「フォントピント」が縦書き・複数行のテキストに対応しました
画像から日本語フォントを検索できる唯一のサービス「フォントピント」が、縦書きや複数行のテキストに対応しました!より柔軟にフォントの検索が可能になりました。あとちょっぴり精度が良くなったはずです。検索のための内部の方法が大きく変わったので、またまた備忘録を兼ねて書いておきたいと思います。
実際どうなったのか?
例えば以下のような縦書きの看板で検索ができます!!一番確率の高いと予測されている黒龍爽なんかはかなり近いんじゃないでしょうか。

考え方
以下の画像が全てです。これまでは検索対象の画像が与えられたときランダムで正方形のパッチを複数枚切り抜き、フォント予測モデルの入力としていました。これだと文字の情報が上手く使えなかったり、運が悪いとほとんど背景のパッチができたりしてしまいます。
実際は文字認識のために、クラウドサービスが提供するOCR APIを使用しています。このようなAPIはほとんどが、文字の領域を囲うバウンディングボックスの座標を返却してくれます。このバウンディングボックスを使えば、正確に1文字ずつを切り取ったパッチをフォント予測モデルの入力として使用でき、予測精度の向上が期待できます(学習データは自分で作成している人工データなので、もちろんバウンディングボックスの定義が可能です)。また副次的な効果として1文字ずつを入力とするので、横書きとか縦書きとかが関係なくなります。

システム的なところ
これまではフォント認識と文字認識が独立したタスクだったため、フロントから両方のAPIにリクエストを投げていました。これからは、フォント認識では文字認識の結果を使うようになるので、フォント認識APIから文字認識のためのcloud vision apiにリクエストを投げるようにしました。

「フォントピント」がadobe fontsの日本語フォントに対応しました(+検索にかかる時間が大幅に短くなりました)
画像から日本語フォントを検索できるサービス「フォントピント」が、adobe fontsが提供する日本語フォントに対応しました。今まではgoogle fontsが提供する日本語フォントだけが検索対象でしたが、adobe fontsが加わったことで大幅に対応フォント数が増えて現在は365のフォントが対象になっていいます。
また、バックエンドの実行環境をaws lambdaからlightsailに移行したことで検索にかかる時間が大幅に短縮しました。今までは調子の良いときで3秒くらい、悪い時で10秒以上かかって正直目も当てられないレベルでしたが、現在は1秒程度で検索可能になりました。(もちろん環境・状況によりますが)
そろそろ(β)を外せるときが近づいてきた気もします。どうなったら外れるのかは自分でも分かりません。
結構苦労した点があったので、備忘録的に書いておきたいと思います。
adobe fonts対応
精度的な話
まず予測モデルの精度的なところで問題があり、加えようとしていたadobe fontsの日本語フォントを対象に学習を行ったところ、人工画像では精度的に問題がないのに実際の画像を入力したところ極端に異なるフォントが予測上位に多々出現する問題が生じました。これについてはまだ根本的な原因は分かっていません。しかし、複数枚の実画像でテストしたところ極端に異なるが上位にくるフォントが共通だったため、それらのフォントが何かしら悪さをしている可能性があり、それらを除去して学習したところ実画像でも許容できる結果になりました。今後も同じようなことが生じる可能性があり、原因は探りたいところです。
システム的な話
google fontsだけのときは問題にならなかったのですが、adobe fontsを加えた場合対象のフォントを全て読み込むと1回の転送量が大変なことになり、モバイル回線だと人によっては通信制限まっしぐらの悪意のあるサイトになってしまいそうでした(日本語フォントなので当然と言われれば当然なんですが)。なので、フォント予測APIから結果が返ってきた後に予測されたフォントだけを動的に読み込むようにしました。(余談なんですが、adobe fontsではwebフォントを使う場合プロジェクトという概念にフォントを紐付けて、読み込む際にはそのプロジェクトIDを使用します。なので、フォントごとにプロジェクトを作成してその対応関係を持っておかなければいけないのですが、この作業が地獄でした)
