【Python】LightGBM等で使用できない文字が含まれているカラムを抽出する方法
結論
以下コードで抽出できます。
def extract_special_json_chars_columns(df): # 特殊なJSON文字を検索する正規表現パターン special_chars_pattern = r'[",\[\]\{\}:]' # 各カラム名に対して、特殊なJSON文字を含むかどうかを判定 special_chars_columns = [col for col in df.columns if pd.Series(col).str.contains(special_chars_pattern).any()] return special_chars_columns # 特殊なJSON文字を含むカラム名のリストを取得 special_chars_columns = extract_special_json_chars_columns(train) # 特殊なJSON文字を含むカラム名のリストを出力 print(special_chars_columns)
エラー「Do not support special JSON characters in feature name.」が出た。
モデルのベースラインを作ろうと、雑に前処理してLightGBMにデータを突っ込んだら、以下のエラーが出ました。
LightGBMError: Do not support special JSON characters in feature name.
検索すると、カラム名にjsonの特殊文字が含まれていると、上記のエラーが出るようです。
雑に前処理した際、カテゴリ変数の中身を見ずにone-hot-encodingしたのですが、その値に特殊文字が含まれていたようです。
こういったとき、冒頭のコードを実行すると、特殊文字が含まれているカラム名を特定できます。
(真面目に前処理すればいい話ですが、そこを面倒がってこのようなことをしました。。。)
検索対象とする文字列に過不足があれば、適宜追加してください。
【Athena】開始・終了日時から、そこに含まれる時間帯を全て取得したい
結論
以下のクエリで出来ます。
WITH temp AS ( SELECT user_id , DATE_PARSE(start_datetime, '%Y-%m-%d %H:%i:%S') AS start_datetime , DATE_PARSE(end_datetime, '%Y-%m-%d %H:%i:%S') AS end_datetime FROM tb_01 ) SELECT user_id , start_datetime , end_datetime , get_time FROM temp CROSS JOIN UNNEST(sequence(DATE_TRUNC('HOUR', start_datetime), DATE_TRUNC('HOUR', end_datetime), INTERVAL '1' HOUR)) AS t(get_time)
説明
開始時刻と終了日時から、そこに含まれる時間帯を全て取得したい
以下のようなテーブルが存在していたとします。
これは、各ユーザー毎に処理の開始・終了日時を記録したログテーブルみたいなものだと考えてください。
| user_id | start_datetime | end_datetime |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 |
| B | 2023-04-20 22:10:00 | 2023-04-20 23:40:00 |
このテーブルを元に、どの時間帯で処理をしているユーザーが多いかを集計したいとします。
ただ、start_datetime か end_datetime を基準に user_id をカウントしてもやりたい事が出来ないかもしれません。
例えば、user A は、13:30~17:27 迄4時間ほど処理をしていますが、13時or17時しかカウントできなくなります。
以下のようにすれば、開始・終了日時に含まれる時間帯を全て取得できる。
その場合、冒頭で示したクエリを実行すれば、以下の結果を得られます。
| user_id | start_datetime | end_datetime | get_time |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 | 2023-04-15 13:00:00 |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 | 2023-04-15 14:00:00 |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 | 2023-04-15 15:00:00 |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 | 2023-04-15 16:00:00 |
| A | 2023-04-15 13:30:00 | 2023-04-15 17:27:00 | 2023-04-15 17:00:00 |
| B | 2023-04-20 22:10:00 | 2023-04-20 23:40:00 | 2023-04-20 22:00:00 |
| B | 2023-04-20 22:10:00 | 2023-04-20 23:40:00 | 2023-04-20 23:00:00 |
get_time 部分を基準にカウントすれば、
開始・終了日時に含まれる全ての時間帯を基準として集計できます。
WITH句「temp」内の処理は、必要に応じて行ってください。
書籍:効果検証入門[1章1.4.3]
書籍内のコードを実際に実行し、それをまとめている記事です
書籍、効果検証入門の中身を、実際に手元で実行し、それを纏めている記事です。
前回の記事はこちらです。
mashio.hatenablog.com
- 書籍内のコードを実際に実行し、それをまとめている記事です
- 1章
- 1.4.3 バイアスが含まれるデータにおいて、どの程度効果が不正に多く出てしまうかを確かめる。
- 等分散を仮定しているが、実際はそうではない様子。これでよいのかな?
