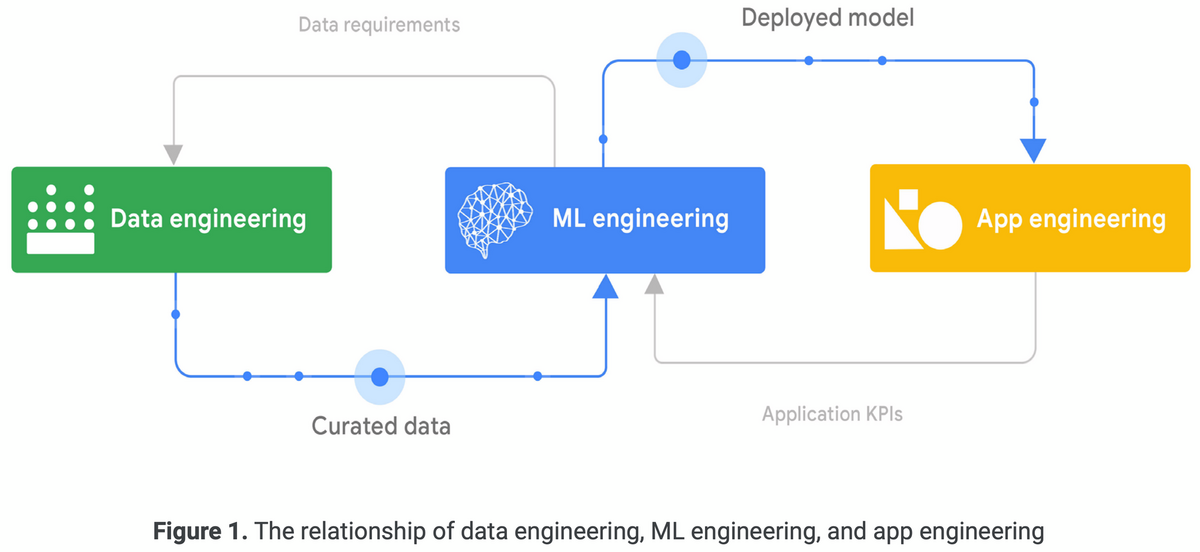
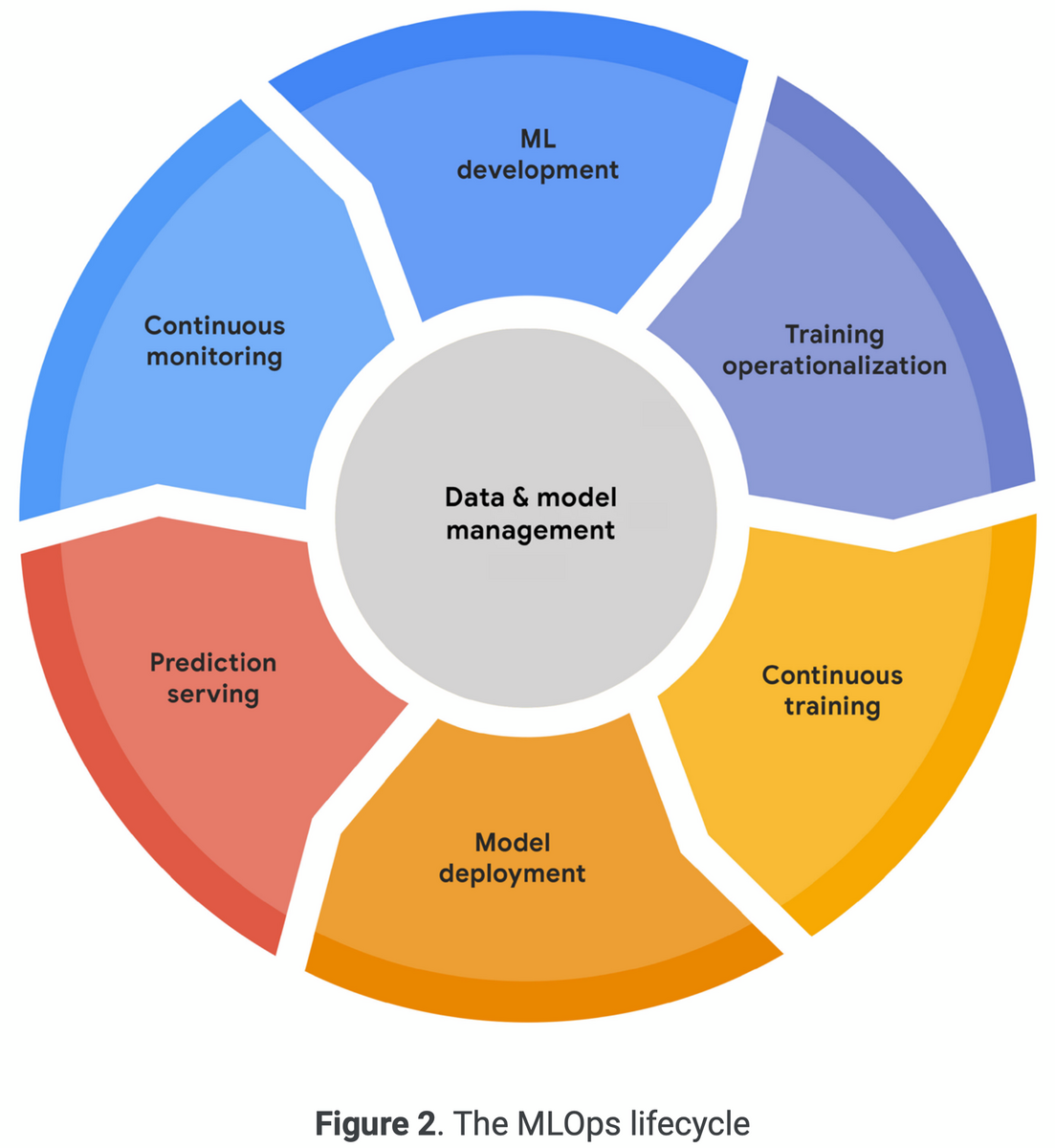
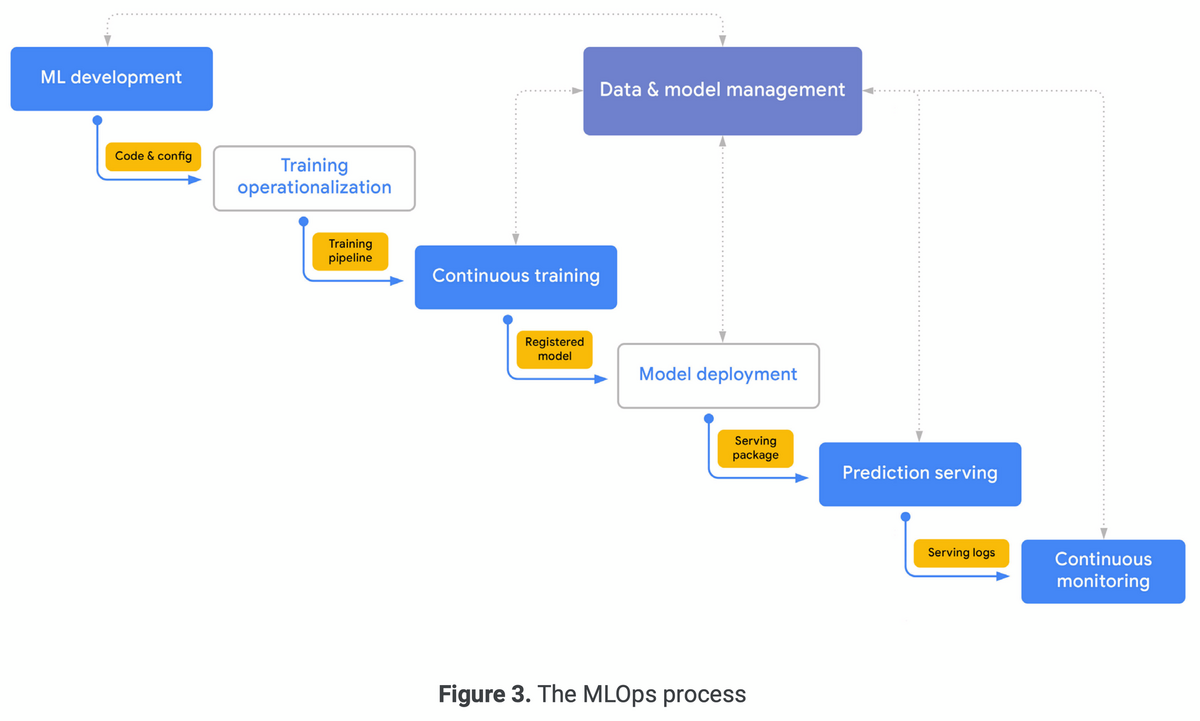
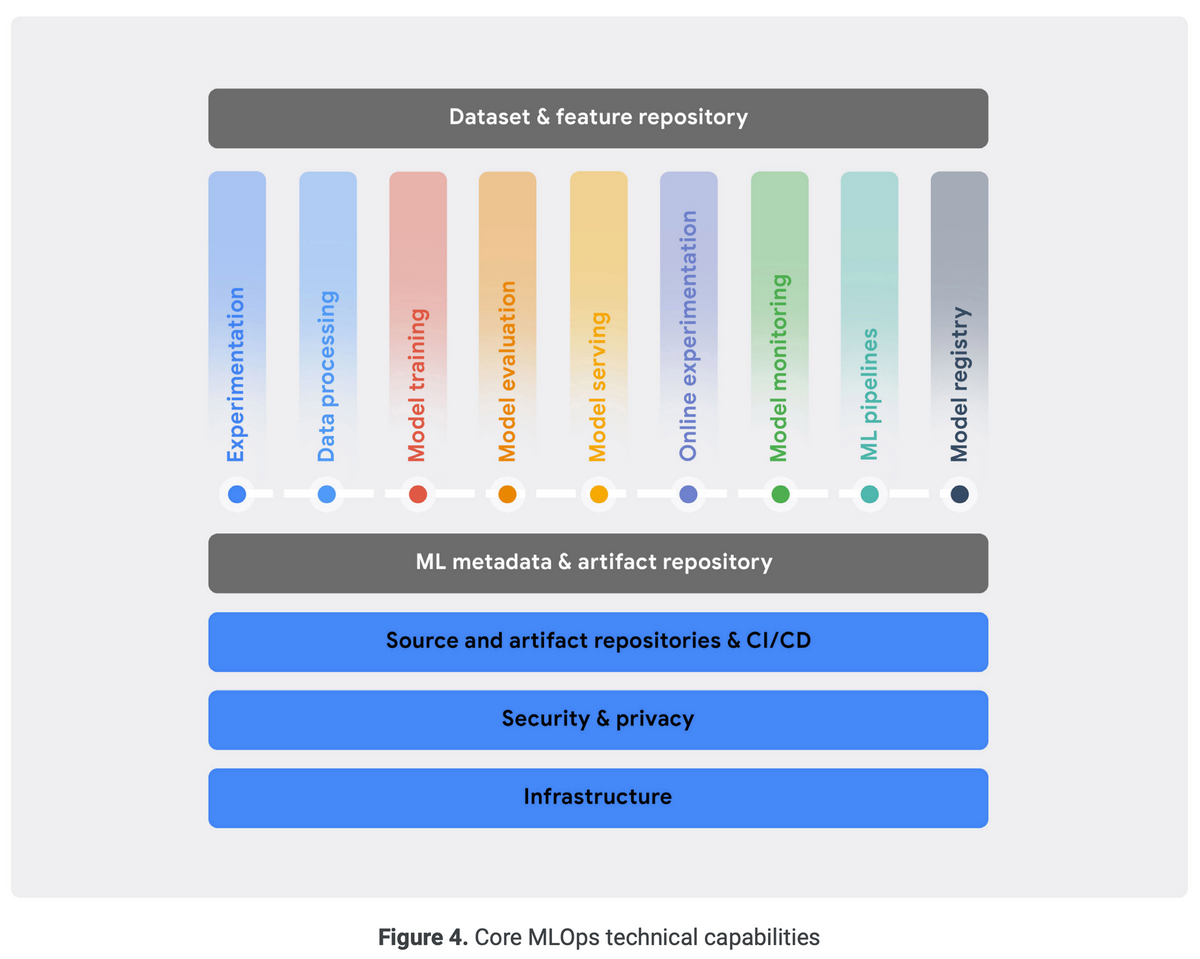
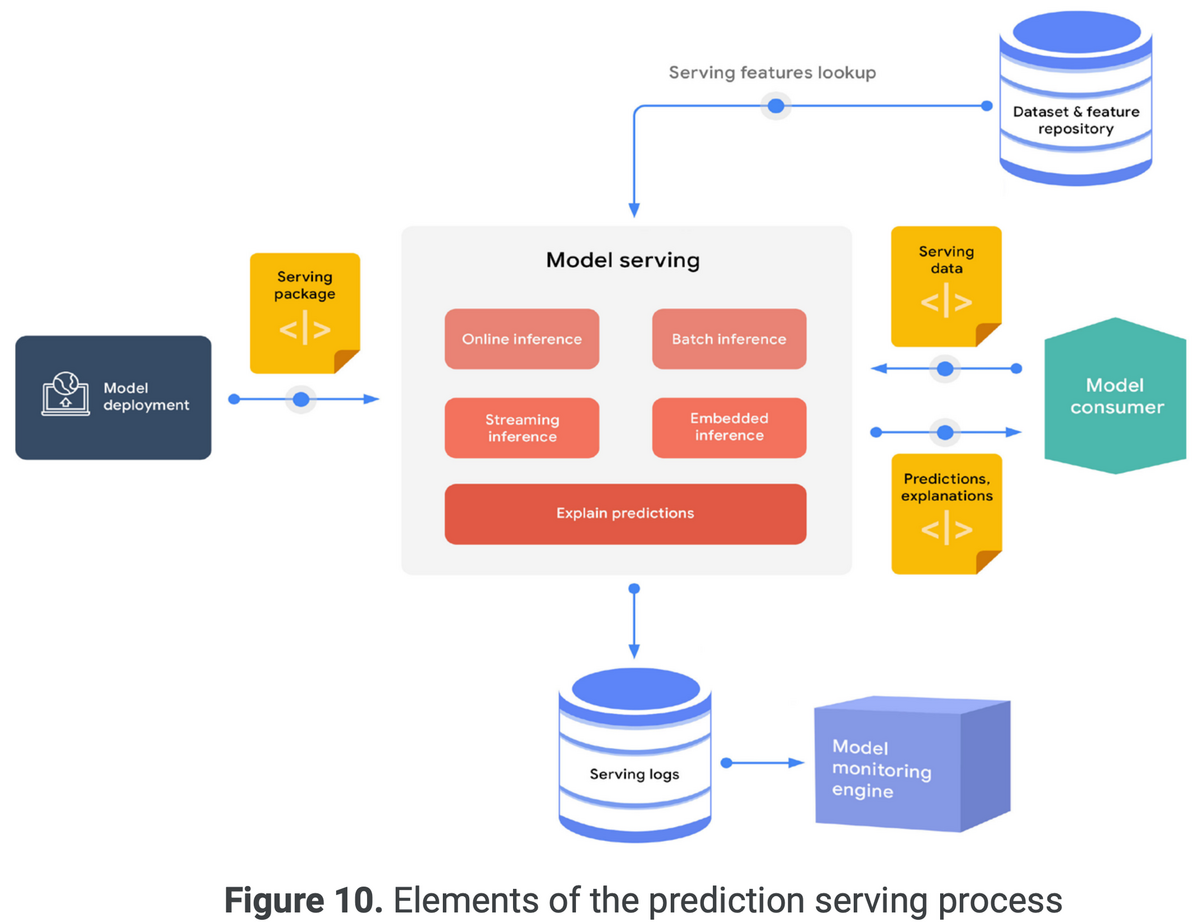
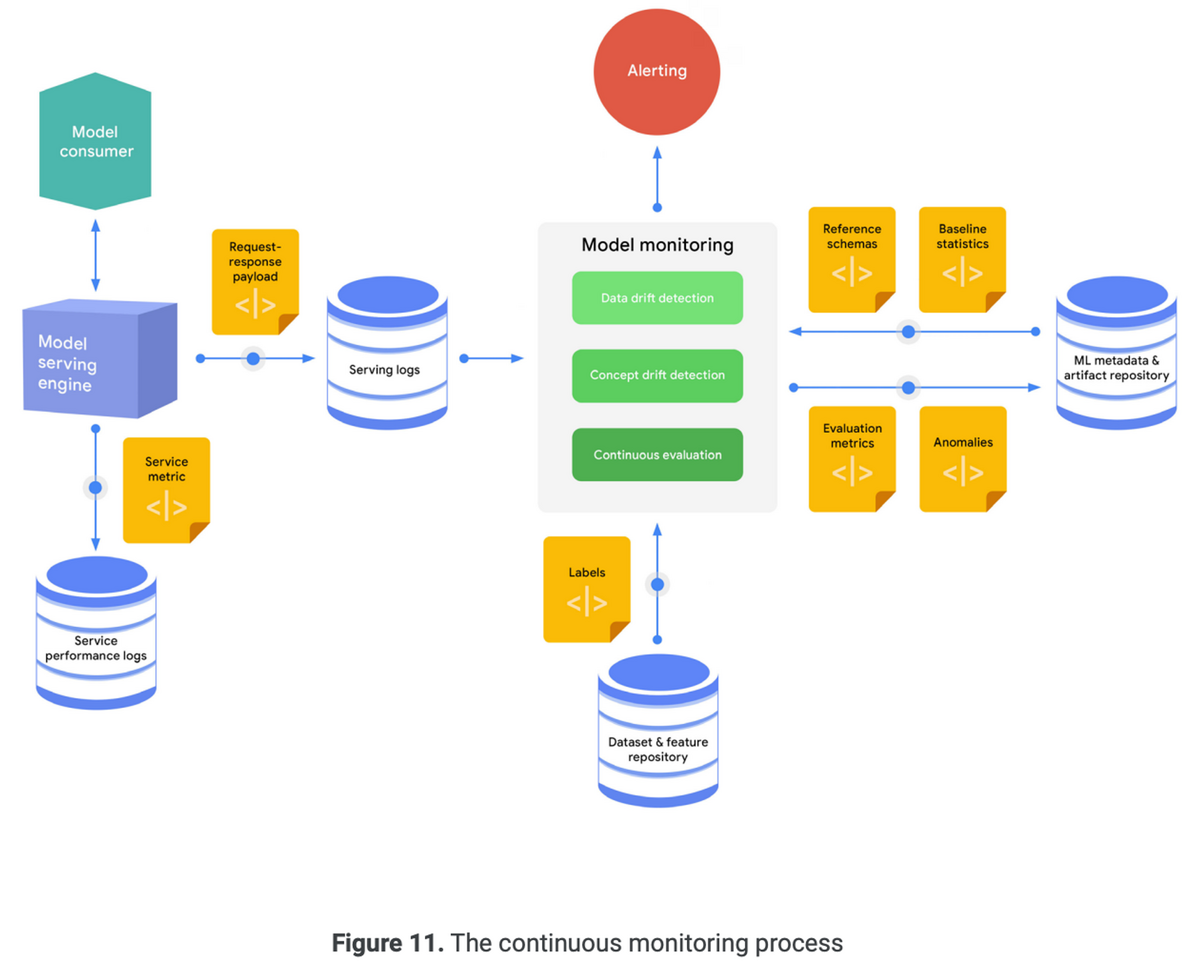
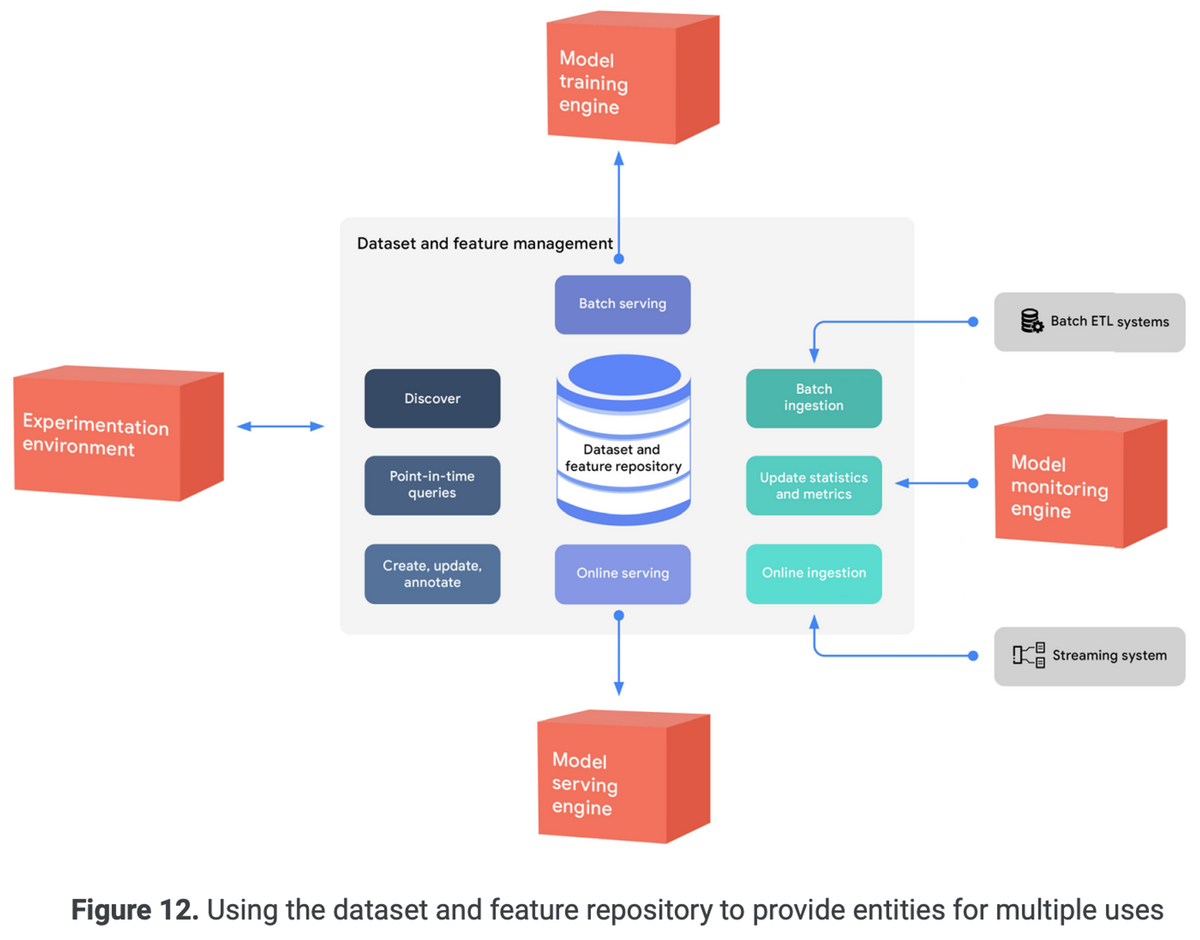
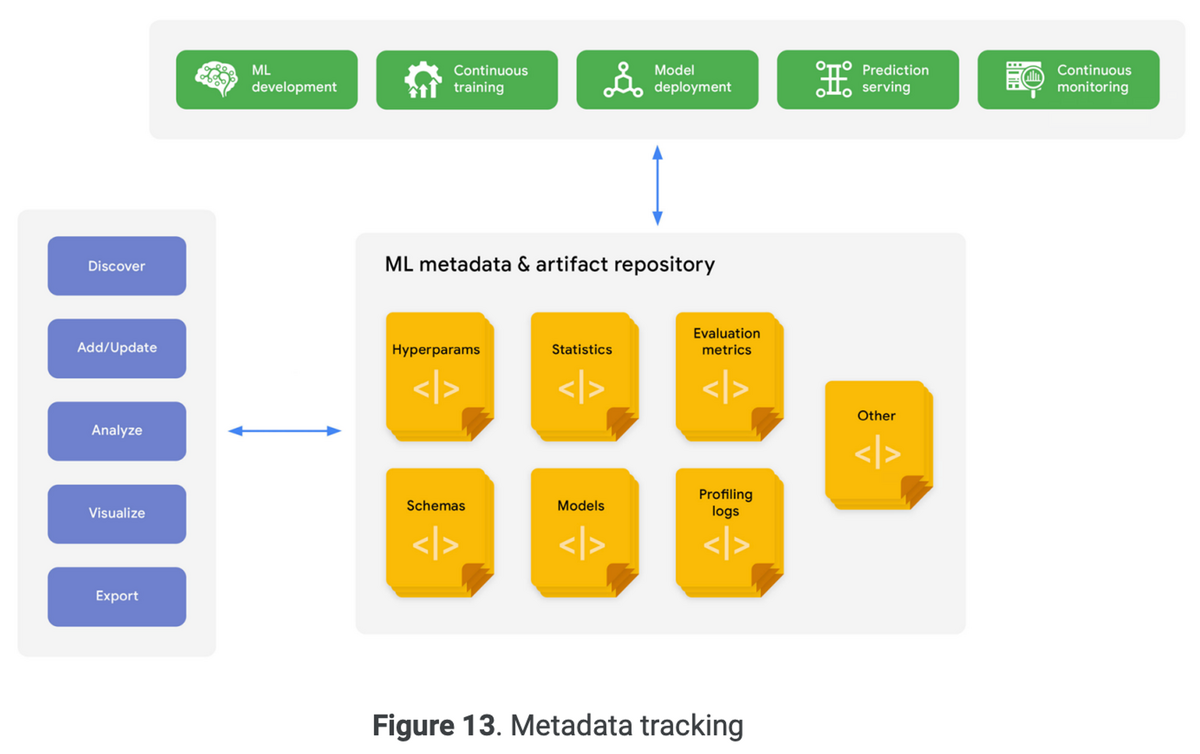
「データエンジニアリングの基礎」を読んだので、感想・各章の内容についてまとめます
www.oreilly.co.jp
全体を通しての感想