また、adobe fontsが提供するフォント読み込みのスクリプトではWeb Font Loaderを使っており、該当のフォント読み込みが終わるとhtmlタグに .wf-<familyname>-<fvd>-active というクラス名を付与します(fvdはフォントのスタイルやウェイトを表現する記述です)。なので、MutationObserverでクラスの変更を監視してフォントの読み込みが終わったことを検知し、読み込み後に、画像から認識されたテキストを表示しています。これに関しては、実はもっと良い方法がありそうなのですが現状できる範囲でやってます。下がフォント予測APIから結果を受け取ったあと、フォントを読み込み終わりテキストを表示するまでの待ちの様子です。基本は1秒もかからないはずですが、遅い回線だと数秒の待ちが発生するかもしれません。これにより、転送量は基本的にせいぜい数MBになりました。

バックエンド移行
前回の記事でバックエンドの問題点を書きました。ecs / fargateで実行しようかと思っていたのですが、2020年末くらいにlightsailでコンテナを実行できるサービスが始まっていたことを少し調べているうちに知りました。fargateだと1 vCPU、2GBのRAMで5500円〜6000円くらいかつ基本前段にロードバランサを挟むので8000円くらいはかかりそうな雰囲気がありましたが、lightsailのコンテナサービスだと同じスペックでロードバランサも含めて上限が40ドルです。つまり5000円くらいなのでかなり安くできます。またデプロイすると自動的にHTTPSエンドポイントが付与されます。
個人的には、lightsailのコンテナサービスは個人なり小規模で機械学習の推論APIを建てる際の最初の選択肢になり得ると思います。細かいとこには手が回りませんが、起動時にモデルの読み込みのような重い処理が必要でlambdaだときつい場合に一番安く・手がかからずに使えるサービスだと思います。気になる点は以下の記事などであげられていますが、個人的にはステージング環境が作りにくいことが気になりました。というのも課金を止めるためには環境を削除するしかなく、使うときだけ起動などができないからです。本番と同じ構成の料金を払えればいいんですが、さすがに無理なので自分はステージングは使用された時間だけ課金のlambdaのままで妥協しています。
[アップデート] Amazon Lightsail でコンテナが利用可能になりました! | DevelopersIO
Amazon Lightsailでコンテナが使えるようになったので検証してみた|Subaru Nakamura(varu3)
おわり
やりたいことはまだまだ残っており、今後の発展にご期待ください。
- 英数字にも対応したい
- ページ読み込みのパフォーマンス向上
- 何か結果をシェアできるようにしたい
などなど
画像から日本語フォントを検索できるサイト「フォントピント」を作った
こんにちは、街中で「あの文字のフォント何なんだろう?」と思うことよくありますよね。そんなときに役立つサイト「フォントピント(β)」を作りました。
実際のところ、フォント関連で何か作りたいなと思ってフォント関連の論文を漁っていたところ、Adobeが出している「DeepFont: Identify Your Font from An Image」という画像から使われているフォントを予測する論文を発見しました。論文自体が2015年で方法自体は今からすると古めの印象を受けるのですが、学習データの作り方や予測のさせ方がめちゃくちゃ参考になりこれベースでいけそうだと感じ作ることにしました。3月からちょこちょこやっていたのですが、数日前に4月10日がフォントの日であることを知ってめちゃくちゃ焦って作りましたが、何とか形にはすることができました。
サービス的な部分
類似サービスとしては以下のようなものがあります。WhatFontは日本語フォントにも対応していますが画像から検索はできません。画像から検索できるサービスは日本語フォントには対応していません。「フォントピント」は現状で画像から日本語フォントを検索できる唯一のサービスです。(これが言いたかった)
- webページ上のフォント検索
- 画像からのフォント検索
また、今のところ対応しているフォントはGoogle Fontsに存在する日本語フォントのみです。font-weightが異なれば違うフォントとして扱っており117個のフォントに対応しています。作っているときは諦めていたのですが、よくよくAdobe Fontsについて調べると、ライセンス的にCreative Cloudのいずれかのプランを契約すればこのサービスに適用できそうなので、大きく対応フォント数を増やせそうです。これは個人的にとても楽しみなので、すぐに対応したいと思っています。
技術的な部分
