GraphQLのN+1問題をDataloaderで解決
こんにちは。株式会社PRVENT開発部、バックエンドチームの横川です。
今回は、GraphQLで発生するN+1問題と弊社の解決方法を紹介しようと思います。
N+1問題とは?
ループ処理の中で都度SQLが発行され、SQLが大量増殖してしまう問題です。
- テーブルAからN件のデータ取得を1回
- テーブルBから、テーブルAの各行に紐づくデータを(1件ずつ)取得を計N回
1回+N回のSQLが発行されるので、N+1問題です。(実行順で言うと1+N)
Nの数が多いとその分処理に時間がかかりますし、DBにも負荷がかかります。
GraphQLで起きるN+1問題
前回の記事のコードをリファクタしつつ、まずはN+1対策せずにお薬データを全件取得するQueryを実装しました。
# schema.graphqls type Query { Medicine(ID: ID!): MedicineDetail! Medicines: [MedicineDetail!]! # ←全てのお薬取得 } # お薬 type MedicineDetail { ID: ID! name: String! medicneCategory: MedicineCategoryDetail! } # お薬カテゴリ type MedicineCategoryDetail { ID: ID! name: String! }
// schema.resolvers.go(一部抜粋) package graph import ( // 省略 ) // お薬カテゴリ取得 (お薬N件に対してN回実行) func (r *medicineDetailResolver) MedicneCategory(ctx context.Context, obj *model.MedicineDetail) (*model.MedicineCategoryDetail, error) { // DB接続 db := infra.DBConnection() defer db.Close() // sqlログ出力設定 db = infra.LogConf(db) var m model.MedicineCategory // お薬カテゴリ取得 err := db.QueryRow("SELECT * FROM medicine_categories where id = $1", obj.MedicneCategory.ID).Scan(&m.ID, &m.Name) if err != nil { return nil, err } return &model.MedicineCategoryDetail{ ID: m.ID, Name: m.Name, }, nil } // お薬全件取得 func (r *queryResolver) Medicines(ctx context.Context) ([]*model.MedicineDetail, error) { db := infra.DBConnection() defer db.Close() db = infra.LogConf(db) ms := []*model.MedicineDetail{} // お薬全件取得 rows, err := db.Query("SELECT * FROM medicines") if err != nil { return nil, err } defer rows.Close() for rows.Next() { var m model.Medicine if err := rows.Scan(&m.ID, &m.Name, &m.MedicineCategoryID); err != nil { return nil, err } ms = append(ms, &model.MedicineDetail{ ID: m.ID, Name: m.Name, MedicneCategory: &model.MedicineCategoryDetail{ ID: m.MedicineCategoryID, }, }) } return ms, nil }
↓こんなデータを用意して
medicine_categories(お薬カテゴリテーブル)
| ID | name |
|---|---|
| 1 | 頭痛薬 |
| 2 | 風邪薬 |
| 3 | 痒み止め |
medicines(お薬テーブル)
| ID | name | medicine_category_id |
|---|---|---|
| 1 | ロキソニン | 1 |
| 2 | バファリン | 2 |
| 3 | ムヒ | 3 |
以下のリクエストを投げると

QueryContext query="SELECT * FROM medicines" QueryContext args=["2"] query="SELECT * FROM medicine_categories where id = $1" QueryContext args=["3"] query="SELECT * FROM medicine_categories where id = $1" QueryContext args=["1"] query="SELECT * FROM medicine_categories where id = $1"
お薬3件取得に対して3回お薬カテゴリ取得のSQLが発行されます。
REST APIなどで発生するN+1問題だとORMのメソッドで関連データを先読みしたり、テーブル結合で解決するかと思います。
ですが、GraphQLだと取得するデータをクライアント側で選択できることが強みなので関連データの先読みはしたくないです。
このような問題を弊社ではDataloaderライブラリを使うことで解決しています。
Dataloaderとは
データ取得をバッチ化するためのライブラリです。
先ほどお薬カテゴリの取得が3回発生しましたが、Dataloaderはそれを順番に実行するのではなく一定時間待機してその間に発生したリクエスト(取得したいデータのキー)を蓄積します。
その後、溜まったキーをSQLのin句などでまとめて取得できる仕組みです。
オリジナルは Facebook社が開発する graphql/dataloader で、弊社ではGo用のDataloaderライブラリ vektah/dataloaden を使用しています。
Dataloader導入
githubを参考にしつつDataloaderを導入します。
インストール後dataloaderディレクトリを作成し以下のようなdataloader.goファイルを作成しておきます。
// dataloader/dataloader.go package dataloader
その後、dataloaderディレクトで下記コマンドを実行しソースを自動生成します。
go run github.com/vektah/dataloaden ${Loader名} ${取得するデータのキーの型} ${返却する型へのパス}/${返却する型} go run github.com/vektah/dataloaden MedicineCategoryLoader string *gqlgen-medicines/graph/model.MedicineCategoryDetail
すると、dataloaderディレクトリ配下にファイルが自動生成されるので、それを使うためのミドルウェアを作成します。
// medicinecategoryloader_gen.go(自動生成ファイル) / Code generated by github.com/vektah/dataloaden, DO NOT EDIT. package dataloader import ( "sync" "time" "gqlgen-medicines/graph/model" ) // MedicineCategoryLoaderConfig captures the config to create a new MedicineCategoryLoader type MedicineCategoryLoaderConfig struct { // Fetch is a method that provides the data for the loader Fetch func(keys []string) ([]*model.MedicineCategoryDetail, []error) // Wait is how long wait before sending a batch Wait time.Duration // MaxBatch will limit the maximum number of keys to send in one batch, 0 = not limit MaxBatch int } // NewMedicineCategoryLoader creates a new MedicineCategoryLoader given a fetch, wait, and maxBatch func NewMedicineCategoryLoader(config MedicineCategoryLoaderConfig) *MedicineCategoryLoader { return &MedicineCategoryLoader{ fetch: config.Fetch, wait: config.Wait, maxBatch: config.MaxBatch, } } // MedicineCategoryLoader batches and caches requests type MedicineCategoryLoader struct { // this method provides the data for the loader fetch func(keys []string) ([]*model.MedicineCategoryDetail, []error) // how long to done before sending a batch wait time.Duration // this will limit the maximum number of keys to send in one batch, 0 = no limit maxBatch int // INTERNAL // lazily created cache cache map[string]*model.MedicineCategoryDetail // the current batch. keys will continue to be collected until timeout is hit, // then everything will be sent to the fetch method and out to the listeners batch *medicineCategoryLoaderBatch // mutex to prevent races mu sync.Mutex } type medicineCategoryLoaderBatch struct { keys []string data []*model.MedicineCategoryDetail error []error closing bool done chan struct{} } // Load a MedicineCategoryDetail by key, batching and caching will be applied automatically func (l *MedicineCategoryLoader) Load(key string) (*model.MedicineCategoryDetail, error) { return l.LoadThunk(key)() } // 長いので省略