原本は Fundamentals of Data Engineering で本書は日本語訳となります。
筆者のJoe Reis氏とMatt Housley氏はデータエンジニアリングのコンサルタントを行っていて、業界経験が長いお二人です。
データエンジニア界隈は急速に変化する業界と本文中で書かれています。
業界変化の中で「変わらないもの」を選択し、今後数年間役に立つコンセプトをまとめたものと本書を説明しています。
上記の狙い通り、本書はツールや特定技術ソリューションの話題は避け、データエンジニアリングの背後にある普遍的な技術概念の説明に徹しています。
SQL実行の内部の処理や、磁気ディスクドライブの物理挙動にまで踏み込んでいて、データエンジニアリングの基礎というタイトルにふさわしい内容でした。
データエンジニアリング領域に関わらず、エンジニアリング一般論として興味深いテーマについてベテランエンジニアの見解を知れる贅沢な内容でした。
日本語訳ですが、英語原本での独特の言い回しを日本語でも伝わるよう丁寧に訳されてるのが伝わってきて、非常に読みやすかったです。
今後、データエンジニアの必読書となるだろう一冊でした。
Ⅰ部データエンジニアリングの基礎と構成要素
1章 データエンジニアリング概説
1.1 データエンジニアリングとは何か
1.1.1 データエンジニアリングの定義
1.1.2 データエンジニアリングライフサイクル
1.1.3 データエンジニアの発展
1.1.4 データエンジニアリングとデータサイエンス
1.2 データエンジニアリングのスキルと活動
1.2.1 データ成熟度とデータエンジニア
1.2.2 データエンジニアに求められる背景知識とスキル
1.2.3 ビジネス上の責務
1.2.4 技術的責務
1.2.5 データエンジニアの役割のスペクトラム:タイプAからタイプBまで
1.3 組織内でのデータエンジニアリング
1.3.1 内向きデータエンジニアと外向きデータエンジニア
1.3.2 データエンジニアと他の技術職