まず予測モデルの学習とテストなのですが、これはフォントファイルから任意のテキストを人工的に生成した画像で行っています。フォント数のマルチクラス分類問題です。テストデータにおける精度は、現状の117クラス分類で top-1 accuracy: 66.8% 、top-5 accuracy: 99.6%となっています。つまり、予測した上位5個にはほとんど正解が含まれるので、実際のサイトにおいても予測上位5個を表示しています。
次にシステム的な部分です。機械学習・バックエンド・フロントエンドと割とこれまでの集大成的な感じになりました。

フロントはこれまでの流用でNext.jsで開発してVercelにデプロイしています。バックエンドはFastAPI(Python) で開発してコンテナイメージとして、Lambdaでコンテナを実行しています。API Gateway x Lambda のよくあるサーバレスな構成です。ASGIアプリケーションであるFastAPIとAPI Gateway x Lambdaのアダプタとしてmangumというライブラリを使用しています。mangumを使うとLambda独特の書き方をしなくて済みます(ただDockerfileにはLambda独特の記載が必要でそのまま他の基盤に持っていくことはできそうにありません)。また、フォントの認識とは別に文字の認識をGoogleのCloud Vision APIに投げています。
作ったあとにLambdaでバックエンドを動かすのはちょっとミスったなあと思っています。コンテナ起動時に学習済みモデルの読み込みが必要なので、Lambdaのコールドスタートやスケールアウトでコンテナを起動する際に非常に時間がかかります。そのためProvisioned Concurrencyの機能を使ってあらかじめコンテナを複数個起動しておく必要があるのですが、Provisioned Concurrencyの費用がそこそこ高くそれならFargateなりで常時起動している方が安くなりそうだからです。バックエンドの移行も今後の対応とします。
おわり
ひとまず作ることはできたので、とりあえずは前述のAdobe Fontsを使って対応フォントの数を増やしたいと思います。あとはバックエンドの移行もやりたいです。あと切実なところでいえば、サーバーの運営費が正直そこそこかかる(頑張っても月5000円くらいはかかりそう)ので、趣味でやっているものではあるのですが広告を入れるかBuy Me A Coffee的なものを入れるかしないといけないなあと思っています。
何か改善や欲しい機能などありましたら、Twitterとかで教えてもらえると嬉しいです。というかフォーム的なものを載せないといけないなと思いました。ありがとうございました。
Next.jsのISRとGASでサクッとプライベートを晒す
↓作ったものはこちら
こんにちは、最近個人的にNext.jsを使っているのですが、ISR (Incremental Static Regeneration) の機能を使う機会がありませんでした。ISRは一度アプリケーションをビルドした後も特定のページを定期的に再ビルドする機能です。あまり更新頻度の高くない動的なコンテンツを含むページにおいて、リクエストのたびにHTMLを生成するのではなく生成済HTMLを返却したい場合などに使うと理解しています。
そして最近(時間的な意味でなく自分が見たという意味で)、スプレッドシートをデータソースにしたGAS (Google Apps Script) によるAPIの例を何個か見ていて、サクッと何か作りたいときには良い選択肢だなと思っていました。また、ISRとスプレッドシートのデータを返却するAPIの組み合わせはめちゃくちゃ相性が良いのではと思いました。というのも、GASがスプレッドシートのデータを取得する部分が割と時間がかかるのと、またスプレッドシートを操作するGoogle Sheets APIのリクエスト制限も強いので、頻繁にリクエストされるケースには向いてなさそうです。しかし、ISRによるビルドが完了してない場合は前回の生成済HTMLを返すので前者の問題が、ISRによる再ビルド時のみAPIを呼ぶので後者の問題が解決されます。
よって、Next.jsのISRとGASでサクッと何かを作ろうと思ったのですが、特にサクッと集まるデータが思い浮かびませんでした。こういうときは自分の身を削るしかないので、プライベートなデータを使います。今回は、ぼくのクラシルのお気に入りレシピを誰でも見ることのできるページを作りました。おそらく今のところ、2022年で一番需要の無い公開情報です。
なお、この記事の内容は以下の記事に強く影響を受けています。