- 次回は、回帰分析を用いたセレクションバイアスの低減方法あたり
書籍:効果検証入門[1章1.4.1~1.4.2]
書籍、「効果検証入門」の内容を、実際にコードを実行しながら振り返ります。
以前購入した効果検証入門は、購入後あまり間をおかず一通り読んでいました。
が、最近実務でその知識を使おうとしたところ、あまり記憶に定着しておらず、もう一度最初から読み始めかねない勢いでした。
前々から感じたことですが、インプットだけでは身になりにくく、アウトプットすることでより記憶の定着を助けると感じます。そこで、このブログも対して更新していないし、良い機会だと思い書籍内容をブログに記載していきます。
要は、ブログ作成を通じインプットした知識をアウトプットして定着させる、という目的です。
書籍に記載されている以上の内容は、あまり含まれていません
書籍の内容を手元で実行し、その内容をブログ記事として纏めていきます。
そのため、書籍内容や、著者により公開されているGitHubの内容を超える内容はあまり出てきません。
あるとしても、私自身の解釈・記憶のための、メモ程度と思われます。
その点ご留意の上、御覧ください。
効果を正しく検証するにはどうすればよいのか。セレクションバイアスが存在している中で、どのように効果を正しく検証するのか。
この書籍の内容は、おおよそ上記のとおりです。
正しく効果を測るためには、そもそも施策を行う前から気をつけるべき点がある、であったり、仮にセレクションバイアスが存在しているデータしか無い場合、どうやって本当の効果を検証するかに焦点をあてて書かれているものです。
詳しい内容は書籍を参照いただきたいですが、データ分析を生業としている方々においては、一度は通読して損はない良書と思われます。
1章
1.4.1 データ準備
施策の効果検証を行う理想的な方法、RCTについて触れています。
使用するデータは、こちらのサイトで公開されているデータです。
このデータについて、書籍では以下のように紹介されています。
データセットの説明は、以下になります。
| カラム名 | 説明 |
|---|---|
| recency | 最後の購入からの月数 |
| history_segment | 過去1年間に消費された金額の分類 |
| history | 過去1年間に購入された実際の金額 |
| mens | 0,1。1 = 顧客が過去1年間にメンズ商品を購入したことを表す。 |
| womens | 0,1。1 = 顧客が過去1年間にレディース商品を購入したことを表す。 |
| zip_code | 郵便番号を都市部、郊外、農村部に分類する。 |
| newbie | 0,1。1 = 過去1年間の新規顧客であることを表す。 |
| channel | 過去1年間に、顧客が購入したチャネルを表す。 |
| segment | 顧客が受け取った、メール内容を表す。 |
| visit | 0,1。1 = メール受信後2週間以内に、ウェブサイトを訪問したことを表す。 |
| conversion | 0,1。1 = メール受信後2週間以内に、商品を購入したことを表す。 |
| spend | 購入金額。単位はドル。 |
このデータセットは、RCTによって得られたデータ、つまりセレクションバイアスが発生していないデータになっているため、単純な集計を用いてメールマーケティングの効果を測定していきます。
library(tidyverse) library(data.table) # csvの読み込み email_data <- fread('http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv') # データ抽出 male_df <- email_data %>% filter(segment != 'Womens E-Mail') %>% mutate(treatment = if_else(segment == 'Mens E-Mail', 1, 0))
# csvの読み込み
書籍では、
email_data <- read_csv()
となっていますが、宗派の違いで data.table::fread() を使用しています。
以前Tokyo.R で、「fread が早い!」と聞いてから、使っています。
確かに、ローカルにあるcsvを読み込む際は data.table::fread() が早いと感じますが、webからcsvを取得する際はさほど変化がないと思います。まぁ、どちらでも良いでしょう。
# データ抽出
元のデータには、「メール配信なし」「女性向けメール配信あり」「男性向けメール配信あり」の3つのデータがあります。
ただ、メール配信の効果をわかりやすく見るために、「メール配信なし」と、「男性向けメール配信あり」のみのデータにしています。
この後の手順で、「メール配信なし」に比べて、「男性向けメール配信あり」の方が、売上が高いかどうか、といったことを調べていくことになります。
# treatment 毎に、指定列の平均等を計算 summary_by_segment <- male_df %>% group_by(treatment) %>% summarise(conversion_rate = mean(conversion), spend_mean = mean(spend), count = n()) # 結果の出力 summary_by_segment # A tibble: 2 x 4 treatment conversion_rate spend_mean count <dbl> <dbl> <dbl> <int> 1 0 0.00573 0.653 21306 2 1 0.0125 1.42 21307
# 結果の出力
「treatment = 0:メール配信なし」の conversion_rate が0.573%なのに対して、「treatment = 1:男性向けメール配信あり」の conversion_rate は1.25%あります。
差し引き、0.677%ptの差があり、その差がメールマーケティングの効果になっています。
同様に spend_mean を見ると、前者は0.653ドル、後者は1.42ドルとなり、差分は0.767ドル。
よって、メール配信されたことにより、購入確率も、購入金額も高くなったことがわかりました。
1.4.2 有意差の検定
メールマーケティングの有無で生まれた効果の差に関して、統計的に有意な差があるのかどうかを検証していきます。