// middleware/dataloader.go package middleware import ( // 省略 ) const LoaderKey = "Loader" func LoaderMiddleware(next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { // 自動生成されたDataloaderのメソッドを使ってLoader作成 loader := dataloader.NewMedicineCategoryLoader(dataloader.MedicineCategoryLoaderConfig{ MaxBatch: 100, // 最大100リクエストバッチ化する Wait: 10 * time.Millisecond, // 10ms待機する // 最大10ミリ秒待機した結果 or 100リクエスト分のお薬カテゴリIDのスライスが keys という名前で渡ってくる。 Fetch: func(keys []string) ([]*model.MedicineCategoryDetail, []error) { var errors = []error{} db := infra.DBConnection() defer db.Close() db = infra.LogConf(db) // お薬カテゴリをまとめて取得する rows, err := db.Query("SELECT * FROM medicine_categories WHERE id = ANY($1)", pq.Array(keys)) if err != nil { errors = append(errors, err) return nil, errors } defer rows.Close() ms := map[string]*model.MedicineCategoryDetail{} // idごとに取得したお薬カテゴリをマッピング for rows.Next() { var m model.MedicineCategory if err := rows.Scan(&m.ID, &m.Name); err != nil { errors = append(errors, err) return nil, errors } ms[m.ID] = &model.MedicineCategoryDetail{ ID: m.ID, Name: m.Name, } } // 渡ってきたkeysの順番にお薬カテゴリを並び替え result := make([]*model.MedicineCategoryDetail, len(keys)) for i, key := range keys { result[i] = ms[key] } return result, nil }, }) // contextにloaderをセット ctx := context.WithValue(r.Context(), LoaderKey, loader) r = r.WithContext(ctx) next.ServeHTTP(w, r) }) } // loaderを使うための関数(リゾルバで呼び出す) func MedicineCategory(ctx context.Context, id string) (*model.MedicineCategoryDetail, error) { v := ctx.Value(LoaderKey) loader, ok := v.(*dataloader.MedicineCategoryLoader) if !ok { return nil, errors.New("failed to get loader from current context") } return loader.Load(id) }
// server.go package main import ( // 省略 ) const defaultPort = "8080" func main() { port := os.Getenv("PORT") if port == "" { port = defaultPort } srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &graph.Resolver{}})) http.Handle("/", playground.Handler("GraphQL playground", "/query")) http.Handle("/query", middleware.LoaderMiddleware(srv)) // ミドルウェアでハンドラーをラップ log.Printf("connect to http://localhost:%s/ for GraphQL playground", port) log.Fatal(http.ListenAndServe(":"+port, nil)) }
リゾルバもDataloaderを使うように修正します。
// schema.resolvers.go(一部抜粋) package graph import ( // 省略 ) // お薬カテゴリ取得 (お薬N件に対してN回実行) func (r *medicineDetailResolver) MedicneCategory(ctx context.Context, obj *model.MedicineDetail) (*model.MedicineCategoryDetail, error) { // 処理はLoaderに全て寄せたのでリゾルバでは呼ぶだけ return middleware.MedicineCategory(ctx, obj.ID) }
以上で導入は完了です。
ちなみにお薬カテゴリの取得が発生した場合の挙動が以下です。
- 10ms待機してIDを蓄積
- 溜まったIDを
where = ANY($1)に入れてお薬カテゴリをまとめて取得 - それぞれのお薬に紐付いて返却
リクエストを投げた結果がこちらです
QueryContext query="SELECT * FROM medicines" QueryContext args=["{\"3\",\"1\",\"2\"}"] query="SELECT * FROM medicine_categories WHERE id = ANY($1)"
お薬カテゴリ取得のSQLが1回になりました🙌
最後に
今回は、GraphQLで発生するN+1問題と、Dataloaderを使った解決方法を紹介しました。
自分がDataloaderを導入した1年ほど前は、gqlgen公式のdataloaderのページで今回紹介したvektah/dataloadenの使用方法が書かれていましたが、いつの間にか graph-gophers/dataloaderに変わってたので、こちらも触ってみようと思います。
GraphQLライブラリ「gqlgen」でサーバー構築
こんにちは。株式会社PRVENT開発部、バックエンドチームの横川です。
今回は弊社で使用しているGraphQLライブラリ 「gqlgen」と実際にgqlgenを使ったGraphQLサーバーの構築方法を紹介したいと思います。
なぜ書こうと思ったか
弊社のプロダクトのバックエンド開発でどんな技術を使っているか知ってもらいたいと思い、使用している主要ライブラリの一つ「gqlgen」を紹介することにしました。
最初に弊社のgqlgen使用状況とgqlgen, GraphQLについて軽く説明した後、実際にgqlgenを使いサーバーの構築してGraphQLの特徴について説明できたらと思います。
弊社のgqlgen使用状況
現在以下3つのプロダクトのバックエンドでgqlgenを採用してます
- Mystar(生活習慣記録アプリ)
- MystarPRO(利用者さんの進捗管理システム)
- Mymonitor(取引先健保用システム)
弊社ではバックエンドにRubyとGoを使ったシステムがありますが現在Goのシステムは全てgqlgenを採用しています。
gqlgenとは
GraphQLサーバーを構築するためのライブラリです。(github: https://github.com/99designs/gqlgen)
自分は他のライブラリを使ったことがないので比較できないですが、GraphQLライブラリには「コードファースト」と「スキーマファースト」の二種類があり、gqlgenは「スキーマファースト」のライブラリです
ちなみに GraphQL とは
GraphQLは、APIのクエリ言語であり、データ用に定義した型システムを使用してクエリを実行するためのサーバー側ランタイムです。
引用: https://graphql.org/learn/
公式にはこう書かれています。
実際の流れとして、リクエストボディに取得したいデータをクエリ言語で定義してサーバーへリクエストを投げると、取得したいデータだけjsonで返ってきます。

画像はクライアントツールを使ったリクエスト(左)とレスポンス(右)です。
下記のようにJSON形式でリクエストも可能です。
$ curl -H "Content-Type:application/json" -X POST http://localhost:8080/query -d '{ "query" : "query { users{ id, name }}" }' {"data":{"users":[{"id":"1","name":"横川"}]}}
REST APIだと、取得したいデータによってエンドポイントを変えるかと思いますが、GraphQLだとエンドポイントは一つで取得するデータをクライアント側で指定できます。
このようなGraphQLサーバーをgqlgenを使い簡単に構築できます。
gqlgenを使ってサーバー構築
gqlgenを使ってお薬データを取得するGraphQLサーバーを構築してみます。
まずはgithubのクイックスタートを参考に、gqlgenの初期化コマンド実行まで進めます。
mkdir gqlgen-medicines cd gqlgen-medicines go mod init gqlgen-medicines printf '// +build tools\npackage tools\nimport _ "github.com/99designs/gqlgen"' | gofmt > tools.go go mod tidy go run github.com/99designs/gqlgen init
いくつかファイルが自動生成されているかと思いますが、今回編集するのは以下の3ファイルです。
- graph/schema.resolver.go
- リクエストを元に実際の処理を実装するresolverファイル。
- graph/schema.graphqls
- GraphQLスキーマを定義します。このファイルをもとに他のファイルのコードが再生成されます。
- gqlgen.yml
- gqlgenの設定ファイルです。
まず、graph/schema.graphqlsを編集します。
今回は以下のようにしました。
type Query { Medicine(ID: ID!): MedicineDetail! } # お薬 type MedicineDetail { ID: ID! name: String! medicneCategory: MedicineCategoryDetail! } # お薬カテゴリ type MedicineCategoryDetail { ID: ID! name: String! }
- IDを引数に、お薬データを一件取得するクエリを定義してます。
- type.MedicineDetail(お薬)はMedicineCategoryDetail(お薬カテゴリ)と紐づいています。
続いて、gqlgen.ymlファイルを以下のように編集します。
# 省略
models:
ID:
model:
- github.com/99designs/gqlgen/graphql.ID
- github.com/99designs/gqlgen/graphql.Int
- github.com/99designs/gqlgen/graphql.Int64
- github.com/99designs/gqlgen/graphql.Int32
Int:
model:
- github.com/99designs/gqlgen/graphql.Int
- github.com/99designs/gqlgen/graphql.Int64
- github.com/99designs/gqlgen/graphql.Int32
# ここから↓追記
MedicineDetail:
fields:
medicneCategory:
resolver: true
- ここで、query.MedicineでmedicneCategory(お薬カテゴリ)を取得する際に呼ばれるメソッド生成の設定をしてます。
ここまで一度 go run github.com/99designs/gqlgen generateを実行し schema.resolvers.go ファイルのコードを再生成します。
メソッド自体は自動生成されるので中の処理を実装していきます。
