より少ないクリックでモデルが作れるようになりました!
今回はSkyFoxでのモデル作成手順のちょっとした導線変更のご案内です。
これまでのモデル作成手順
これまでのSkyFoxでのモデル作成手順は
- Step1:学習データの選択
- Step2:学習データのサマリ
- Step3:分析のオプション
- Step4:モデルの作成
という流れで画面が遷移していました。
最後のStep4:モデルの作成の画面でようやくモデル作成を実行するボタンが押せるようになっていました。
変更後のモデル作成手順
この実行ボタンをStep2:学習データのサマリの画面にも設置しました。
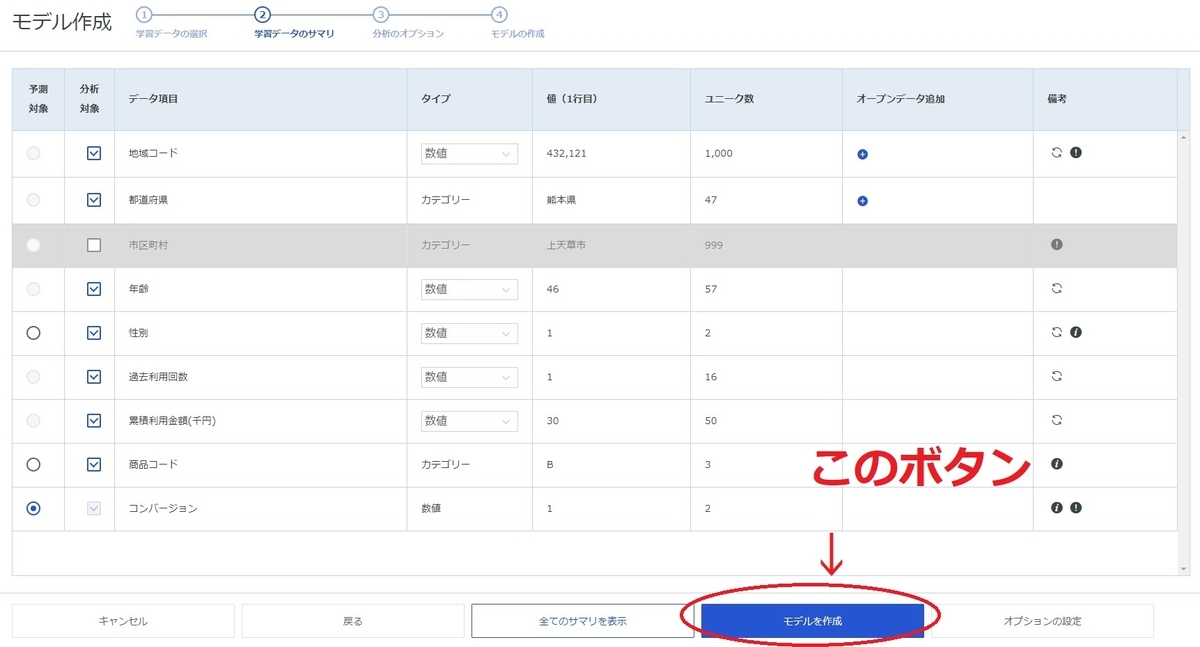
これによりStep3とStep4を飛ばしてモデルを作成することができるようになりました。
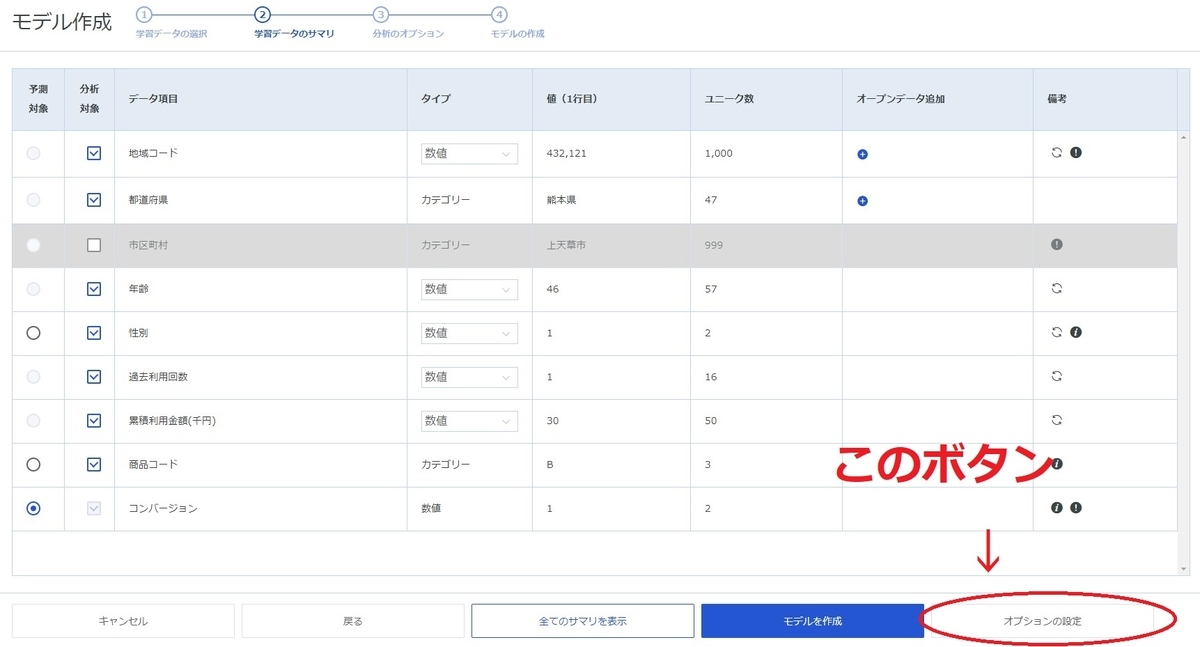
細かいパラメータやアルゴリズムの設定はすべてSkyFoxの自動選択にまかせて、サクッとモデルを作りたいといった場面においては非常に有効です。
もちろん細かい設定をしたい場合は下記のオプション設定のボタンから従来の導線がそのまま使えます。
まとめ
いかがでしたでしょうか?
モデル作成はトライアンドエラーの繰り返しです。特徴量をあえて減らしてみたりしながらどう変化するのかを試すことはよくあります。
そういった場面で何度もクリックするのは手間なので、今回のボタンの追加は役立つのではと思います。
※今回の変更は有償版のSkyFoxのみになります。トライアル版SkyFoxでは従来通りです。
SkyFox活用事例紹介~審査スコア構築
これからいくつかに分けてSkyFoxの活用事例をご紹介していきたいと思います。
様々なテーマでご採用頂いておりますが、
今回は、金融機関での審査業務におけるAI構築事例をご紹介します。
背景
申込顧客に対する審査業務は、担当者が一人ひとり目検で審査を行っており、業務負荷が大きく、多くのリソースを費やしていることが課題となっていました。
また、こういった審査業務は、担当者の経験やスキルに左右される部分も多く、担当者の手間と時間を要する一つの要因でもあります。
業務量の70%を削減
SkyFoxではこうした審査業務の課題に対して、お客さま独自の審査スコアを構築し、
業務の自動化を進めることで、約70%の業務量削減に貢献しました。
具体的には、蓄積された顧客データやSkyFoxが持っているオープンデータを使って
審査スコアを構築し、担当者は、申込顧客のスコア結果別に対応を行うといった取り組みです。
これにより、業務効率化だけでなく、審査時間の短縮による顧客満足度の向上も期待出来ます。
さらに、審査AI構築時には、審査担当者のノウハウをモデルに反映させることで、安定した審査品質のもと業務量削減を実現させることが出来ました。
短期間での導入を実現