# 購入金額のみの、ベクトルを作成 mens_mail <- male_df %>% filter(treatment == 1) %>% pull(spend) no_mail <- male_df %>% filter(treatment == 0) %>% pull(spend)
「男性向けメール配信あり」と、「メール配信なし」、それぞれの購入金額を新しい変数に代入していきます。
dplyr::pull() はあまり使ったことがありませんでした。
調べると、以下のような書き方をするのと効果は変わりがないですが、パイプ演算の中で記述できる点、処理がわかりやすい点が良いと思います。
※別の書き方
mens_mail <- male_df$spend[male_df$treatment == 1]
作成した2つの変数に関して、t検定を行います。
rct_ttest <- t.test(mens_mail, no_mail, var.equal = TRUE) # 結果の出力 rct_ttest Two Sample t-test data: mens_mail and no_mail t = 5.3001, df = 42611, p-value = 1.163e-07 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 0.4851384 1.0545160 sample estimates: mean of x mean of y 1.4226165 0.6527894
# 結果の出力
結果を見ると、mens_mail、no_mail、それぞれの平均値がmean of x、mean of y として表示されています。
また、「p-value = 1.163e-07」とp値が非常に小さい値になっていることから、帰無仮説である「平均の差は0である」が棄却され、対立仮説である「平均の差は0ではない=平均の差が異なる」が採択されました。
RCTを行ったことで、メールマーケティングの効果が正しく測れるようになり、またt検定を用いてその差が有意であることもわかりました。
1つ気になることは、t.test() の引数が、var.equal = TRUE となっていることです。
これは、「男性向けメール配信あり」と、「メール配信なし」、それぞれの購入金額の分散が同じことを仮定していることを示しています。
これについては特に書籍内で検定を行っていないので、手元で等分散性の検定を実行してみます。
# 等分散性の検定の実行 var.test(mens_mail, no_mail) F test to compare two variances data: mens_mail and no_mail F = 2.3473, num df = 21306, denom df = 21305, p-value < 2.2e-16 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 2.285110 2.411204 sample estimates: ratio of variances 2.34731
# 等分散性の検定の実行
alternative hypothesis: true ratio of variances is not equal to 1
これは、対立仮説が、母分散の比が1ではないということを表しています。
ここで、「p-value < 2.2e-16」とp値がかなり小さい値になっていることから帰無仮説が棄却され、対立仮説が採択されます。
これについて、書籍内容とは異なる結果となってしまったように思えますが、どう考えれば良いのでしょうか。。。
データフレームで、条件に応じて乱数を生成する
データフレームで、他の列の値に応じて異なるルールで乱数を生成したい
手元で適当な乱数を生成し、それをもとに何かしらの分析手法を試すことがあると思います。
そういった時、ある列に同一のルールで乱数を生成するのであれば以下のようにします。
library(tidyverse) set.seed(71) len <- 10 dat_1 <- data.frame(v = rnorm(len, 100, 10)) dat_1 v 1 95.68158 2 95.52813 3 95.21427 4 104.17145 5 95.82099 6 88.12836 7 89.27714 8 110.03284 9 88.91522 10 112.63431
ここで、別の列に何かしらのフラグが設定されており、その値に応じてそれぞれ異なるルールで乱数を設定したい場合は、以下のように行います。
set.seed(71) len <- 10 dat_2 <- data.frame(f = c(as.integer(runif(len, 0, 2)))) dat_2 <- dat_2 %>% mutate(v = case_when(f == 1 ~ rnorm(len, 600, 50), f == 0 ~ rnorm(len, 200, 50), TRUE ~ -100)) dat_2 f v 1 0 118.9311 2 1 546.3857 3 0 239.0665 4 0 194.5544 5 0 196.2005 6 1 614.6475 7 1 627.4138 8 1 556.6673 9 0 205.9063 10 0 112.1548
失敗例
最初、以下のように記述していて失敗していました。
set.seed(71) len <- 10 dat_ng <- data.frame(f = c(as.integer(runif(len, 0, 2)))) dat_ng <- dat_ng %>% mutate(v = case_when(f == 1 ~ rnorm(1, 600, 50), # 生成する乱数を、1つにしている f == 0 ~ rnorm(1, 200, 50), # 上記同様 TRUE ~ -100)) dat_ng f v 1 0 146.3857 2 1 540.6418 3 0 146.3857 4 0 146.3857 5 0 146.3857 6 1 540.6418 7 1 540.6418 8 1 540.6418 9 0 146.3857 10 0 146.3857 # fが0の場合、fが1の場合、それぞれで同じ値が反映されている。
以上でした!