1.3.3 データエンジニアとビジネスリーダーシップ
1.4 結論
1.5 参考資料
データエンジニアリングとデータエンジニアとは?について整理しています。データエンジニアリングの歴史と、データエンジニアと類似職種との関係性の話は個人的に面白かったです。
組織におけるデータエンジニアの非技術的な役割が書かれています。多くの利害関係者をつなぐ役割が求められると述べられていて、非技術部分の業務のウェイトが大きい印象を受けました。
2章 データエンジニアリングライフサイクル
2.1 データエンジニアリングライフサイクルとは何か?
2.1.1 データライフサイクルとデータエンジニアリングライフサイクル
2.1.2 生成:ソースシステム
2.1.3 保存(ストレージ)
2.1.4 取り込み
2.1.5 変換
2.1.6 データの提供
2.2 データエンジニアリングにおける主要な底流
2.2.1 セキュリティ
2.2.2 データ管理
2.2.3 DataOps
2.2.4 データアーキテクチャ
2.2.5 オーケストレーション
2.2.6 ソフトウェアエンジニアリング
2.3 結論
2.4 参考資料
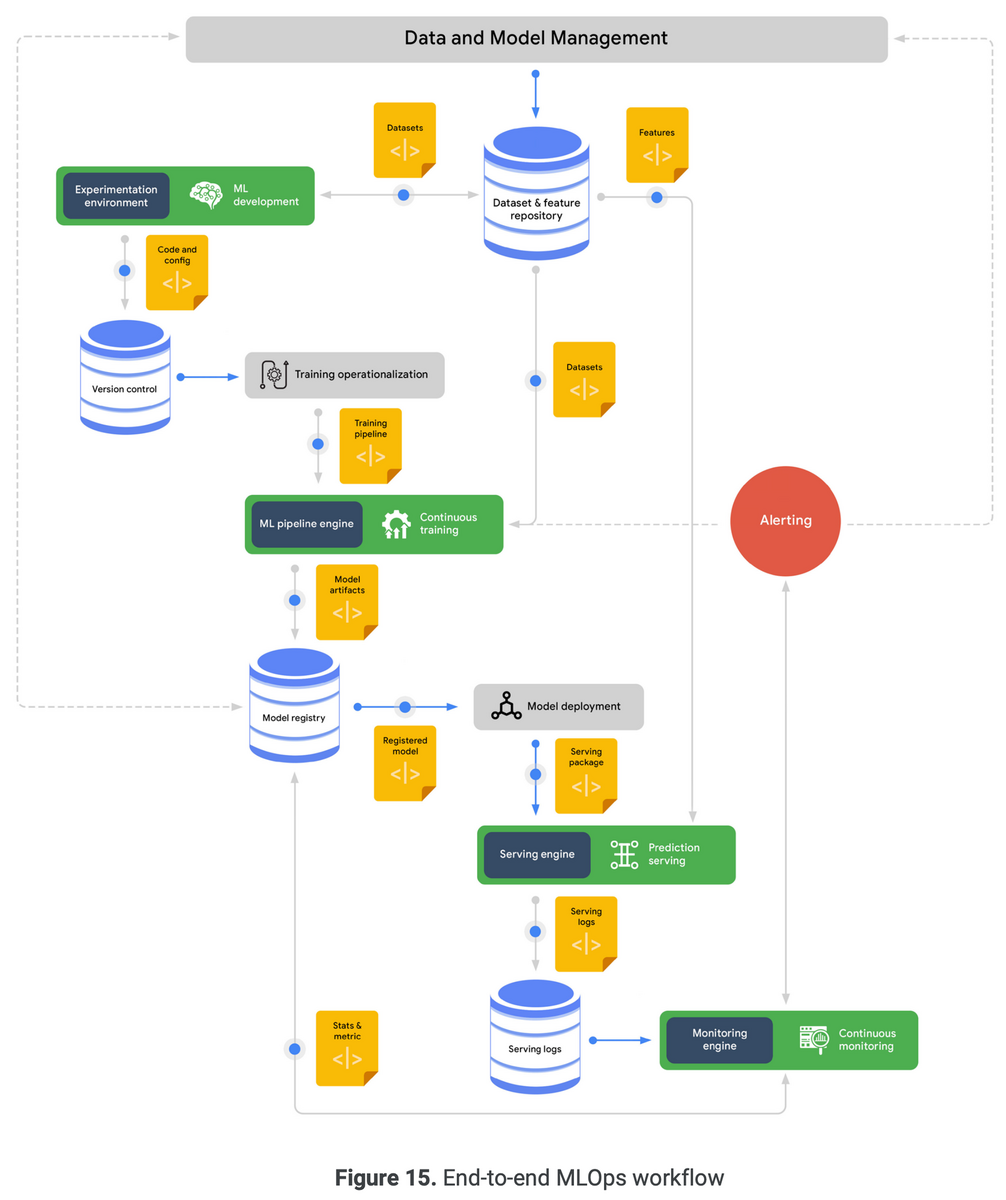
本書ではデータをプロダクト価値に変えていく一連の流れをデータエンジニアリングライフサイクルという言葉で表現しています。
データエンジニアリングライフサイクルは、データの生成・保存・取り込み・変換・提供で構成されます。これらの土台となる要素がセキュリティ・データ管理・DataOps・データアーキテクチャ・オーケストレーション・ソフトウェアエンジニアとしています。
データエンジニアリングの技術範囲が自分は曖昧だったので、体系的に整理してる内容は貴重でした。データ運用のためのOpsに着目したDataOpsという概念を初めて知りました。
3.1 データアーキテクチャとは何か?