サクッとな構成

ぼくがスマホのクラシルアプリから好きなレシピを保存します。クローラーがクラシルのwebサービスに定期的にログインして、ぼくのお気に入りレシピを収集してスプレッドシートに書き出します。VercelにデプロイされたNext.jsアプリがGASのAPIに定期的にリクエストを送信して、返却されたレシピを用いてHTMLを生成します。ぼくのお気に入りを気になる人たちがページにアクセスすると、生成されたHTMLが返却されます。
またGASはローカルでかつTypeScriptで開発するため、claspというGoogleのツールを使っています。
『INTP型自分の取扱説明書』で自分と向き合う
最近Kindle Unlimitedで気になった本を読んでいるのだが、その中でも『INTP型自分の取扱説明書』という本が気になって読んだ。
MBTIにおける16の分類のうちの1つであるINTP型に対する解説書だ。『The INTP Personality Careers Relationships & the Quest for Truth and Meaning』という本を要約した内容らしい。10年以上前からMBTI好きでINTPの自分にとって読まない手はなかった。
本の内容の抜粋と要約
まず、ユングのタイプ論で定義される、意思決定の際に働く内面の機能を心理機能と呼び、以下の4つの機能がある
- 思考(Thinking)
- 直感(iNtuition)
- 感覚(Sensing)
- 感情(Feeling)
これらを外交的(Extraverted)と内向的(Introverted)に分けることで以下の8つの心理機能がある。(各機能の特徴などは 心理機能とは - 16タイプの性格分類まとめ Wiki* などを参照)
- 外向的感覚(Se)
- 内向的感覚(Si)
- 外向的直観(Ne)
- 内向的直観(Ni)
- 外向的思考(Te)
- 内向的思考(Ti)
- 外向的感情(Fe)
- 内向的感情(Fi)
MBTIでは、16個のタイプそれぞれで4つの心理機能を持つ。発達している順に第一機能(主機能)、第二機能(補助機能)、第三機能(代替機能)、第四機能(劣等機能)という。INTPの場合は以下である。
- 主機能:内向的思考(Ti)
- 補助機能:外交的直感(Ne)
- 代替機能:内向的感覚(Si)
- 劣等機能:外交的感情(Fe)
INTPは、感情(Fe)より思考(Ti)を元に意思決定を行う。いわゆる考えてから行動するタイプ。また、考えるときに過去の経験や既存の方法(Si)ではなく新しい独自の方法(Ne)を生み出したいタイプ。
INTPの4つの心理機能をバランス良く活用することで、以下の好循環で高いパフォーマンスを出せる。
- 思考を働かせて問題解決のため独自のプロセスを構築
- 直感によって他の分野から応用できそうな方法を取り入れる
- 過去の経験を参考に、自分にとって納得感のあるプロセスを特定する
- 周りの感情を考慮して、win-winになるように行動する
- 行動することで経験値がたまり更に高レベルのプロセスを考えることができる
ただし、バランスが崩れると以下のような問題が発生する。
思考と直感の喧嘩
答えを求めたい思考(Ti)と他の正解を探索したい直感(Ne)が対立する。結果的に何も決めれなくなる。これを回避するためには、自分の中に基礎となる理論や哲学(自分はどういう人間で何をしたら幸せなのか)が必要。これには、正解がわからない中で前に進む、深く考えず行動して経験を得るといったことが必要。
思考に行動が伴わない
物事の意味を探索すること(Ne)とその中で行動すること(Si)の間で対立する。INTPの幸せは興味深い発見やひらめき(Ne)に依存している。そういったインスピレーションを必要とすることには好不調の波があるので、不安定な状態になりやすい。これを回避するには、何も考えず手を動かす(Siを働かせる)ことで不調を抜け出すきっかけになる。
自己満足なアウトプットになりがち
思考(Ti)は他者にオープンというよりは、自分にとって納得できる方向でロジックを組む。他人の意見を加味することが苦手となる。これを回避するには、Neにより自分の考えから一旦離れ異なる目線から思考したり、Feにより相手の目線にたって思考する。
また、INTPは基本的に1人の時間を好む。しかしずっと1人が良いわけではなく、Neによる他分野の学習やFeによる承認欲求や他者貢献のため人と関わりたいときがある。無目的で人関わることは避ける。直接他者と関わらなくても周りに人がいるだけでエネルギーを得られるので、いるだけで良いゆるいコミュニティに所属すると良い。