Rでデータの中身をざっと確認する
読み込んだデータをざっと確認したい
データ分析業務を行っていると、定期的に分析対象のデータが変わることは当然発生します。
新たなデータを受け取った時は、データの中身をざっと確認したいことがあります。
とはいえ、そこまでそういった処理の頻度が高いわけでもなく、データが新しくなるたびに処理方法を確認する、ということをしていました。
毎回確認するのは非効率なので、これを気にこの記事に色々な確認方法をまとめておきます。
データのカラム数に応じで、確認方法を分類します
データの中身をざっと確認すると言っても、そのデータのカラム数が5なのか、100なのかによって、適切な確認方法は変わると思います。
そのため、この記事では各データの大凡のカラム数によって、確認方法を分類します。
カラム数が7くらいまで
確認を行うデータは、irisデータにします。
> dim(iris) [1] 150 5 # 150行、5列のデータ > head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
base::plot(iris)
パッケージのインストールが不要で、記述も簡単です。
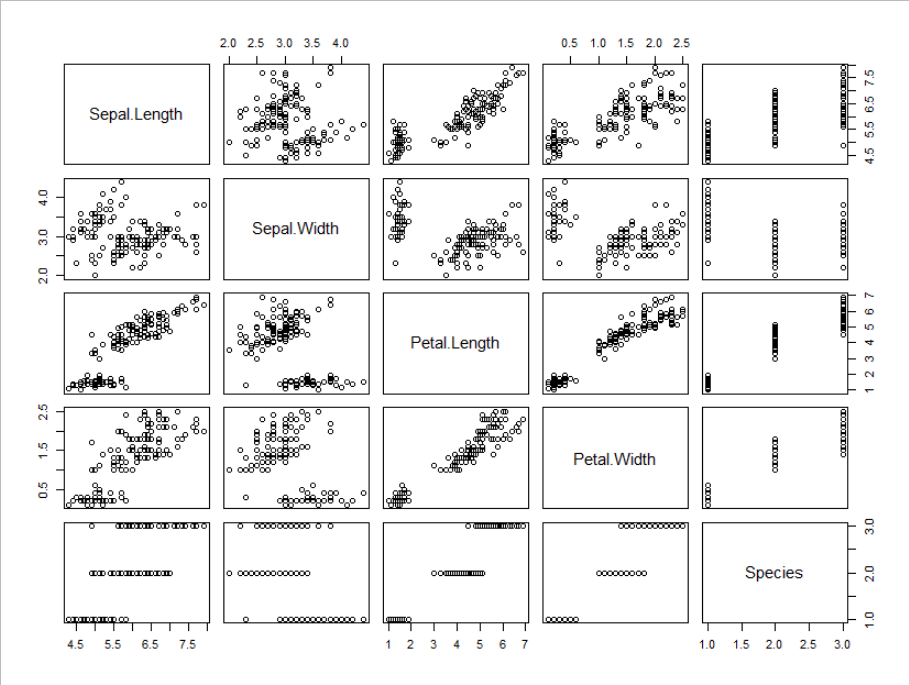
psych::pairs.panels(iris)
変数毎の分布が見れて、かつ2変数の散布図、及び相関係数が確認できます。
記述も簡単なので、お手軽かつデータの概要を掴むのには有効だと思います。
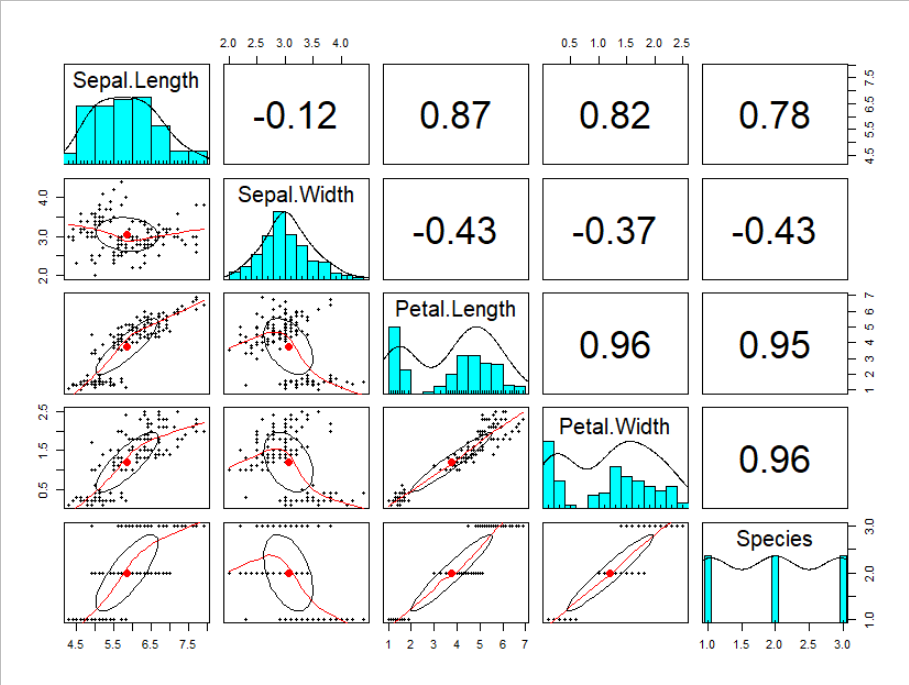
GGally::ggpairs(iris)
若干処理が重いイメージがありますが、綺麗に描画してくれるので個人的に好きです。
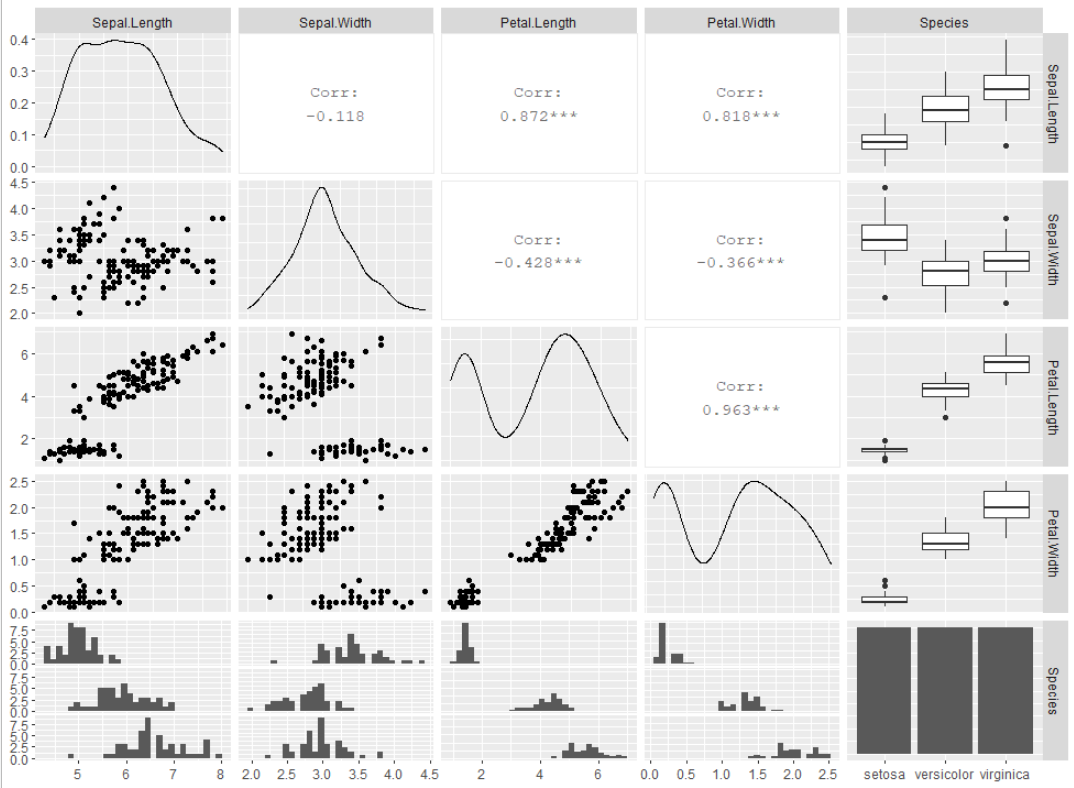
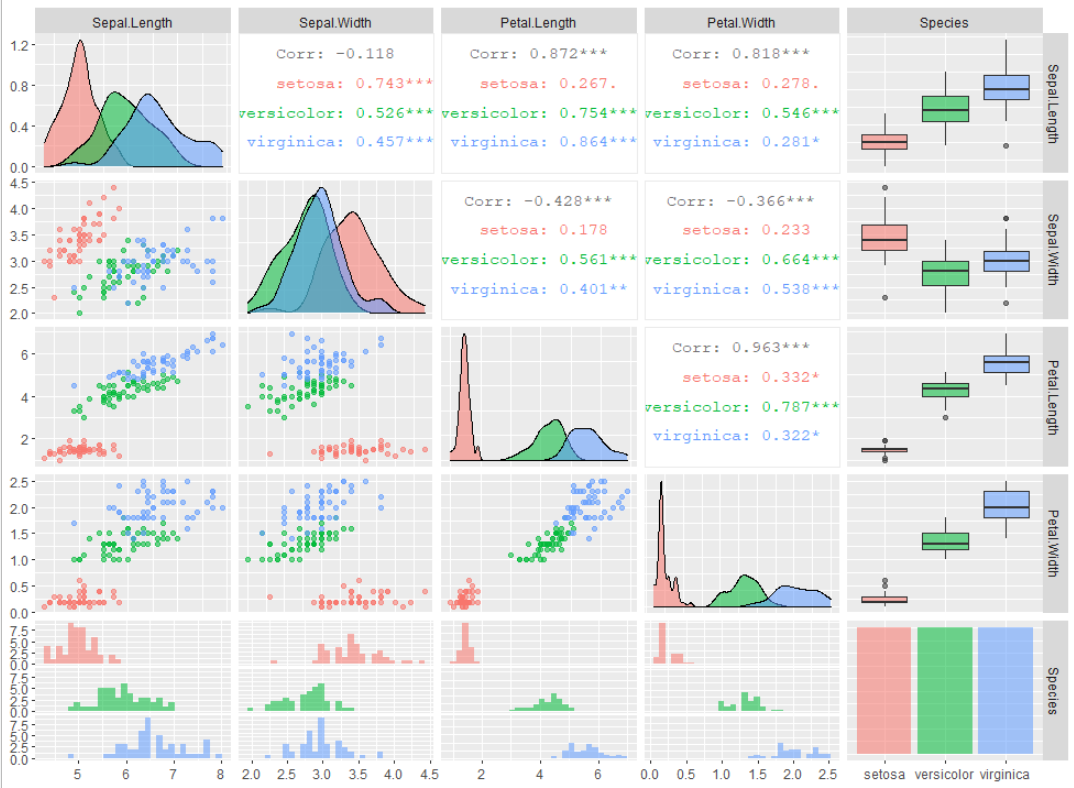
任意の列の値で色分けをしたい場合、以下のように記述すると行えます。