3.1.1 エンタープライズアーキテクチャとは何か?
3.1.2 データアーキテクチャの定義
3.1.3 「良い」データアーキテクチャ
3.2 良いデータアーキテクチャの原則
原則1:共通コンポーネントを賢く選択する
原則2:障害に備える
原則3:スケーラビリティ設計
原則4:アーキテクチャはリーダーシップだ
原則5:常に設計し続ける
原則6:疎結合システムを構築する
原則7:可逆な決定をする
原則8:セキュリティを優先する
原則9:FinOpsを活用する
3.3 主要なアーキテクチャの概念
3.3.1 ドメインとサービス
3.3.2 分散システム、スケーラビリティ、障害に備えた設計
3.3.3 密結合と疎結合:ティア、モノリス、マイクロサービス
3.3.4 ユーザアクセス:シングルテナントとマルチテナント
3.3.5 イベント駆動アーキテクチャ
3.3.6 ブラウンフィールドプロジェクトとグリーンフィールドプロジェクト
3.4 データアーキテクチャの例と種類
3.4.1 データウェアハウス
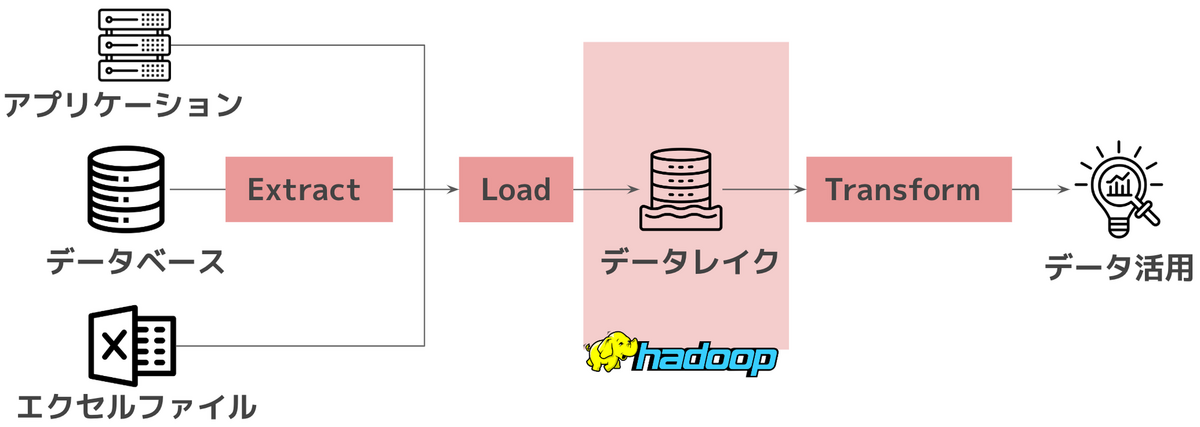
3.4.2 データレイク
3.4.3 次世代データレイクとデータプラットフォームの収斂
3.4.4 モダンデータスタック
3.4.5 Lambdaアーキテクチャ
3.4.6 Kappaアーキテクチャ
3.4.7 Dataflowモデル、バッチ、ストリームの統合
3.4.8 IoTのためのアーキテクチャ
3.4.9 データメッシュ
3.4.10 その他のデータアーキテクチャ
3.5 データアーキテクチャの設計にかかわるのは誰か
3.6 結論
3.7 参考資料
本書ではデータアーキテクチャを「データアーキテクチャは、企業の進化するデータへの要求をサポートするシステム設計であり、トレードオフを慎重に評価した上での柔軟で可逆な決定を通じて実現される」と定義してます。
データアーキテクチャの例としてデータウェアハウス、データレイクを取り上げています。
アーキテクチャが抽象度が高い概念で、様々な定義がされてる言葉なので、世の中のアーキテクチャに対する共通見解を丁寧に整理してくれてます。
4章 データエンジニアリングライフサイクルにおけるテクノロジの選択
4.1 チームのサイズと容量
4.2 市場投入までのスピード
4.3 相互運用性
4.4 コスト最適化とビジネス価値
4.4.1 総所有コスト(TCO)
4.4.2 所有の総機会費用
4.4.3 FinOps
4.5 現在vs.未来:不変テクノロジvs.一過性テクノロジ
4.5.1 アドバイス
4.6 設置場所
4.6.1 オンプレミス
4.6.2 クラウド
4.6.3 ハイブリッドクラウド
4.6.4 マルチクラウド
4.6.5 非中央集権型計算:ブロックチェーンとエッジ
4.6.6 アドバイス
4.6.7 クラウドからオンプレミスへの本国回帰
4.7 構築vs.購入
4.7.1 オープンソースソフトウェア
4.7.2 プロプライエタリなウォールドガーデン
4.7.3 アドバイス
4.8 モノリスvs.モジュール
4.8.1 モノリス
4.8.2 モジュール性
4.8.3 分散モノリスパターン
4.8.4 アドバイス
4.9 サーバレスvs.サーバ
4.9.1 サーバレス
4.9.2 コンテナ
4.9.3 サーバとサーバレスの評価方法
4.9.4 アドバイス
4.10 最適化、性能、ベンチマーク戦争
4.10.1 1990年代の「ビッグデータ」
4.10.2 無意味なコスト比較
4.10.3 非対称な最適化
4.10.4 購入者責任
4.11 底流とテクノロジ選択への影響
4.11.1 データ管理
4.11.2 DataOps
4.11.3 データ管理
4.11.4 オーケストレーションの例:Airflow
4.11.5 ソフトウェアエンジニアリング
4.12 結論
4.13 参考資料
前章のデータアーキテクチャの設計ができたのち、どのテクノロジーで実現するかの章になります。
オンプレvsクラウドや、モノリスvsモジュールといった、データエンジニアにとらわれず一般的にエンジニア界隈で議論に上がるテーマを取り扱っています。
これらのテーマに対するシニアエンジニアからの見解やアドバイスが書かれていて、この章を読むためだけに本書を買う価値があると思えるほどでした。
Ⅱ部 データエンジニアリングライフサイクルの詳細
5章 ソースシステムにおけるデータ生成
5.1 データソース:データはどのように生成されるのか?