感想
自分が唯一得意かもしれないと思っている、「他分野で成功している方法を自分問題分野への応用すること」が内向的思考(Ti)と外交的直感(Ne)の機能によって説明されていて面白いと思った。挙げられている3つの問題も完全にそのとおりで、気をつけなければと思う。最近は不調の波にいることは自覚しており、思いついたものを深く考えず作っているので、意外と問題解決の行動ができているのでは?と思えてきた。INTPのキャリアについて本にも書かれているが、思考と直感のバランスをとるために自分自身の指針みたいなものを持たないといけなく、これには自分の中の理論やアイデアを実際に試行錯誤する必要があり、基本的にキャリアの連続性を重視する労働市場とはめちゃくちゃ相性が悪いのではと思った。
他者との関わりの部分もそのとおりで、カフェなどの少し雑音がある空間が好きなのもINTPの機能からなのかもしれない。ゆるいコミュニティを求む。
第四機能ではあるが外交的感情(Fe)があるとおり、誰かの助けのために行動するのは割と好きだ(これが行き過ぎると承認欲求につながるのだろうけど)。自分がしたいことというよりは、誰かの助けになることを選んでいった方が良い方向にいくのかもと思った。
占いのキュレーションサービス「Ftune」を作った
こんにちは、突然ですが僕たち日本人にとって空気のように身近にあるものといえば何でしょうか?それはもちろん「占い」です。朝の情報番組にはほぼ確実に占いのコーナーがあり、僕たちはそれを何の疑いもなく享受しています。ニュースと占いは2つが合わさって1つと言っていいでしょう。そして、平均的日本人である僕はもれなく占いが好きです。(偏見ですがこのブログを読む人はあまり占いに興味がないでしょう)
占いが確定的なら問題ないのですが、残念ながら占いとは曖昧なもので各メディアで別々の占いが取り扱われています。僕たちはそれをくまなく確認したいものです。僕は無職なので何ら問題はないのですが、現代人は忙しいのでせいぜい1つか2つの占いに目を通して終わりでしょう。本当にそれでいいのでしょうか?あらゆる物事は比較することで真実が見えてきます。出来るならもっと沢山の占いを確認するべきです。
でも時間がないという方におすすめするサービスがこれ、「Ftune」です。Fortuneからorを取り除いたものです。占いから曖昧性を無くそうという高い目標があります。この記事を書いているときに思いつきました。
Androidはアプリもあります。(iOSはありません…詳細は後述)
https://play.google.com/store/apps/details?id=app.bootch.ftune
実際何故作ったか
日々コンテンツが変化するサービスを自分で持っておきたかったというのが大きな理由です。新しかったり自分が試したことなかったりする技術を、実際に導入して挙動を確認できる環境が欲しかったのです。日々コンテンツが変化するサービスとしては、ユーザー投稿型のサービスや自分でコンテンツを投稿することが考えれますが、前者はそもそもユーザーが集まらないとどうにもならないのと、後者は単純にめんどくさいのでやめました。キュレーションの中でも、占いは身近にありふれている割にこれといったサービスが思い浮かばなく、かつ実際に調べても存在しなかったので決定しました。また、最悪誰も使わなくても自分は使えるものが良かったので占いにした、という理由もあります。
全体構成
全体の構成をざっくり説明します。各コンポーネントの詳細は元気があれば別の機会で書きます。
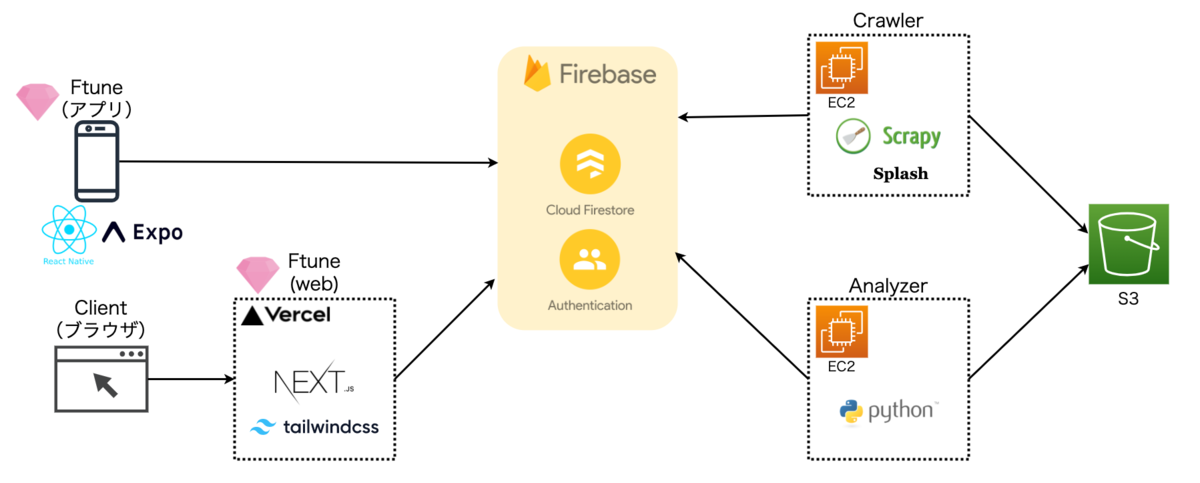
Crawler
間違いなく一番めんどくさかったのは占いを収集するCrawlerです。現状30程度のドメインを対象とした割と中規模くらいのクローラーを作れたので良い経験でした。
言語はPythonでScrapyというフレームワークを使っています。Scrapyはページの辿り方や内容のパース以外のめんどくさい部分をほとんど設定で制御できるので便利です。ただ、JavaScriptによってクライアント側でゴリゴリHTMLを生成するページには対応できません。そこで一部Splash (scrapy-splash) というクローラーとwebサイトとの通信を中継してJavaScriptを実行した結果を返してくれるライブラリと組み合わせて使用しています。またクローリングの結果をFirebaseのFirestoreとS3に保存しています。Firestoreはクライアント側からの読み込み、S3はクローリングのたびに読み込んで占いのクロール済の判定に使ったり、後述のAnalyzerの入力になったりします。