package graph // This file will be automatically regenerated based on the schema, any resolver implementations // will be copied through when generating and any unknown code will be moved to the end. import ( "context" "database/sql" "gqlgen-medicines/graph/generated" "gqlgen-medicines/graph/model" "os" _ "github.com/lib/pq" "github.com/rs/zerolog" sqldblogger "github.com/simukti/sqldb-logger" "github.com/simukti/sqldb-logger/logadapter/zerologadapter" ) const dbConn string = "host=localhost port=5432 user=postgres password=password dbname=gqlgen_sample sslmode=disable" type Medicine struct { ID string Name string MedicineCategoryID string } type MedicineCategory struct { ID string Name string } func dbConnection() *sql.DB { db, err := sql.Open("postgres", dbConn) if err != nil { panic(err) } return db } // sqlログ出力設定 func logConf(db *sql.DB) *sql.DB { logger := zerolog.New( zerolog.ConsoleWriter{Out: os.Stdout, NoColor: false}, ) db = sqldblogger.OpenDriver( dbConn, db.Driver(), zerologadapter.New(logger), ) return db } // MedicneCategory is the resolver for the medicneCategory field. func (r *medicineDetailResolver) MedicneCategory(ctx context.Context, obj *model.MedicineDetail) (*model.MedicineCategoryDetail, error) { db := dbConnection() defer db.Close() db = logConf(db) var m MedicineCategory err := db.QueryRow("SELECT * FROM medicine_categories where id = $1", obj.MedicneCategory.ID).Scan(&m.ID, &m.Name) if err != nil { return nil, err } return &model.MedicineCategoryDetail{ ID: m.ID, Name: m.Name, }, nil } // Medicine is the resolver for the Medicine field. func (r *queryResolver) Medicine(ctx context.Context, id string) (*model.MedicineDetail, error) { db := dbConnection() defer db.Close() db = logConf(db) var m Medicine err := db.QueryRow("SELECT * FROM medicines where id = $1", id).Scan(&m.ID, &m.Name, &m.MedicineCategoryID) if err != nil { return nil, err } return &model.MedicineDetail{ ID: m.ID, Name: m.Name, MedicneCategory: &model.MedicineCategoryDetail{ ID: m.MedicineCategoryID, }, }, nil } // MedicineDetail returns generated.MedicineDetailResolver implementation. func (r *Resolver) MedicineDetail() generated.MedicineDetailResolver { return &medicineDetailResolver{r} } // Query returns generated.QueryResolver implementation. func (r *Resolver) Query() generated.QueryResolver { return &queryResolver{r} } type medicineDetailResolver struct{ *Resolver } type queryResolver struct{ *Resolver }
query.Medicineが呼ばれた時の処理はfunc (r *queryResolver) Medicine(...)で、medicneCategoryを取得する処理は func (r *medicineDetailResolver) MedicneCategory(...)です
これでGraphQLサーバーの構築は完了です。
リクエストを投げてみる
GraphQLサーバーの構築ができたのでリクエストを投げてみます。
以下のようなDBを用意しました。
medicine_categories(お薬カテゴリテーブル)
| ID | name |
|---|---|
| 1 | 頭痛薬 |
medicines(お薬テーブル)
| ID | name | medicine_category_id |
|---|---|---|
| 1 | ロキソニン | 1 |
go run server.goでサーバーが起動するのでhttp://localhost:8080 にアクセスしてお薬データとお薬カテゴリを取得するリクエストを投げてみます

無事に取得できています。
発行されたSQLは以下です。
QueryContext args=["1"] query="SELECT * FROM medicines where id = $1" QueryContext args=["1"] query="SELECT * FROM medicine_categories where id = $1"
次に、お薬データのみ取得してみます。

こちらも想定通りお薬データのIDとnameのみ取得できてます。
発行されたSQLは以下です。
QueryContext args=["1"] query="SELECT * FROM medicines where id = $1"
お薬カテゴリを省いたことで、func (r *medicineDetailResolver) MedicneCategory(...)が呼ばれなくなりました。
REST APIだとエンドポイントごとで返すリソースが決まっているので、お薬データだけが必要なページでもお薬カテゴリの取得が発生してしまいます。
GraphQLだとお薬カテゴリが必要なページでのみリクエストに加えれば良いので、無駄なSQLの発行を防ぐことができます。
まとめ
今回は弊社で使用しているGraphQLライブラリ「gqlgen」を使い、構築したサーバにリクエストを投げてみて、そこから分かるGraphQLの特徴を一つ紹介しました。
GoでGraphQLサーバーを構築してみようという方、是非一度使ってみてはいかがでしょうか!
branch名を使ってrelease-drafterを楽に運用する。
PREVENT開発部、フロントエンドチームの高田(@tockii_ )です!
今回は開発を担当しているリポジトリに release-drafter を導入するに至った経緯と設定について記事を書きました。
書いていること
- release-drafter を導入した経緯
- release-drafter とは?
- branch名を利用して運用する設定
書いてないこと
- release-drafterの初期導入方法
- 導入方法についてはこちらをご覧いただけると良いかと思います GitHub リリースページのドラフトを自動生成してくれる Release Drafter を導入する
はじめに
みなさんはこんな経験はありませんか?
- リリースしたのはいいけどReleaseを作るのを忘れてしまう。
- リリースタイミングでtagをつけ忘れてしまう
- tagをつけていないのでReleaseのtargetが変になってしまう
僕はいつもこうでした。毎回プロダクトのリリースが終わると安心感からかそのままスッと退勤ボタンを押してしまい(いつも夜にリリースをするので)Releaseを書いていないことに気づくのは数日後、、、Releaseを書くのもエンジニアの大事な仕事なのですが、やらなくてもアプリは問題なく動くのでつい忘れがちになってしまいます。
また、Releaseを手書きで書くのは案外面倒なので、毎回ただPRの番号を書いただけの簡素なものになってしまい、イマイチ可読性が良くありません。
今回は上記のような問題を解決するためにrelease-drafterを導入しました。
release-drafterとは?
GitHubのRelease Draftとtagを自動で作成してくれる GitHub Actionsのワークフローです。
release-drafterのgoodな点
途中から導入をしても簡単な設定でいい感じにバージョンタグとバージョンを自動で作ってくれる。
Readmeに書いているexampleの設定を使うことで、自動で過去のtagなどから最新のバージョンを採番してくれます。
Privateなリポジトリにも対応している
現在Privateのリポジトリで使用していますが、問題なく運用できています。
手で作るのが面倒なちょっと凝ったReleaseを作ってくれる。
これはただの見た目の問題ですが、PR番号が箇条書きなだけのReleaseより格段に視認性の高いReleaseを作ってくれます。以下の画像は弊リポジトリで生成されたReleaseです。
ReleaseはPR番号で自動的にタイトルを表示してくれないんで、いつも手書きで書いていたんですがその苦労とも一瞬でおさらばできます。

branch名を使った設定を行う
release-drafterはexampleの設定を使うだけですぐにでも動かすことができますが、そのままだとラベルを手動でPRにつける作業が発生します。大変ではないですが、こういった細かい作業はどうしても忘れがちになってしまうため、この辺りも既存の運用をもとに楽にしたいところです(後述しますが、ラベルを貼り忘れても完全手運用よりは楽に修正できます)
そこで、現状プロジェクトで規定しているブランチ名の付け方が release-drafterの autolabelerと相性が良さそうだったので、設定をしてみました。
以下が autolabeler を追加したymlです
name-template: 'v$RESOLVED_VERSION 🌈'
tag-template: 'v$RESOLVED_VERSION'
categories:
- title: '🚀 Features'
labels:
- 'feature'
- title: '🔧Bug Fixes'
labels:
- 'fix'
change-template: '- $TITLE @$AUTHOR (#$NUMBER)'
change-title-escapes: '\<*_&' # You can add # and @ to disable mentions, and add ` to disable code blocks.
version-resolver:
major:
labels:
- 'major'
minor:
labels:
- 'minor'
patch:
labels:
- 'patch'
default: patch
template: |
## Changes
$CHANGES
# 以下がautolabelerの設定🔥
autolabeler:
- label: feature
branch:
- '/^feature[/-].+/'
- label: fix
branch:
- '/^fix[/-].+/'
autolabelerとは?
Release Drafter - GitHub Marketplace
指定した箇所のテキストによってPRにラベルを自動で追加してくれる機能です。
今回はここの branch を使い、以下のように動作するよう設定しました。
- branchの先頭に
featureがあれば feature ラベルを付与 - branchの先頭に
fixがあれば fix ラベルを付与
弊PJでは、ブランチ名の先頭に feature か fix をつけることをルール化しているので、既存の運用に手間を加えることなく簡単にrelease-drafterの管理を行えるようになりました。
ブランチ名を間違えたままマージしてしまった場合は?
もしfeatureやfixなど指定のbranch名を入れていない場合でもreleaseにはPRは全て反映されます。
release-drafterの作成するReleaseはdraft段階のため、手動で公開するタイミングでテキストを書き換えれば問題ありません。
終わりに
Releaseの作成は簡単なようで案外面倒臭く、つい忘れがちになることの一つだと思います。 release-drafterを使ってみなさんも楽をしていきましょう!