5.2 ソースシステム:主要な概念
5.2.1 ファイルと非構造化データ
5.2.2 API
5.2.3 アプリケーションデータベース(OLTPシステム)
5.2.4 OLAP:オンラインアナリティクス処理システム
5.2.5 変更データキャプチャ
5.2.6 ログ
5.2.7 データベースログ
5.2.8 CRUD
5.2.9 インサートオンリー
5.2.10 メッセージとストリーム
5.2.11 時間と時刻の種類
5.3 ソースシステムの実践的な詳細
5.3.1 データベース
5.3.2 API
5.3.3 データ共有
5.3.4 サードパーティデータソース
5.3.5 メッセージキューとイベントストリーミングパイプライン
5.4 一緒に仕事する人
5.5 底流とそのソースシステムへの影響
5.5.1 セキュリティ
5.5.2 データ管理
5.5.3 DataOps
5.5.4 データアーキテクチャ
5.5.5 オーケストレーション
5.5.6 ソフトウェアエンジニアリング
5.6 結論
5.7 参考資料
データ生成に着目した章です。
データ形式ごとの各データベースの特徴が網羅されていて、贅沢な内容になっています。
ストリームデータの取り扱いについても取り上げられているのはありがたいです。
データ生成元はデータエンジニアの制御の外にあることが多いですが、データエンジニアライフサイクルにおいて重要な部分と指摘してます。
そのため、データエンジニアがアプリケーションチームとうまくコラボレーションできるよう、利害関係を構築する話がなされています。
6章 ストレージへの保存
6.1 データストレージの原材料
6.1.1 磁気ディスクドライブ
6.1.2 SSD(ソリッドステートドライブ)
6.1.3 RAM(ランダムアクセスメモリ)
6.1.4 ネットワークとCPU
6.1.5 シリアライズ
6.1.6 圧縮
6.1.7 キャッシュ
6.2 データストレージシステム
6.2.1 単体サーバvs.分散ストレージ
6.2.2 結果整合性と強い一貫性
6.2.3 ファイルストレージ
6.2.4 ブロックストレージ
6.2.5 オブジェクトストレージ
6.2.6 キャッシュとメモリベースのストレージシステム
6.2.7 HDFS(Hadoop分散ファイルシステム)
6.2.8 ストリーミングストレージ
6.2.9 インデックス、パーティション分割、クラスタリング
6.3 データエンジニアリングにおけるストレージ抽象
6.3.1 データウェアハウス
6.3.2 データレイク
6.3.3 データレイクハウス
6.3.4 データプラットフォーム
6.3.5 ストリーム・トゥ・バッチストレージアーキテクチャ
6.4 ストレージの要点とトレンド
6.4.1 データカタログ
6.4.2 データ共有
6.4.3 スキーマ
6.4.4 コンピュートとストレージの分離
6.4.5 データストレージのライフサイクルとデータ保持
6.4.6 シングルテナントvs.マルチテナント
6.5 一緒に仕事する人
6.6 底流
6.6.1 セキュリティ
6.6.2 データ管理
6.6.3 DataOps
6.6.4 データアーキテクチャ
6.6.5 オーケストレーション
6.6.6 ソフトウェアエンジニアリング
6.7 結論
6.8 参考資料
データの保存に着目した章です。
ストレージがあまりにも一般的で当たり前のものと思いがちなため、ストレージメディアに内在するトレードオフを知らないデータエンジニアが多いと指摘しています。
そのため、磁気ディスクドライブの物理的な挙動にまで踏み込んでいて、ここまで解説するのかと筆者らへ尊敬の念を抱きました。
理解が曖昧だったデータレイクハウスについて具体的な説明があったのはありがたかったです。
7章 データ取り込み
7.1 データ取り込みとは
7.2 取り込みフェーズにおけるエンジニアリング上の重要な検討事項
7.2.1 区切りありデータvs.区切りなしデータ
7.2.2 頻度
7.2.3 同期vs.非同期
7.2.4 シリアライズとデシリアライズ
7.2.5 スループットとスケーラビリティ
7.2.6 信頼性と耐久性
7.2.7 ペイロード
7.2.8 プッシュvs.プルvs.ポーリング
7.3 バッチ取り込みに関する検討事項
7.3.1 スナップショットまたは差分抽出
7.3.2 ファイルのエクスポートと取り込み
7.3.3 ETL vs. ELT
7.3.4 挿入、更新とバッチサイズ
7.3.5 データの移行
7.4 メッセージ取り込みとストリーム取り込みの検討事項
7.4.1 スキーマ進化
7.4.2 遅延到着データ
7.4.3 順序と多重配送
7.4.4 リプレイ
7.4.5 TTL(Time to Live)
7.4.6 メッセージサイズ
7.4.7 エラー処理とデッドレターキュー
7.4.8 消費者によるプルとプッシュ
7.4.9 場所
7.5 データ取り込みの方法
7.5.1 直接データベース接続
7.5.2 CDC:変更データキャプチャ
7.5.3 API
7.5.4 メッセージキューおよびイベントストリーミングプラットフォーム
7.5.5 マネージドデータコネクタ
7.5.6 オブジェクトストレージを用いたデータの移動
7.5.7 EDI
7.5.8 データベースとファイルのエクスポート
7.5.9 一般的なファイルフォーマットに関する現実的な問題
7.5.10 シェル
7.5.11 SSH
7.5.12 SFTPとSCP
7.5.13 Webhook
7.5.14 Webインタフェース
7.5.15 Webスクレイピング
7.5.16 データ移行のための転送アプライアンス
7.5.17 データ共有
7.6 一緒に仕事する人
7.6.1 上流の利害関係者
7.6.2 下流の利害関係者
7.7 底流
7.7.1 セキュリティ
7.7.2 データ管理
7.7.3 DataOps
7.7.4 オーケストレーション
7.7.5 ソフトウェアエンジニアリング
7.8 結論
7.9 参考資料
前章のデータ生成とストレージを結びつける、データ取り込みについての章です。
バッチやストリーム取り込みのパターンや、データ取り込みに関する技術テーマを幅広く取り扱っています。
データ品質テストについても触れられています。データソースに暗黙的な変化があることで、データ利用者が気付かぬうちに被害を受ける例をあげています。
データスキーマやニーズは変化するもので、変化する前提でデータアーキテクチャを設計するのが本書の基本姿勢です。
8章 クエリ、データモデリング、変換
8.1 クエリ
8.1.1 クエリとは何か?