そして、ひとまず単純なEC2にデプロイして日々運用しています。というのも極力お金をかけたくなく、AWSの1年の無料枠の中で動かしたかったからです。少しでも利益を得られるようになったらFargateなりに移行したいところです。
めんどくさいところは多々あったのですが、長くなってしまうので別にします。
Analyzer
せっかくCrawlerで本文まで収集しているので、何か分析した結果を出そうと思って作りました。現状では、ユーザーごとの占いのキーワードや独自のスコアを出しています。(ユーザーごとと言いつつ現状は星座別です…)唯一独自のコンテンツの部分ではあるのですが、やってることは本当に単純で2時間くらいで作りました。一応何をやっているかは説明しないことにしておきます。
こちらもCrawlerと同じEC2インスタンスにデプロイして動かしています。
Ftune(アプリ)
最初はアプリだけの予定でした。React NativeによりiOSとAndroidのクロスプラットフォームで開発しました(実際世に出ているのはAndroidだけですが…)。アプリを作るのはほぼ初めてで、クロスプラットフォームで開発したかったのでReact Nativeを選択しました。実際今の第一候補としてはFlutterなんじゃないかと思いますが、「react native」で検索したら「react native オワコン」とサジェストされるところに逆張り精神がひっかかり選びました。あと最近Reactを使いだしたので、Reactをベースにできるのも大きいところでした。
Ftune(web)
後述しますがiOSアプリが審査に通る気配が無く、Androidだけでは不安に感じたのでwebバージョンも作ることにしました。こちらはNext.jsで開発しました。単純にReactベースに1個別の技術使いたかったので選択したくらいです。一応SEO的なことも考えました。ただメインのページが現状Client Side Rendering (CSR) になっており正直あんまりNext.jsの恩恵は無いかもしれません。
こちらは、Vercelにデプロイして動かしています。開発元が同じだけあってNext.jsとVercelはほぼセットみたいな雰囲気を感じますね。何も意識しなくても自動デプロイなどCI/CDの恩恵を受けられるのが良いですね。pull request別にプレビューのURLが用意されて確認できるのもめちゃくちゃ良いと思いました。
開発の経緯
11月後半から12月前半にかけてCrawlerの開発を行い、12月後半でアプリを作りました。そして12月24日にiOSアプリをApp StoreにAndroidアプリをGoogle Playに提出しました。Google Playは審査を通過してリリースされたものの、App Storeではリジェクトされました。事前に軽く調べていた感じではキュレーションアプリなので、Guideline 4.2.2 - Design - Minimum Functionalityの理由でリジェクトされることは想定しており、実際ガイドライン違反も指摘されました。こちらは、機能を追加していけばいいと思っていたのですが、想定外のGuideline 4.3 - Design - Spam違反も指摘されました。普通に「占いのアプリは飽和してるからすごい機能がないとリジェクト」と書いてありました。2020年3月ごろに占いの指定が追加されたようです。
少しの望みをかけて、とりあえずGuideline 4.2.2 - Design - Minimum Functionality違反へのよくある対策を調べてオフラインでもコンテンツを表示できるようにしたり、お気に入り機能をつけたりして再度提出しました。年末年始はほぼ毎日1つ機能を追加しては再提出を繰り返していた気がします。5,6回リジェクトされて軽く取れる打ち手がなくなったとこで、App Storeの審査を通すことは諦めました。
1月前半は、App Storeリジェクトのショックでやる気がなくなっていたり、突発性難聴になったりでほとんど作業ができませんでした。そして何となくやる気を取り戻し、1月後半からweb版の開発にとりかかり現在に至るという感じです。
おわりに
ひとまずは、目的であった日々コンテンツが変化するサービスを作ることができて良かったです。ここ数ヶ月フロント周りを触ったこともあって、フロント界隈で話されている内容が何となく何言ってるか分かるくらいにはなったと思います。今後も改良を重ねていければなと思います。
羊文学の「光るとき」は世界の美しさを説明した初めての曲なんじゃないか?