社内システムのインフラをHerokuからAWSに移行した話
こんにちは。株式会社PRVENT開発部、バックエンドチームの横川です。
2021年1月に未経験から入社して現在はRubyやGoを書いて仕事してます。
今回は社内システムのインフラをHerokuからAWSへ移行した話を書こうと思います。
はじめに
元々弊社のシステムのインフラは全てHerokuでしたが、現在AWSへの移行を進めており
1つ目に社内システム「Mystar PRO」の移行が2021年7月に完了し、2つ目に弊社のCRMシステム、通称「CRM」(そのまんまw)の移行が2022年3月に完了しました。
弊社には現在インフラ専門のエンジニアはいないので、基本的にはプロダクトの担当者がインフラまで担当しています。
今回は自分が担当している「CRM」をAWSへ移行した話になります。
CRMを簡単に紹介
弊社の提供している「生活習慣改善プログラム」のプログラム開始までのフロー(お申し込み 〜 プログラム開始)をユーザー様ごとに管理できるシステムです。
モノシリックなRailsアプリで、自分が入社して最初にキャッチアップしたプロダクトです。
デプロイ先の決定
まずはデプロイ先ですが
- コンテナでデプロイしたい
- マネージドなサービスを使用したい
- 7月に移行した「Mystar PRO」の バックエンドがECS × Fargate で稼働している
上記の理由から 「CRM」もECS × Fargate で動かすこととしました。
Dockerイメージ作成
Herokuではコンテナでのデプロイをしていなかったので、まずはDockerイメージの作成から取り掛かりました。
開発用のDockerfile(ベースイメージruby:<version>)は先人が用意してくれていましたが、そのままECRへpushして脆弱性をスキャンした所とんでもない数の脆弱性が検出されたため、新しくruby:<version>-alpineをベースイメージにしたデプロイ用のDockerfileを作成しました。
その結果 重要度が高い物を含め200ほどあった脆弱性が、重要度が低いもの1つだけになりました。
ruby:<version>-alpineは軽量なLinuxディストリビューションで有名なAlpineがベースになっていて、脆弱性のあるパッケージが初期段階では入っていないためだと考えられます。
ただ、ruby:<version>-alpineのようなAlpineベースのイメージだとruby:<version>のようなDebianベースのイメージと違い、Railsを動かすために必要なパッケージのいくつかが初期段階から入ってないため、Dockerfileにそれらをインストールするための記述が必要になってきます。
ちなみに今回作成したDockerfileの中身はこんな感じです。
FROM ruby:2.7.5-alpine3.15 ENV BUNDLE_JOBS=2 ENV APP_ROOT /usr/src/crms ARG RAILS_MASTER_KEY WORKDIR $APP_ROOT RUN echo 'gem: --no-rdoc --no-ri' >> ~/.gemrc \ && gem update --system \ && gem install bundler -v 2.3.4 RUN apk update && apk add --no-cache postgresql-dev tzdata yarn libxml2-dev curl-dev make gcc libc-dev g++ COPY Gemfile $APP_ROOT COPY Gemfile.lock $APP_ROOT RUN bundle install COPY . $APP_ROOT RUN yarn install RUN bundle exec rake assets:precompile RAILS_ENV=production EXPOSE 3000 CMD ["ash", "startup.sh"]
変数 RAILS_MASTER_KEY は codebuildでのビルド時に引数で受け取るようにしていて、startup.shでDBマイグレーションとRailsサーバーを起動するコマンドを実行しています。
AWS環境構築
Docker環境も用意できたので続いてAWS環境の構築です。
この時の自分はAWSの経験で言うと、入社前にEC2へのデプロイを一度したことあるくらいのレベルだったので、まずはECS × Fargateで簡単なシステムのデプロイを試した後CRMの環境構築に取り掛かりました。
DBやECSのスペックは大体Herokuのスペックに合わせて作成し、自動デプロイにcodepipeline を使用しました。
社内システムとの連携
動作環境の構築が終わった後、CRMが連携している社内システムとの連携を考える必要がありました。
というのも、CRMのデータは先に出てきた「MystarPRO」というプロダクトとも連携しており、定期バッチでCRMのDBに接続し特定のデータが更新されているかを確認し、更新されていればMystarPROのDBへ反映しています。
「MystarPRO」と「CRM」のAWSアカウントは別になっていて、MystarPRO側のAWSアカウントで定期バッチが動いているため、CRM側のDBのセキュリティグループで別アカウント(MystarPROアカウント)からの通信を許可する必要がありました。
今回詳しくは書きませんが「VPC ピアリング」という機能を使用して接続できるようにしました。
これにより、別アカウントの2つのVPC間で同じネットワーク内に存在しているかのように通信できます。
docs.aws.amazon.com
移行手順の作成
環境構築も完了し動作確認も終えたので最後に移行作業当日の計画を立てました。
実はCRMは「MystarPRO」以外にも連携しているシステムがあり、その中の一つにユーザー様から弊社のサービスへ直接お申し込みをしていただく自社開発のLPサイトとAPIで連携をしています。
お申し込みのタイミングはユーザー様次第なのでダウンタイムが発生しないのが望ましく、その辺りも考慮して計画を立てる必要がありました。
過去のLPサイトからのお申し込み時間から移行作業する日時を決めて、移行中迷わないように細かく手順をまとめていきました。
移行作業
ついに移行当日です。
定期バッチが参照するCRMのDB接続先の変更も必要になるので、「MystarPRO」を担当する先輩エンジニアの方にも立ち会っていただき作業を開始しました。
数日前に、staging環境を移行していたので作業は比較的スムーズに進みました。
VPCピアリングの設定ミスで、定期バッチがうまく動かず少し焦りましたがすぐに原因も特定でき一件落着。
一番怖かったデータ移行作業も無事完了。本番での動作確認をして最後にHerokuをメンテナンスモードにして作業終了!
準備期間を含めおよそ半年間かけて行ってきた移行作業が完了しました。
移行後
早速、移行の翌日バグの報告が入りましたw
とあるデータの表示が今までは日時の降順だったのに対し、移行後は昇順になっていました。(動作確認時は気づかなかった...)
おそらくDBが変わったことによる影響と断定し、Rails側でソートすることで事なきを得ました。
その後は特にバグの報告はなく、CPU, メモリ使用率も問題なく今も安定稼働しています。
まとめ
AWSに移行したことにより、セキュリティ面を強化できましたしHerokuの制限を受けなくなり、他のAWSサービスや今後AWSへ移行する他のプロダクトとの連携もしやすくなったと思います
それと実は今回、初めてTerrraformを触ってAWS環境のほとんどをTerraformで作りました。
キャッチアップに少し時間がかかった部分もありますがとても良い経験を積めたと感じています。
まだまだ知らないことばかりなので、今後も色々なAWSのサービスやインフラ技術にキャッチアップしていきたいと思います。
オンプレを全く知りませんが、クラウドインフラ便利で触ってて楽しいですね!それではまた〜!
CookieのSameSite属性とSecure属性について
初めまして。株式会社PRVENT開発部、バックエンドチームの横川です。
現在入社2年目で、普段はGoやRubyを書いて仕事してます。
今回はCookieのSameSite属性とSecure属性について紹介したいと思います。
なぜ書こうと思ったか
現在、『Mymonitor』という弊社のスタッフと取引先が利用するプロダクトのリプレースを進めており、Cookie初心者の自分がCookieを使ったログイン管理を実装しました。
そこで直面したエラーのおかげでCookieについて調べ上げCookieを完全に理解したので、今回直面したエラーの原因でもあるSameSite属性とSecure属性の挙動について記事にすることにしました。
そもそも Cookieとは
ブラウザで何かのサイトを閲覧した際にそのサイトのサーバーが発行してブラウザへ送信, 保存するテキスト情報です。
そのテキスト情報は、次またそのサイトへアクセスした際に毎回自動でブラウザからサーバーへ送信されるようになっていて使い方は様々です。
具体的にはサーバー側からのレスポンスにSet-Cookieヘッダを付与することでブラウザにセットされます。
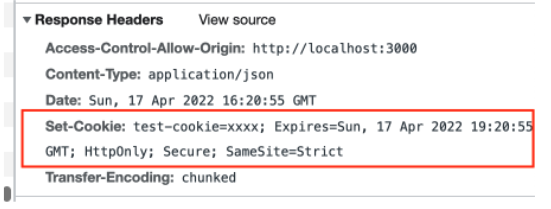
ログアウトできない...
MymonitorはフロントエンドにNext.js, バックエンドにGoを採用しており分業体制で開発を進めています。
ある程度機能を作ったところで一旦AWSに載せてみることになったのですが、ローカル環境では問題なく動作していたログアウトがAWS環境だと動作しませんでした...