GGally::ggpairs(iris, ggplot2::aes(colour=Species, alpha = 0.8))
カラム数が10以上
カラム数が多くなると、行列形式で全ての値を俯瞰するのはあまり現実的ではないと思います。
その上でできそうなことを書いていきます。
対象データは、DoDStat@d データ指向統計データベース内から、新国民生活指標(住む)データをお借りします。
> dat <- read.csv('http://mo161.soci.ous.ac.jp/@d/DoDStat/PLIlive/PLIliveJ.csv', header = TRUE) > dim(dat) [1] 47 24 > head(dat) Pref NonRep OverMin Rent HomeOwn CompPol NumClime NumLarc TrafAcci Fire DspRubb Sidewalk MedFacil OverOrd Sunshine NumMat AreaResi Transpt AreaPark Sewarage Recycle AmtRubb AvgMin Pavement 1 北海道 7.67 94.3 1510 54.0 15.0 7.6 206 451.8 77.3 44.78 21.7 57.3 53.71 56.16 11.8 306 90.9 25.5 77.86 4.9 1655.0 24 19.9 2 青森県 7.80 95.9 1480 71.6 32.8 4.5 103 558.2 88.1 66.29 10.9 30.1 57.73 61.99 12.6 356 87.1 12.9 36.00 3.2 1363.6 23 24.9 3 岩手県 6.93 95.0 1643 72.8 22.0 6.3 115 388.9 65.6 79.81 8.3 34.1 55.65 72.20 12.4 365 80.2 9.6 35.50 11.3 940.0 24 14.4 4 宮城県 7.26 93.9 2257 60.7 34.3 9.1 