SkyFoxでは、簡単なマウス操作のみによるAI構築と
迅速なレスポンスにより何回も変数を入れ替えてAIモデルを作り変える事が出来るので、顧客の簡易分析から最終モデルの構築まで3ヶ月で可能にしました。
また、下記の様に影響度を算出し、AIモデルの予測根拠を可視化することで、現場担当者に納得して頂けた点も短期間で導入を実現できた理由の一つでもあります。


まとめ
SkyFoxの活用により、短期間での審査スコア構築と業務量削減を実現させることが出来ました。
その他、SkyFoxでは、数値データのみならずテキストや画像を使用した分析も可能です。
それらを活用したさらなる業務効率化や収益改善に貢献していきたいと思います。
金融業界における、事例の一つとして審査業務のAI化について簡単にご紹介させて頂きましたが、その他、BTTC(BestTimeToCall)モデルやお客様の声分類モデルなど
様々なテーマでモデルの構築支援を行っております。
どういった分析が出来るか、データはあるが活用方法が分からない等の
ご相談からご支援させて頂いておりますので、お気軽にご相談ください。
SkyFoxのデータ変換の種類とパッケージ選択、およびカスタマイズ方法について
今回はSkyFoxのデータ変換の種類とパッケージ選択について説明します。
目次
データ変換の種類について
モデル開発の前に、一つ一つのデータ項目を扱いやすいように、また特徴がでやすいように以下の加工を施します。
データ項目数による選択
全データの値が同じである場合や、郵便番号などデータの種類が多すぎる場合、モデル作成に悪影響を及ぼす場合がありますので、一般に、そのようなデータ項目は使用しません。 数値データには作用しませんので、常に利用することを推奨します。
欠損値の補完
主に数値データにおいて、データ内に欠損が含まれると計算ができないため、それを補完します。 現在は、中央値が選択されます。
追加特徴量名
(元項目名)__EMPTY
値の対数化
数値データにおいて値の幅が広く、小さい方または大きい方にデータの偏りがあるような場合は、値を対数化することで、偏りをなくすことができます。
日付関連情報の追加
年月日などの日付情報から曜日や祝日などのフラグを追加します。 日付データ以外には作用しません。
追加特徴量名
①(元項目名)_DOW:データの曜日を示す項目です
②(元項目名)_WEEKEND:土日であるかをフラグで示す項目です
③(元項目名)_HOLIDAY:祝日であるかをフラグで示す項目です
④(元項目名)_WEEKWND_HOLIDAY:土日もしくは祝日であるかをフラグで示す項目です
値の発生頻度の追加
コード値などカテゴリで表されるデータにおいて、各値の出現頻度をデータ項目として追加します。数値データには作用しません。特徴が追加されるため、精度向上が期待できます。
追加特徴量名
①(元項目名)_FREQUENCY:各値の出現頻度を算出した項目です