ただこのエラーを機に、Cookieについて調べ上げることとなります。
原因はSamesite属性とSecure属性
確認したところ、サーバー側で発行するログアウト時のCookieにSameSite属性とSecure属性を設定していなかったのが原因でした。
ちなみにログイン、ログアウト時の意図した挙動は以下です。
| 機能 | 詳細 |
|---|---|
| ログイン | 有効期限が3時間のCookieをサーバー側で発行しブラウザに保存する |
| ログアウト | 有効期限が切れたCookieをサーバー側で発行しブラウザに保存する |
| 認証 | リクエストの度にサーバー側でCookieを受け取りその値でアクセスコントロール |
有効期限が切れたCookieは、ブラウザに保存すると同時に消えることでログアウトを実現できます。
今回は消えるはずのCookieがログアウト後も残ってしまっていました。
その時のソースコード
// ログイン時のcookie cookie := http.Cookie{Name: name, Value: token, Expires: time.Now().Add(3 * time.Hour), HttpOnly: true, Secure: true, SameSite: http.SameSiteNoneMode} // ログアウト時のcookie cookie := http.Cookie{Name: name, Value: "", HttpOnly: true, MaxAge: -1}
すっぽり抜けてます。
ただ、この時Cookie初心者だった自分は SameSite属性 == クロスオリジンでCookieやりとりするときはNoneにしないといけないと誤った理解をしてしまっていました。
なのでローカルもAWS環境もクロスオリジンだったのに、なぜAWS環境だけログアウトできないのかこの時点ではまだわかっていません 笑
SameSite属性とSecure属性ってなんぞや
Cookieには発行する際にいくつか属性を付与できます。(以下一部抜粋
| 名前 | 解説 |
|---|---|
| Name | Cookieの名前 |
| Value | Cookieの値 |
| Expires | 有効期限(日) |
| MaxAge | 期限までの秒数 |
| HttpOnly | 付与するとJavaScriptからアクセスできなくなる |
| Secure | 付与すると httpsの通信でのみ送信する |
| SameSite | cross-site(クロスサイト)の通信でもCookie送信します?の 設定 |
解説にも書きましたが、今回取り上げるSecure属性は付与することによりそのCookieはhttps通信でなければ、ブラウザ, サーバ間で送信されなくなります。
SameSite属性は、このあと書きますが設定によってブラウザ, サーバー間のCookie送信をクロスサイトでも行うかの設定ができます。
SameSite属性に設定できる値
| 名前 | 効果 | 詳細 |
|---|---|---|
| Strict | 同一サイトでのみCookie送信 | セキュリティ強 |
| Lax | クロスサイトの場合HTTPメソッドがGETなど特定の条件下でのみCookie送信 | Chromeでは未指定だとこれになる。 セキュリティ中 |
| None | クロスサイト、同一サイト関係なく送信する | Secure属性が必須。セキュリティ弱 |
今回だと、フロント側のURLとサーバー側のURLの関係がクロスサイトかどうかが重要で自分はここを理解してませんでした。そして当初の理解のSameSite属性 == クロスオリジンでCookieやりとりするときはNoneにしないといけない ではなく SameSite属性 == クロスサイトでCookieやりとりするときはNoneにしないといけない と知りました。(そもそも属性の名前が SameSite(同一サイト)になってるやろ!って話ですね)
ちなみにcross-site(クロスサイト)かsame-site(同一サイト)かの定義は以下の通りです。

引用:https://zenn.dev/agektmr/articles/f8dcd345a88c97
トップレベルドメイン+セカンドレベルドメインの組み合わせが違うかどうかのようです。
今回の状況
| 環境 | フロント | バック | 詳細 |
|---|---|---|---|
| ローカル | http://localhost:3000 | http://localhost:8000 | same-site なのでCookie送信できる |
| AWS | https://hogehoge.amplifyapp.com/ | https://fugafuga.com/ | cross-site & SameSite属性が 未指定(Lax) & リクエストメソッドがPOST なのでCookie送信できない |
ローカル環境ではポート番号が違うだけで同一サイトになるため、SameSite属性が未指定(Lax)でも問題なくCookieを送信できる。
AWS環境では、まだ載せたばかりだったこともありドメインも違うのでクロスサイトになり、SameSite属性が 未指定(Lax)のログアウト処理だけうまく動かなかったわけです。
http通信のローカル環境でなぜログインできてたのか
SameSite属性は完全に理解したところですが、もう一つ疑問が。
そう。Secure属性です。Secure属性は付与すると、httpsでしかCookie送信しないはず...
↓もう一度その時のソースコード
// ログイン時のcookie cookie := http.Cookie{Name: name, Value: token, Expires: time.Now().Add(3 * time.Hour), HttpOnly: true, Secure: true, SameSite: http.SameSiteNoneMode} // ローカル環境のhttp通信では送信しないはず... // ログアウト時のcookie cookie := http.Cookie{Name: name, Value: "", HttpOnly: true, MaxAge: -1}
localhost は例外
ブラウザによっては localhost だと httpsの要件が無視されるとのことでした。
※自分はChromeを使ってます

引用:https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Set-Cookie#sect4
開発者のこと考えてってことだよね。ありがてぇ... 笑
まとめ
- ローカル環境では同じlocalhostでsame-siteのため SameSite属性が未指定(Lax)でもCookie送信できた
- cross-siteでCookie 送信する場合は、SameSite属性をNone、Secure属性をtrueにするべし
- Secure属性は localhost だと 無視される(ブラウザによる)
最後に
なんだかんだで今では、AWS環境でフロント側とサーバー側で同じドメインを使い、SameSite属性をStrictにして動かしています。
有名なサーバー攻撃手法のXSSやCSRFの対策として、SameSite属性やHttpOnly属性の設定は必須です!!正しい知識で安全にCookie使っていきましょー!!
開発部内でのコミュニケーション頻度の向上のためGatherを導入してみた
PREVENT開発部、フロントエンドチームの高田(@tockii_ )です。本日は弊チームでオンラインコミュニケーション改善のため実施している施策についてご紹介します。
書いていること
- Gatherを使い始めた背景
- Gatherの利点
- Gatherを使ってからのメンバーの所感
- 今後の課題
書いてないこと
- Gatherの使用方法
- 別の機会で記事にできれば良いなと思っています。
はじめに
弊社では現在自由出社制度が実施されており、社員の任意でリモートワークか出社かを選択することができます。その中で開発部は常にほぼ全員がリモートワークで業務をしておりますが、現状業務に大きな混乱はなく、滞りなく円滑に進んでいるようにはなっています。
ただやはりリモートワークの弊害として、雑談などといった気軽なコミュニケーションがどうしても減ってしまっているというところがありました。無理に話をする必要がないのはもちろんですが、しかし全体的にも気軽に雑談とかできる方が嬉しいよねという共通の認識はあったところでした。
ただ、こちらを解決するためのツールや施策がなかなかうまくいかず(Discordなども使ってみましたがあまり浸透しなかった)どうしたものかと頭を悩ませていました。
そのとき、弊社エンジニアの1人が Gather っていう 面白いオンラインコミュニケーションツールがあるよということで、開発部内で試しに使ってみることにしました。
結果としては、部内でGatherを使うという文化が浸透し、コミュニケーションの幅が増えたというところになりました。
Gatherとは?
アプリ内に複数のユーザーが自由に出入りすることができる空間を作成し、その中でユーザー同士が通話やチャットなどといったコミュニケーションをとることができるというWebアプリです。
他のコミュニケーションツールと何が違うのか?
MeetsやDiscordなど、世の中にはさまざまなツールがありますが、そのようなツールとは違う部分がいくつかあり、それが要因として部内に浸透したのかなと思っています。
スペースという存在・遊び心
上記ツールと一番の違いはこれに尽きるかなと思います。標準的な通話ツールは、ただ特定の通話部屋に入り、通話やチャットができるという機能しかありません。
しかしGatherはまるで一昔前の2DRPGのような空間に入り、その中で必要であれば会話をしたり、集中して作業したい時は離れた場所で仕事をするというようなことができます。これは仕事というよりは遊びという概念がかなり多く含まれているなと感じ、実際にそのような点をメンバーも感じとり、楽しんで使ってもらっているようです。
若干のリアルさ
上記で説明しましたが、Gatherではスペースという空間で移動をする必要があります。単なるコミュニケーションツールとしては非効率的な動作ですが、こういった操作を行うことでアバターと自身がシンクロしてそこに人がいるという感覚になり、出社をしている感じだったり、気軽なコミュニケーションの取りやすさがあるのかなと思います。
弊社のGatherの風景です、最近はSnapCameraでよくわからないフィルターを使うのが流行っています
Gatherをどのように使っているか?
