気合いで実装、どうもかわしんです。
この記事は Rust Advent Calendar 2023 の6日目 兼 情報検索・検索技術 Advent Calendar 2023 の 6 日目です。
Rust で SQLite をフルスクラッチで実装しています。
なぜ SQLite を Rust で再実装しようと思ったのかについては以前の記事で紹介しています。一言で言えば、誰も Rust で SQLite を書いている人がいなかったからやってみたのですが、そもそも SQLite が強すぎるということが再実装しているうちにわかってきて絶望しています。
4 ヶ月前にこの記事を書いたときは簡単な SELECT 文しか実行できなかったのですが、現時点では SELECT, INSERT, DELETE 文をサポートし、expression についても比較などの一部をサポートしています。こんな感じで CLI から利用することもできますし、ライブラリとして組み込むこともできます。
$ git clone https://github.com/kawasin73/prsqlite.git
$ cd ./prsqlite
$ sqlite3 tmp/sqlite.db
sqlite> CREATE TABLE example(col1, col2 integer);
sqlite> CREATE INDEX i_example ON example(col2);
sqlite> INSERT INTO example(col1, col2) values(null, 1);
sqlite> INSERT INTO example(col1, col2) values(10, 2);
sqlite> INSERT INTO example(col1, col2) values(1.1, 3);
sqlite> INSERT INTO example(col1, col2) values('Hello prsqlite!', 4);
sqlite> INSERT INTO example(col1, col2) values(X'707273716c697465', 5);
sqlite> .quit
$ cargo build && ./target/debug/prsqlite tmp/sqlite.db
prsqlite> SELECT * FROM sqlite_schema;
table|example|example|2|CREATE TABLE example(col1, col2 integer)
index|i_example|example|3|CREATE INDEX i_example ON example(col2)
prsqlite> SELECT * FROM example;
|1
10|2
1.1|3
Hello prsqlite!|4
prsqlite|5
prsqlite> SELECT col1 FROM example WHERE col2 == 4;
Hello prsqlite!
prsqlite> INSERT INTO example(col1, col2) VALUES (123, 6);
prsqlite> INSERT INTO example(rowid, col2) VALUES (20, 20);
prsqlite> INSERT INTO example(rowid, col2) VALUES (6, 6);
the rowid already exists
prsqlite> INSERT INTO example(rowid, col2) VALUES (7, 7);
prsqlite> INSERT INTO example(col1, col2) VALUES ('hello', 21);
prsqlite> SELECT rowid, * FROM example WHERE col2 >= 6;
6|123|6
7||7
20||20
21|hello|21
prsqlite> DELETE FROM example WHERE col2 < 20;
prsqlite> SELECT * FROM example;
|20
hello|21
prsqlite> DELETE FROM example;
prsqlite> SELECT * FROM example;
prsqlite> .quit
今回は SQLite を再実装している上で頑張ったところを紹介していきたいと思います。
相互互換性
prsqlite は SQLite で生成したデータベースファイルで動くのはもちろん、prsqlite で生成したデータベースファイルでも SQLite が正しく動くようにすることを目指しています。そのため、SQLite のファイルフォーマット などのドキュメントや、SQLite のソースコードを読んでどのような挙動にするべきかを確認しながら実装しています。
Zero dependency
依存ライブラリを増やせば増やすほど自分のプロダクトは不安定になります。そのため、prsqlite では Rust の標準ライブラリ以外は使わないことにしています。逆にRust の標準ライブラリはそれなりに充実していて、OS ごとのファイルシステムの抽象化がされているので便利です。現在は開発のしやすさから例外的に anyhow というエラーの便利ライブラリを使っていますが、そのうち anyhow も独自のエラー型で置き換える予定です。
本家の SQLite ではもっと過激で、依存しているのは memcmp() などの 10 個の関数のみです。それを 自慢するドキュメント があります。printf() すら自作しています。残念ながら SQLite 独自のフォーマット記号があるので再実装の難易度が跳ね上がります。浮動小数点数の文字列変換 を試みましたが一旦諦める羽目になりました。
外部ライブラリを使わないので、全て手書きしています。SQL のパーサー (token.rs, parser.rs) やファイルフォーマットのシリアライザ・デシリアライザ (btree.rs, cursor.rs, record.rs) 、ページ管理 (pager.rs) 、簡単なクエリプランニング (query.rs) なども全部自作のものです。