272 471.1 81.7 83.99 13.8 49.4 45.44 67.29 10.8 358 85.1 11.7 40.10 16.2 1102.9 29 26.6 5 秋田県 5.92 97.1 1554 79.6 23.1 9.1 88 364.3 84.8 70.43 8.3 31.4 63.89 63.55 13.3 389 84.9 15.8 31.90 10.4 1203.8 22 15.7 6 山形県 5.75 96.8 1701 79.2 31.0 5.6 137 496.6 94.8 81.28 15.0 40.9 54.28 74.52 11.7 398 79.7 13.4 44.60 16.5 950.2 23 20.7
summarytools::dfSummary(dat) %>% summarytools::view()
変数毎に、平均値や最小最大値、分布を表示してくれます。
変数が多くなるとそれだけ出力結果も長くなるので、下図では最初と最後の部分だけを抜粋しています。

~
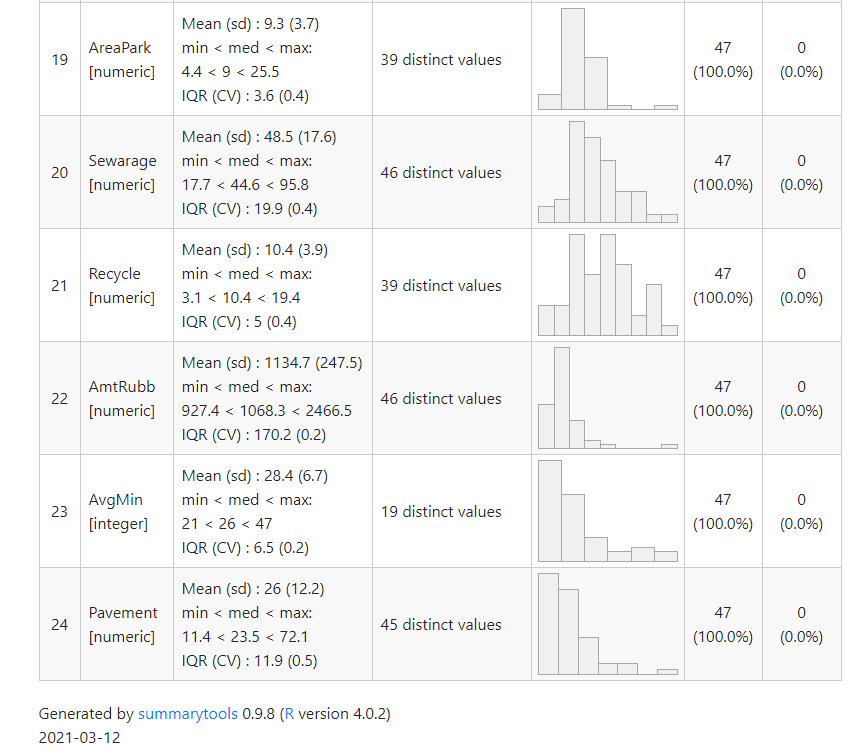
他にもあれば追加していきます
データをざっと眺めるのは大事ですが、それをするために毎回時間を食ってしまうのはもったいないと思います。
今後も良い確認方法があれば追記していきます。
感想:問題解決 ― あらゆる課題を突破する ビジネスパーソン必須の仕事術
はじめに
データアナリストをしていく上で必要なスキルは数多くあると思いますが、その中でも基礎中の基礎、そしてビジネスをしていく上で恐らくあらゆる場面で必要とされるであろう能力は問題解決能力だと思います。
そんな問題解決能力ですが、社会人になってこの方、体系的に学んだことがないなとふと思いました。
特に、最近はデータ分析をする中で問題解決能力、もっと言えば問題発見・設定能力の重要性を痛感する場面がしばしばあるため、良い機会だと思いタイトルにある書籍を読みました。
書籍のリンクはこちら。
ざっくり書評