開発部では主にGatherをバーチャルオフィスのような感覚で使っています。
以下が2022年3月現在のPREVENT開発部スペースの全景です。複数のエリアがありますが、大きく分けて3つの用途を持って使用しています。現在はこの3用途だけで問題なく運用されている状態です。
番号を割り振ったので順番に説明していきます、番号外の箇所に関してはフリースペース(特に何も決めていない)です。
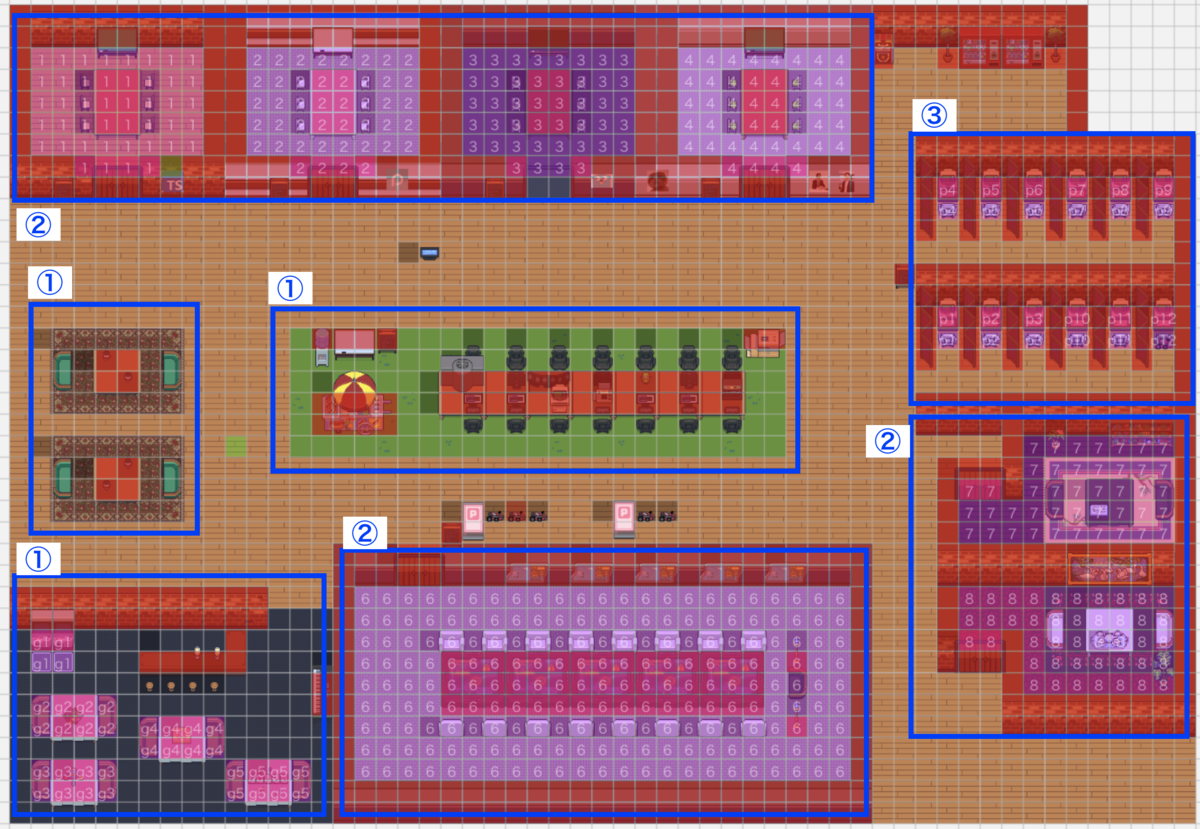
①オープンスペース
ここでは近くにいる人とであれば誰とでも会話できるようになっています。
用途としてはいつ話かけてもいいよという状態のメンバーが使っているイメージです。
メインは中央スペースですが、たまに左にいるメンバーもいます。
左下はゲームセンターをイメージして作ったんですが特に使っている人はいないですね(泣
②会議スペース
枠の中でマスごとに番号が割り振られていますが、会議スペースはこの番号内のスペースに入っている方のみと会話ができるようになっています。(左上の[1]の場合、[1]の中にいる人としか会話できない、会話は[1]の外には聞こえない)
用途はその名の通り会議で使っています。部屋も大中小と分けており、どの人数でも対応できるようになっています。
最近開発部内での会議に関してはほぼ全てGatherでするようになっていますが(今まではMeetsを使っていた)今のところ大きな問題は出ていません。
Gather自体にバーチャル背景機能がないのがネックですが、SnapCameraという外部アプリを使うことでその点は解決できています。
③黙々スペース
こちらは会議スペースの機能の応用で、移動できる箇所で会話できるマスを1マスにすることで基本的には誰とも会話ができない&会話が聞こえないようになっています。(Gatherの特定の機能を使うことで会話はできますが、意図的に行う必要がある)
用途としては作業に集中したい時やGather以外で会議がある場合など、話しかけてほしくない状態のメンバーが使用するイメージです。
Gatherを使って1ヶ月後のアンケート
2月の初めからGatherを使い始めましたが、3月に簡単なアンケートを実施しました。
目的としては、メンバーがどういう風にGatherを使っているか、Gatherを今後も使い続けていけそうかを判断してみたかったからです。個人的にこのようなアンケートをとるのは初めてなので、実際に有効なアンケートなのかは微妙かもしれません。この辺りアドバイスなどありましたらぜひ教えていただきたいです。
各アンケートの後には、個人的な感想を少し述べています。
1.Gatherはコミュニケーションツールとして使いやすいですか?
(①を使いにくいとし、⑤を使いやすいとしています)
ほぼ全ての人が使いやすいという回答をしています。コミュニケーションを取る、というだけだったら余計な工程があったりしますが(スペース内で移動しないといけないなど)おおむねその辺りは許容されているのかな?といったところです
2.Gatherはツールとして面白いですか?
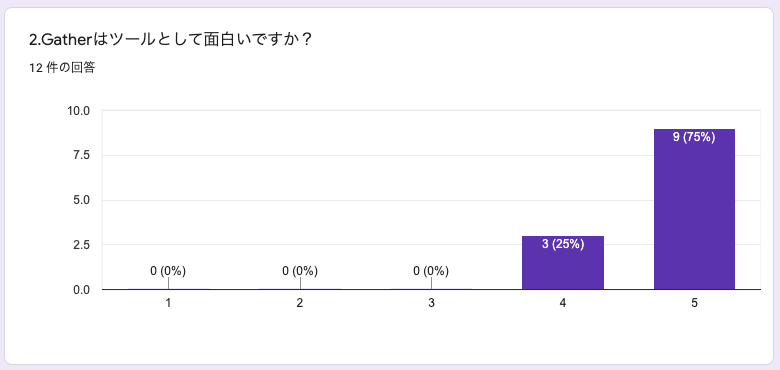
(①を面白くないとし、⑤を面白いとしています)
全員が面白いと回答しています。やはりゲーム的な側面もあり、コミュニケーションツールとは思えないような点が面白いのかなと感じます。
3.ログイン頻度は?
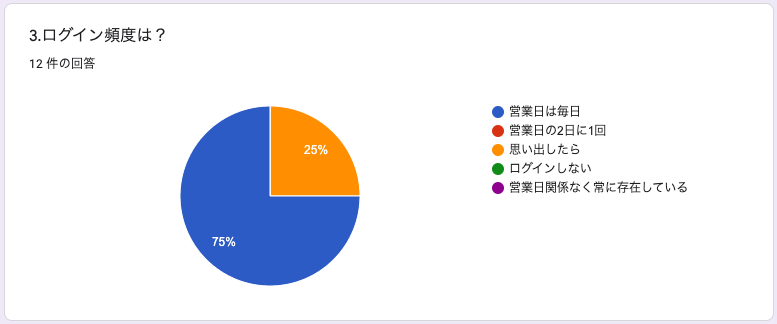
ほぼ全員が毎日ログインしてくれていると回答しています。
毎日ログインしている身としての感覚としては、間違ってはいないかなと思います。
3-1. (3)で「営業日は毎日」「営業日の2日に1回」「営業日関係なく」に回答した方に質問です。Gatherにログインし続けている理由はなんでしょうか?
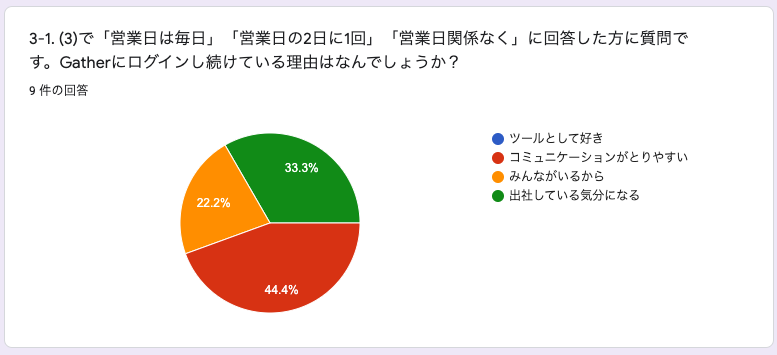
色々な回答がありますが、やはりコミュニケーションが取りやすいと意見が多いですね。出社している気分になる、というのも実際にその通りだなと思います。
リモートワークをしているとどうしても仕事感が希薄になってきますが、Gatherを使ってからはGatherにいる→仕事をしているという感覚になっています。
3-2. (3)で「営業日は毎日」「営業日の2日に1回」「営業日関係なく」に回答した方に質問です。今後もGatherを使い続けようと思いますか?