②(元項目名)_ROW_FREQUENCY:発生頻度が低い値をフラグで示す項目です
カテゴリ項目のダミー変数化
コード値などカテゴリで表されるデータは、そのままでは多くの機械学習アルゴリズムで使用できません。そこで、ダミー変数化と呼ばれる処理で数値に変換します。
数値データには作用しません。カテゴリ項目の有無によらず、常に利用することを推奨します。
追加特徴量名
(元項目名)__男性,(元項目名) __女性,(元項目名) __不明、…
:元の値を示すフラグ値のため、値のユニーク数だけ新たに項目が作成されます
値の標準化
データ項目による数値の大小に差が大きい場合、数値の大きいデータ項目の影響が強く出過ぎてしまうため、それを防ぐ目的で利用します。一般的に線形モデルでは必要な処理です。
追加特徴量名
(元項目名)__ABS_Z_SCORE:平均値からの外れ具合を示します
外れ値の補正
主に数値データにおいて、データ内に大きすぎる値など極端なデータ(外れ値)が含まれている場合に、全体の分布に合わせて数値を整えます。
データ項目の影響度による選択
予測対象に対してデータ項目の影響が弱すぎる場合、モデル作成に使用しない方がモデルが安定します。逆に、影響度が強すぎる場合は”答え”の可能性があるため、やはり使用しない方が良いです。
異常値スコアの追加
不正検知などに使用されるIsolationForestと呼ばれる手法を用いて、データの異常度をスコア化して、データ項目として追加します。特徴が追加されるため、精度向上が期待できます。
追加特徴量名
①異常値スコア:データの異常度をスコア化した値です
②異常値判定:異常値として判定されたかのフラグ値です
主成分変換
データを、主成分と呼ばれる統計的に意味のあるデータ項目に変換し、新しいデータ項目として追加します。主成分の上位を追加することで、特徴が表れやすくなるため、精度向上が期待されます。
追加特徴量名
主成分1、主成分2、… :各主成分の値です
※データによって作成される特徴量の数が異なります
独立成分変換
データを、統計的に独立なデータ項目に変換し、新しいデータ項目として追加します。元の数値より少ない数を指定することで、特徴が表れやすくなるため、精度向上が期待されます。
追加特徴量
独立成分1、独立成分2、… :各独立成分の値です
※データによって作成される特徴量の数が異なります
クラスタ変換
データを統計的に似ているグループ(クラスタ)に分割します。分類されたクラスタを元のデータ項目に加えることでモデルの性能向上が期待されます。
追加特徴量
:データがどのクラスターに所属するかを示すフラグ値です
:各クラスターの中心からの距離を示す項目です
※データによって作成される特徴量の数が異なります
合成特徴量の追加
遺伝的プログラミングと呼ばれる手法を用いて作成した合成特徴量を、新しいデータ項目として追加します。計算量が多いため処理に時間がはかかりますが、特徴が適切に表現されることも多く精度向上が期待されます。