- 社会人1~2年目くらいの人にとっては、問題解決の行い方の基礎を得られる良書。
- 社会人歴3年目以降の人にとっては、自身の思考を整理するための手引に。
本書のポイント
問題解決の3ステップ+1
本書では、問題解決を行う上で、次のステップを順番に踏むようにと記載されています。
- WHERE :問題がどこにあるかを特定する
- WHY :その問題の原因はなにかを深く考える
- HOW :ではどうすればよいかを、論理的に導く
このステップを順番に正しく踏んでいくことがどれだけ大切か、ということに重点をおいている書籍だとも思います。
特に、問題解決する上での落とし穴として、「HOW思考」が挙げられています。
HOW思考とは、問題が発生した時に打ち手から考える思考のことです。
例えば、ある企業の問題として、売上の低下が発生していたとします。
この時、HOW思考の人間は「営業の人員をもっと増やそう」とか、
「販売時の値引き額を、最大で10%までにしよう」といったように、対策として何をすれば良いかを最初に考えてしまう、といったものです。
このHOW思考の何がいけないかというと、資源の無駄使いにつながってしまうことです。
企業や個人における資源は有限であり、何かをするということは他の何かをしない、ということと同義だと思います。
その状況の中、問題に対して適切な解決策になるかわからない思いつきの対策を、思いついた順に片っ端から行っていくことは、企業や個人資源の無駄使いに繋がります。
なので、3ステップを順番にいきましょう、ということになります。
本書で掲げているように、このステップを順番に踏んでいくという考え方は、普段の分析をすすめる上でも大切です。
企業における課題は日々発生していて、その種類も多種多様です。
多くの課題があるなかで、落ち着いてその発生箇所を見極めていかないと、より良い分析は行えないでしょう。
では、「+1」とは何かというと、WHAT のあるべき姿の定義のことを表しています。
問題解決型と、問題設定型。
問題は、大きく分けて2種類あります。
誰が見ても問題だと思える状態と、自らが問題だと設定する問題です。
