンプトやパラメータのチューニング結果のうまく行った/行ってないが確認できるようになっています。

サンプルコード
スムーズに体験してもらうために、サンプルコードを用意しました*2。あえてプロンプトを雑に作ったり、軽量な(精度が高くない)モデルを使ったりしています。実際、text-bisonのモデルは指示を無視して「ゲーム」や「生活」など、存在しないタブを誕生させ、スコアを下げてしまいます。プロンプトエンジニアリングの苦しみを味わってもらいました!
import vertexai from vertexai.language_models import TextGenerationModel # LLMのライブラリ初期化 vertexai.init() parameters = { "candidate_count": 1, "max_output_tokens": 1024, "temperature": 0.9, "top_p": 1, } model = TextGenerationModel.from_pretrained("text-bison") # 指示を自由にカスタマイズ instruction = """あなたはニュース記事を判定し、カテゴリーを予測するAIです。記事のタイトルを受け取ったら、その記事のカテゴリーを推定してください。 カテゴリーは社会、政治、経済、国際、エンタメ、スポーツ、テクノロジーのどれかです。 記事のタイトルは、改行して複数渡されることがあります。その場合は、改行してそれぞれの判定結果を出力してください""" # train.csvを元に、具体例をいくつか書いてあげる examples = """input: 東北道でトレーラーとトラックの追突事故 2人の救出活動つづく 群馬・館林市 北海道 広尾町長選は新人の田中靖章氏が初当選 output: 社会 政治 """ # 10記事ずつまとめて処理し、AIに予測させる for i in range(0, len(titles), 10): input_text = "\n".join(titles[i:i+10]) response = model.predict( prompt=f"""{instruction} {examples} input: {input_text} output: """, **parameters, ) print(response.text)
結果
当初のサンプルコードのモデルだと65.9%の正解率でしたが、優勝者は81.62%でした 🎉

優勝者コメントです。
タブ分類の工夫がスコアという形で可視化されて面白かったです! 時間があればプロンプト自体のチューニングもいろいろ試してみたかったです 【主に工夫した点】 生成AIの賢さによって精度も変わるだろうと思い、ChatGPT4-turboを使ってみることにしました。 予期しないカテゴリ(タブ)が返ってくる事を防ぐためFunction callingのレスポンスをEnum型で定義したことで安定して分類出来たように思います。
他にも「実際にAIを使う時の雰囲気掴めて良かった」といったコメントもあり、開催してよかったです。
今回は社内勉強会でのコンペ開催を通じて、AI開発の導入を体験していただきましたが、より良いプロダクト開発に役立てていけると良いなと思っています。