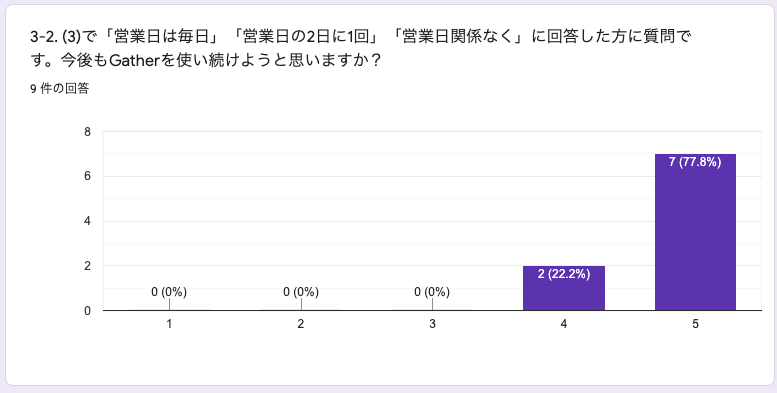
(①を思わないとし、⑤を思うとしています)
毎日ログインしている方全員が使い続けると回答しています。施策を実施した身としては嬉しい思いです。
3-4. (3)で「思い出したら」「ログインしない」に回答した方に質問です。Gatherの使用をしないのはなぜでしょうか?
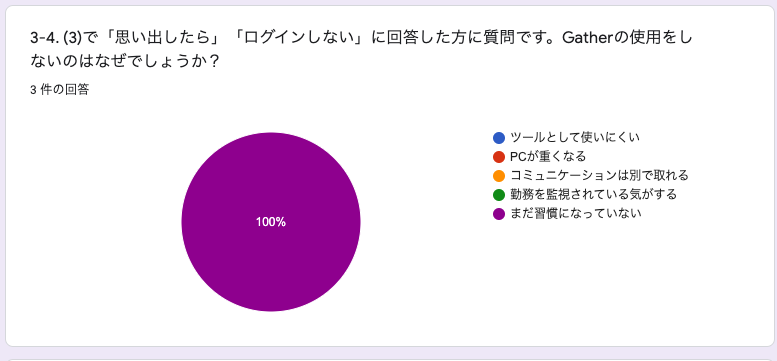
先のログイン頻度で「思い出したら」と回答した人は、基本的に習慣になっていないというのが大きな理由になっているとのことです。
習慣化するのは難しいですが、最近は部内の会議をGatherにシフトしているなどしているので、そこからGatherに入室するという習慣をつけていけたらという気持ちです。
3-5. (3)で「思い出したら」「ログインしない」に回答した方に質問です。Gatherを使いたいと思うにはどのようなことがあればいいと思いますか?(設定やイベントなど、なんでも良いです!)
開発部全体の朝会みたいなのやりたい
出社したらGatherっていう習慣をつける。打刻申請とリンク。
打刻申請とリンクというのは面白いなと思いました。ただリンクする場合は全社的な施策がちょっと絡んでくるので、思い出せないということであれば開発部内で定期のslackメッセージなどを流すなどをしたらいいのかなとも思いました。
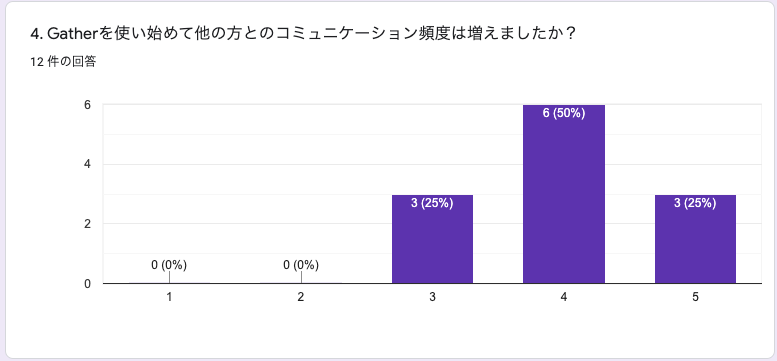
4. Gatherを使い始めて他の方とのコミュニケーション頻度は増えましたか?
(①を減ったとし、⑤を増えたとしています)
ほぼ全員が増えたとの回答をしています。③は「変わらない」という回答なのかなと思っていて、これは後述する黙々スペースに常にいる人などがそうなっていたりするのかなと思います。ただ、無理にコミュニケーションを取る必要はないという考えなので、このあたりはこんなもんかなといったところです。
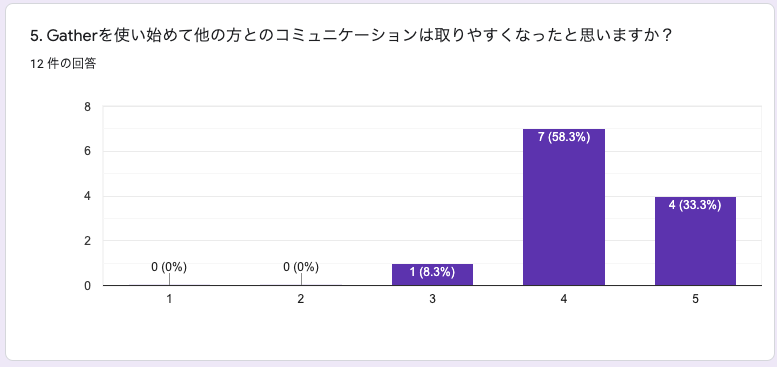
5. Gatherを使い始めて他の方とのコミュニケーションは取りやすくなったと思いますか?
(①を思わないとし、⑤を思ったとしています)
ここでは全員が取りやすくなったという回答をしています(もしかしたら③の人は変わらない、という回答なのかもしれませんが、、、)4の回答では変わらないと思った方も取りやすくはなっているという認識のようです。
6. Gatherでは主にどのスペースにいますか?
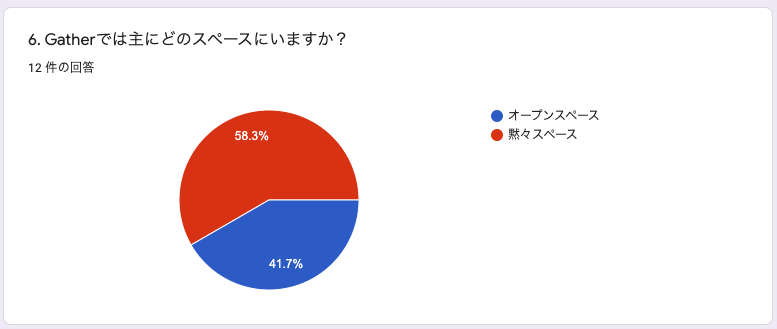
黙々スペースが多数派ですね。
6-1. (6)で「オープンスペース」と回答した方に質問です。主にオープンスペースにいる理由はなんでしょうか?
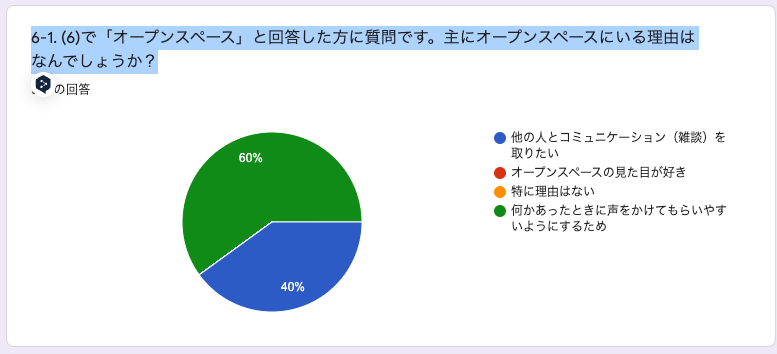
オープンスペースは雑談などのコミュニケーションをとりやすくしたいという考えで設置してみたのですが、何かあった際のコミュニケーションのとりやすさを解答としている人が多くて少し予想外でした。ただ確かにトラブルや相談があった際にオープンスペースにいると会話はしやすくなりそうなのでこの解答には納得です。
6-2. (6) で「黙々スペース」と回答した方に質問です。主に黙々スペースにいる理由はなんでしょうか?