前者は、例えば
- 今年度の利益が赤字
- 採用した新卒が全員1年目で退職
- 既存ユーザー数が去年比70%になった
といったものです。
こういった誰が見ても明らかに問題だと思えることは、先述の3ステップを順番に実施していけば良い対策に結びつくでしょう。
では、こういった例はどうでしょうか?
- 今年度の売上は昨年度より5%上昇した。
- 採用した新卒のうち、1年目で離職したのは2%だった。
- 既存ユーザー数が去年比101%になった。
去年と比べると悪くなっていない、またはなんとなく大きな悪影響にはなっていないため、人によっては問題と感じないかもしれません。ただ、企業をより良い状態へ導くためには、こういった一見問題がない部分も問題と捉え、どのように改善(向上)させていくかが大事です。
そのために、あるべき姿を定義して、そこから問題解決をしていくことが求められるのです。
本書のちょっとあれなところ
本書では、あるべき姿の難しい点として、何が問題かをみんなの共通認識にさせることだとしていました。個人的にはそれはちょっと微妙な点で、最も難しいのはその問題自体を見つけることだと思います。
データ分析をしていても、顧客から明確な問題を提示してくることもあれば、そうではないときもあります。問題が出てこないとき、いかに問題を見つけるか、問題を設定するかが本当に難しく、また問題発見能力自体が良いアナリストになるための能力だとも思います。
本書には、問題発見能力向上につながる糸口を求めたところもあり、その部分がやや物足りないなと感じました。
最後に
気づいたら1年位ブログを放置していました。
そのせいもあり、この記事で何を伝えたいかもよくわからない、文章もまとまりもない、といった結構メチャクチャな記事になったなと感じます。
とはいえ、文章がうまくなるには文章を書くことが大事だとも思いますし、より良いアウトプットをするにはより多くのアウトプットをすることだとも思いますので、とりあえず書ききりました。
もうちょっと、文章を書く頻度を増やさないとなぁ、、と身に染みる思いです。
ではまた!