8.1.2 クエリのライフサイクル
8.1.3 クエリオプティマイザ
8.1.4 クエリ性能の向上
8.1.5 ストリームデータに対するクエリ
8.2 データモデリング
8.2.1 データモデルとは何か?
8.2.2 概念データモデル、論理データモデル、物理データモデル
8.2.3 正規化
8.2.4 バッチアナリティクスデータのモデリング手法
8.2.5 ストリームデータモデリング
8.3 変換
8.3.1 バッチ変換
8.3.2 マテリアライズドビュー、フェデレーテッドクエリ、データ仮想化
8.3.3 ストリーミング変換と処理
8.4 一緒に仕事する人
8.4.1 上流の利害関係者
8.4.2 下流の利害関係者
8.5 底流
8.5.1 セキュリティ
8.5.2 データ管理
8.5.3 DataOps
8.5.4 データアーキテクチャ
8.5.5 オーケストレーション
8.5.6 ソフトウェアエンジニアリング
8.6 結論
8.7 参考資料
データ変換に着目した章です。
SQLが内部でどのような処理が実行されているかを説明しています。クエリ性能向上のための方法が理屈と共に紹介されているのがありがたいです。
データモデリングの手法としてKimball, Inmon, データボルトを取り上げています。
UDFを使用する危うさを指摘してます。コードがバージョン管理から外れ、組み込みのSQLコマンドより性能が悪化する可能性があると述べられています。
UDFは便利でつい使ってしまいがちだったので反省しました。
9章 アナリティクス、機械学習、リバースETL へのデータの提供
9.1 データ提供に関する一般的な考慮事項
9.1.1 信頼
9.1.2 ユースケースは何か? ユーザは誰か?
9.1.3 データプロダクト
9.1.4 セルフサービスにするべきか?
9.1.5 データ定義とロジック
9.1.6 データメッシュ
9.2 アナリティクス
9.2.1 ビジネスアナリティクス
9.2.2 オペレーショナルアナリティクス
9.2.3 組み込みアナリティクス
9.3 機械学習
9.4 データエンジニアがMLについて知っておくべきこと
9.5 アナリティクスやMLに対してデータを提供する方法
9.5.1 ファイル交換
9.5.2 データベース
9.5.3 ストリーミングシステム
9.5.4 クエリフェデレーション
9.5.5 データ共有
9.5.6 セマンティックレイヤとメトリクスレイヤ
9.5.7 ノートブックによるデータの提供
9.6 リバースETL
9.7 一緒に仕事する人
9.8 底流
9.8.1 セキュリティ
9.8.2 データ管理
9.8.3 DataOps
9.8.4 データアーキテクチャ
9.8.5 オーケストレーション
9.8.6 ソフトウェアエンジニアリング
9.9 結論
9.10 参考資料
データの提供に着目した章です。
データのユースケースとユーザーから考え、データプロジェクトを始める重要性を説いています。ユースケースとして分析やMLをあげ、ユーザーにアナリストやDS、MLエンジニア、そしてビジネス職を取り上げています。
ユーザーが自分でデータプロダクトを構築するセルフサービスにすべきかの議論が興味深かったです。
エンドユーザーを理解してないと、セルフサービス化は難しいと指摘しています。
Ⅲ部 セキュリティとプライバシー、およびデータエンジニアリングの未来
10章 セキュリティとプライバシー
10.1 人材
10.1.1 ネガティブ思考の力
10.1.2 常に心配性でいる
10.2 プロセス
10.2.1 劇場型セキュリティvs.習慣としてのセキュリティ
10.2.2 アクティブセキュリティ
10.2.3 最小権限の原則
10.2.4 クラウドでの責任共有
10.2.5 常にデータのバックアップを取る
10.2.6 セキュリティポリシーの例
10.3 テクノロジ
10.3.1 パッチとシステムアップデート
10.3.2 暗号化
10.3.3 ロギング、監視、アラート
10.3.4 ネットワークアクセス
10.3.5 低レイヤデータエンジニアリングにおけるセキュリティ
10.4 結論
10.5 参考資料
セキュリティについてデータエンジニアリングライフサイクルの全てのステージで最初に考える必要があると指摘しています。
データエンジニア領域に関わるセキュリティ項目の各概要を取り上げています。
顧客データの漏洩ニュースをよく見かけますが、データエンジニアを務める以上は対岸の火事では済まされないなと感じる内容でした。
11章 データエンジニアリングの未来
11.1 データエンジニアリングライフサイクルは消えない
11.2 複雑さの衰退と使いやすいデータツールの興隆
11.3 クラウドスケールデータOSと相互運用性の改善
11.4 「大企業的」データエンジニアリング
11.5 職種名と担当範囲は変化する
11.6 モダンデータスタックからの脱却とライブデータスタックへの移行
11.6.1 ライブデータスタック
11.6.2 ストリーミングパイプラインとリアルタイムアナリティクスデータベース
11.6.3 データとアプリケーションの融合
11.6.4 アプリケーションとML間での緊密なフィードバック
11.6.5 ダークマターデータとスプレッドシートの興隆?
11.7 結論
データエンジニアの今後の未来予想の章です。
データエンジニアリングライフサイクルはすぐに消えることはないが、ソフトウェアエンジニア、データエンジニア、データサイエンティスト、MLエンジニアの境界がより曖昧になっていくと指摘しています。
データ界隈の職種で生きるなら、技術領域は広めに持っておいた方がいいと自分は考えていたので、共感できる部分が多かったです。