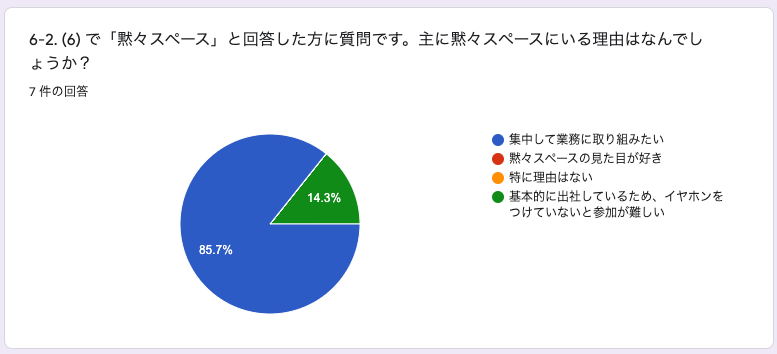
ほぼ全員が集中して業務に取り組みたいといった回答で、予想通りの使用方法かなと感じました。
ただ出社をしている場合は確かにGatherを使うのが少し難しいかなというところの回答もありました。ここは今後の課題かなと思っています。
Gatherのいいところを教えてください!(先に回答したことと被っても大丈夫です
一部抜粋して掲載しています
コミュニケーションが取りやすい
雑に話しかけれるビジュアル的に「みんな集まってる」感があって心理的安全性の維持につながっていそう
話しかけてよいか悪いかのところはDiscordより分かりやすく感じた。
キャラとか個性がでて面白いなとか、ゲーム感覚があって普段の仕事とは別の面白さがあって良いと思います。
Gatherの悪いところを教えてください!(先に回答したことと被っても大丈夫です
一部抜粋して掲載しています
まだバグがあるところ
急に声をかけられた時にマイクをすぐに on にするのが難しい
十字キーでの移動がめんどくさく感じる ゲーム感あって好きだけど業務中に使うツールとしては非効率
現在のステータスがわかりにくく、切り替えにくい。お昼とか、gather以外の会議とかが簡単に切り替えられるとよい。現状は、gather外にいるときは、quiteモードにしている。
その他、Gatherに関する要望等あればこちらに記入してください!
一部抜粋して掲載しています
他部門も入れたい(まぁ無理か。)
meetsでやるのか、gatherでやるのか曖昧な状況を整備した方が良さそう
今後の課題
最近の課題であった「リモートワークでのコミュニケーションの取りにくさ」については多少の改善はできたかなと感じています。
ただまだまだGather自体不具合も多いので、とても使いやすい、という状況になるにはもう少しかかりそうです。この辺りはGatherチームに期待をするしかありませんね。
コミュニケーションの取りやすさの改善などはまだ色々考えれるところがありそうなので、直近の目標としては開発部全員が常にログインしている状況にし、誰とでも常にコミュニケーションが取れるような環境づくりをしていけたら良いなと思います。
終わりに
最近のPREVENT開発部ではコミュニケーションをどのように解決しているか?について書かせていただきました。
コロナ禍でなかなか外出や出社が難しい現状ですが、Gatherなどのツールを活用し、リモート下でも気負いなくオンラインコミュニケーションを取れるよう、今後も改善していきます。
Gather自体は私たちのような会社の部内で使う以外にも勉強会やイベントなどでも使えそうなツールなので、よかったら試しに触ってみてはいかがでしょうか。
データサイエンスチームで、はじめてのインターンシップを受け入れました
はじめに
株式会社PREVENTのデータサイエンス(DS)チームの戸田です。今回はDSチームで受け入れたインターンシップの活動を報告します。
ツイッターのDM経由で連絡をいただいた東京大学 公共健康医学専攻の瀧澤さんは、9月6~24日の実稼働日が13日と非常に短い期間のなかで、こちらの用意した以下の課題を実施しました。
有給のインターンシップという形でしたので、業務タスク(1, 2)をお願いしつつも何か学びをご提供できればと思い、先行文献の追従解析(3)を追加しました。盛りだくさんで課題が多過ぎたかと思いましたが見事にこなしていただきました。
リモートでのインターン受け入れ
9月30日まで東京では緊急事態宣言が出ていました。そのため、インターン開始の9月6~10日までホテルにてリモートで作業していただき、その後、マスク着用・入室時の手指のアルコール消毒など弊社が定める感染予防対策を徹底した上で、9月13日よりオフィスでインターンを開始しました。この辺りは瀧澤さんに柔軟に対応していただきました。
リモートのみでのインターン受け入れはなかなか難しいなという印象でしたので、今回のように前半リモート、後半は出社で今後のインターンを実施する可能性があります。
課題の成果報告
1. Myscopeのデータクレンジング
健康診断データおよびレセプトデータは、クライアントの保険者様からお預かりし、弊社内のレポート作成コードに合うように整形されます。Myscopeでは、機械的にクレンジング作業を行うためのアルゴリズムを組んでいますが、人によるチェックとコードの変更が必要な箇所があります。お預かりした生データから指定したフォーマットに変換する作業を期間中に2件行なってもらいました。
2. データセット仕様書や業務についての仕様書などのドキュメント整理
弊社内で保有しているデータについては、ER図が存在しているものの定義書やプロファイルがまだ不十分です。そこで、ER図と指定した参考資料を用いて定義書の作成してもらいました。エディタの指定はしませんでしたが、フォーマットはMarkdownに統一しました。
(レセプトDBの定義ドキュメントの一部)

3. 先行文献の追従解析
今回参考にさせていただいた論文は2021年に公開されましたPhysician visits and medication prescriptions for major chronic diseases during the COVID-19 pandemic in Japan: retrospective cohort study(I.Osawa, et al, BMI Open, 2021)です。COVID19流行による緊急事態宣言前後での慢性疾患に対する医師の診察と処方行為についての日本の観察研究です。proportion of days covered:PDC(処方日数を対象期間の日数で除した割合)という指標を抜き出すことや時系列でデータを取り扱うことがレセプトの取り扱いを実践してもらう良い題材となると考え、インターン課題として選択しました。
結果のサマリー
弊社内匿名加工済みデータセット(225,237件、2017.01~2020.12)を用いて、論文にある指標を計測しました。 詳細をみるとまだ考察しきれていない部分はありますが、1回目および2回目の緊急事態宣言前後で受診回数が減少していることがわかります(スライド8枚目)。参考にした先行文献と類似した結果が得られました。
インターンシップを参加した感想
インターンシップに参加した瀧澤さんより感想をいただきました。
今回インターンシップをさせていただいた瀧澤です。
私はデータサイエンスの学習はしておりましたが、レセプトデータなどの生データに触れる機会はなく、「データサイエンス職に興味はあるが、実際の業務は自分に合っているのだろうか?」という不安がありました。今回のインターンシップで 、データ分析の8割を占めるといわれるクレンジング業務や実際のレセプトデータに触れることで、PREVENTのデータサイエンス職の業務内容がイメージしやすくなりました。学習したことが実際のデータではスムーズにいかないことも体験でき、とても充実し学びの多い経験となりました。 これまでレセプトデータとの関わりがなかったのですが、ドキュメント作成と論文追従を経て、受診から請求までのデータの流れをイメージできるようになりました。
PREVENTのインターンシップを経験し、よりデータ分析に関わりたい気持ちが強くなりました。この経験は自分にとって資産だと感じています。受け入れてくださったPREVENTの皆様、本当にありがとうございました!
まとめ
DSチームでのインターンの受け入れは初めてのことでした。非常に優秀な方でしたのでなんとか形にしていただき、さらには今後インターンシップの方針もだいたい定めることができました。この場を借りて瀧澤さんにはお礼を申し上げます。
今回の経験を踏まえて、インターンの方には基本的に
- 弊社解析業務のMyscopeのデータクレンジング
- データセット仕様書や業務についての仕様書などのドキュメント整理
- 社内匿名加工済みデータを用いた先行文献の追従解析
を実施していただく予定です(※ もちろん期間に応じて課題設定は行います)。ヘルスケアスタートアップが扱う生データに触れていただく機会とデータの活用方法について体験いただければと考えています。ただ、ある程度のドメイン知識が必要ですので、前半はドキュメント作成などのタスクで特有なデータ構造について学んでもらい、後半にはガンガンコードを書いてデータ分析を進めるという流れが良いかなと考えています。
DSチームのリソース的に多くの受け入れは困難ですが、ご興味のある方が是非ご連絡をいただければと思います。ヘルスケアベンチャーでDSチームが何しているの?実際にどんな業務があるの?今後の展望ってあるの?など、この分野でDSを目指したい方は是非一度コンタクトをとってみてください。
*1:Myscopeの詳しい説明についてはhttps://prevent.co.jp/service/myscope/