No unsafe
Rust の大きな特徴の一つにメモリ安全があり、それゆえに Rust で書かれたコードはセキュリティ的な評価が高くなります。(The Rule Of 2)
Rust には unsafe という機能があり、そのブロックの中ではメモリ安全の検証をスキップすることで Rust の borrow checker には違反するが実際にはメモリを破壊しないコードを書くことができます。それによって複雑すぎるコードや無駄なチェックのない効率的なコードを書くことができます。(例えば copy_nonoverlapping () vs <[u8]>::copy_from_slice()) しかし、unsafe を使うことでプログラムの一部にコンパイラによってメモリ安全性が保証されていない部分ができてしまうので、unsafe のないライブラリには一定のセキュリティ的な価値があります。
prsqlite は今の所 unsafe を使わずに全てのコードが書かれています。全てのコードは Rust の borrow checker のルールに従って書かれているということです。これがなかなかしんどくて、本当は正しいコードも現行の Rust の borrow checker では弾かれてしまうこと (特にループが絡むと捕捉しきれないみたいです) があり、それを回避するために工夫する必要がありました。例えば query::Query::next()) はループの中から直接値を返すことができるはずなのですが、borrow checker はなぜかそれをエラー判定するので、一旦ループから抜けて値を返すようにしています。実際に次世代の Polonius という borrow checker で試してみるとループ内から値を返してもエラー判定はされません。
Pager はハッシュマップに保存されていますが、読み込みと書き込みの両方に対応するために RefCell<HashMap<PageId, Rc<RefCell
テスト
あとで手戻りをするのが嫌なので、テストはたくさん書いてます。コンポーネントごとのユニットテストもですし、全体の統合テストも書いています。体感 3 分の 2 はテストな気がします。
将来的には本家の SQLite のテストケース も流用できたらいいなと思っていますが、まだサポートしている SQL 文の種類が少ないのでできていません。
なるべく速い実装
パフォーマンス改善は後回しにしても、パフォーマンス改善するときはなかなか来ないですし、実際に改善しようとしてもどこをすればいいかを探すのは大変です。そのため、実装の複雑さが増さない限り最初から最適なコードを書くことが大切です。
僕は速い実装にするために この記事 でも紹介したように以下の 2 つのことを気をつけています。
まずは、無駄なことをしないことが大切です。メモリコピーの量やメモリアロケーションの回数もなるべく少なくするべきです。
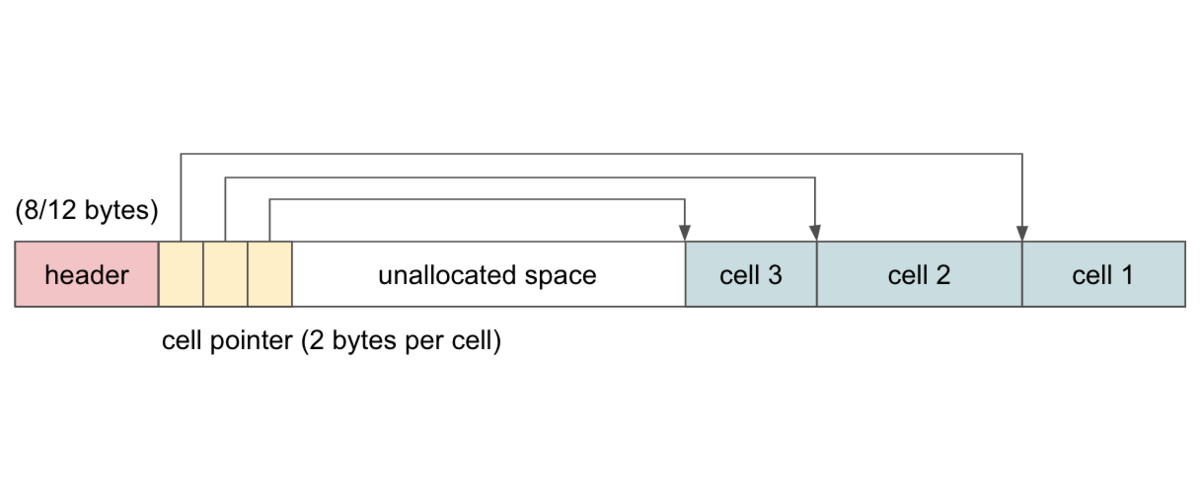
次に、条件分岐を避けることです。条件分岐は分岐予測が外れたときのペナルティが大きいのでなるべく条件分岐をせずにコードが書けると良いです。僕はなるべく if 文を使わずに書くことができないかを意識しています。SQLite では、ページのヘッダサイズの計算を以下のように行なっていますが、
first = hdr + ((flags&PTF_LEAF)==0 ? 12 : 8);
prsqlite では以下のようにして条件分岐をなくしています。
/// The btree page header size.
///
/// * Returns 8 if this is a leaf page.
/// * Returns 12 if this is an interior page.
///
/// This does not invoke conditional branch.
pub fn header_size(&self) -> u8 {
// 0(leaf) or 8(interior)
let is_interior = (!*self.pagetype()) & LEAF_FLAG;
// 0(leaf) or 4(interior)
let additional_size = is_interior >> 1;
8 + additional_size
}
Btree の実装
SQLite の実装の中で一番めんどくさかったのは、btree の実装です。特に、データの挿入と削除です。ページの分割や削除が異様にめんどくさいです。
SQLite のおもしろ仕様 (2) : ファイルフォーマット でも紹介したように、SQLite ではインデックスは B 木 を、テーブルは B+ 木を使っています。そのため、微妙に実装が違う部分と共通する部分があります。
また全てのデータは可変長です。そのため、ページ内に幾つのセルが保存されるかは動的ですし、セルのサイズも動的です。ページを分割した時に中間のキーが何番目のセルになるのかは詰め直さないとわからないですし、中間のキーが親のページに収まるかも詰めてみないとわからないです。
最悪なのは、データの挿入でページを分割するときに 3 つのページに分かれてしまうことすらあります。
可変長のセルが入る B tree node に新しい値の追加した時の分割で 3 つのノードに分割される場合があるのに対応した。例えば、サイズ 6 のキャパシティのページに 3 と3 のセルが入っている状態で間にサイズ 4 のセルを追加する場合。
— かわしん@ソフトウェアエンジニア (@kawasin73) 2023年11月12日
普通に想定外で発狂しそうになった。https://t.co/4ACcxsnkMx
最後に
だんだん実装が大変になってきて飽きてきましたが、時々頑張ります。本家の SQLite のテストケースを流せるようになるのは大きなマイルストーンだと思うのでそこまで頑張りたいです。