去年から羊文学にはまっている。そして今年に入って待ちに待った「光るとき」の配信が始まったので聴いている。何回か聴いているとスッと体の中に入ってくるフレーズがある。サビの「何回だっていうよ 世界は美しいよ 君がそれを諦めないからだよ」というところだ。自分は今まで諦めていたんだなと、何だか納得させられた気分になる。
ここでふと、「世界は美しい」というありふれたフレーズなのにどうしてこんな良さを感じるのか考えてみる。それはやっぱり、「君がそれを諦めないから」という理由が力強く与えられるからだと思う。個人的に「世界は美しい」という表現はこれまで、「世界の美しさを無条件に受け入れる」「世界の美しさに急に気づく」「世界は美しいことを根拠として主張を述べる」パターンが多かったんじゃないかと思っている。そこで世界の美しさの理由に言及した歌詞が今まであったのか検証してみる。
検証データ
歌ネットというサイトからクローリングして歌詞を集めることにした。最初は全歌詞を収集して「世界は美しい」というフレーズを含む歌詞を抽出しないといけないかと思っていたが、歌詞の全文検索ができたので「世界は美しい」というフレーズを含む歌詞だけに絞ったあと収集した。一気に歌ネットが好きになった。対象の歌詞は74個存在した。
検証方法
対象歌詞の中で、「世界は美しい」というフレーズを含む段落を抽出する。その段落に対して形態素解析を行い、接続助詞が存在する段落を理由を表す可能性があるとして抽出する(接続助詞には「から」や「ので」など理由を表す助詞が存在するので)。ただし、頻出かつ理由を表さない次の接続助詞のみ含む場合は除外した。て, ば, と, し, が, で。ここで抽出された歌詞について、「世界は美しい」理由を説明しているか目視で確認する。(もっと良い方法もあった気がするけど思いつかなかった…)形態素解析には Sudachi (SudachiPy) を使用した。

結果
上記の方法で抽出された歌詞は、23個存在した。ここからはひとつひとつ歌詞の中身を見ていく。
まずは羊文学の「光るとき」。これは言わずもがな理由が説明されている。問題は他にもそんな歌詞があるかどうかだ。確認したところ、何と他にも普通に存在した。それぞれ、工藤晴香の「アナタがいるから」、忘れらんねえよの「美しいよ」、摩天楼オペラの「ICARUS」、かりゆし58の「アイアムを」、DEENの「レールのない空へ」だった。
理由を細かく分類すると、「アナタがいるから」と「美しいよ」は美しさが「あなた」という特定の誰かに依存するものであり、「ICARUS」と「アイアムを」、「レールのない空へ」は美しさに普遍的な理由を与えたものだった。「光るとき」も後者であり、つまり同じように「世界は美しい」理由を説明している曲は4曲あり、「光るとき」が初めてというわけでもなかった。

おわりに
もしかしてと思った仮説を検証してみたが、別にそんなことはなかった。まあでも別にそんなことはどうでもいいのだ。「光るとき」が良いという事実は変わらない。気になったらぜひ聴いてみてもらえると嬉しい。
そして最後に、同じフレーズに言及している記事を見つけたので参考にリンクしておくことにする。