追加特徴量名
合成特徴量_1、合成特徴量_2、… ※
:自動で各項目同士の掛けわせなどを行うことにより生成された特徴量です。
※データによって作成される特徴量の数が異なります
データ項目の相関による選択
相関が高くほぼ同じと見なせるデータ項目が存在する場合、片方の値を取り除いた方がモデルが安定します。
データ変換の種類とパッケージ選択について
各データ変換は以下のように3つに分けた上で、3種類にパッケージ化することで利便性が向上しております。ユーザーは処理の内容がわからなくても目的に応じてパッケージを選択するだけです。
|
|
|||
|---|---|---|---|
| 1:最低限必要な処理。クイックに様子を見たい時などに選択します。 | |
|
|
| 2:通常のモデル開発にはしておいた方が良い処理。 | |
|
|
| 3:処理時間はかかるが精度の向上が期待できる処理 | |
|
|
データ変換の種類と合わせて整理すると以下のようになります。
|
|
|||
|---|---|---|---|
| データ項目数による選択 | |
|
|
| 欠損値の補完 | |
|
|
| 値の対数化 | |
|
|
| 日付関連情報の追加 | |
|
|
| 値の発生頻度の追加 | |
|
|
| カテゴリ項目のダミー変数化 | |
|
|
| 値の標準化 | |
|
|
| 外れ値の補正 | |
|
|
| データ項目の影響度による選択 | |
|
|
| 異常値スコアの追加 | |
||
| 主成分変換 | |
||
| 独立成分変換 | |
||
| クラスタ変換 | |
||
| 合成特徴量の追加 | |
||
| データ項目の相関による選択 | |
|
カスタマイズ方法について
また更に細かくデータ変換の種類を選択したりパラメータを調整することも可能です。
細かくデータ変換の種類を選択
例えばこのデータ変換だけはしたくないといった場合はスキップさせることが可能です。
まず「詳細設定」の「設定の変更」をクリックします。

次にスキップさせたい変換にマウスのカーソルを当て、右上のチェックを外します。

するとこのようにグレーアウトします。戻したい場合はチェックを再度入れるだけです。

パラメータの調整方法
まずは調整したい変換をクリックします。
すると以下の画面が開きます。

ここで細かいパラメータを設定することが可能です。
具体的なパラメータの説明は別の機会にさせて頂きます。
学習データと検証データの分割方法の新仕様について~CV(クロスバリデーション)
今回のテーマは学習用データと検証データの切り分けについてになります。
モデルを作成する際はデータを二つに分割し片方で学習しモデルを作成、そして作成したモデルを学習に使っていないもう一方のデータで検証します。
SkyFoxでは基本的にデータの75%を学習用データとし、25%を検証用データとしています。この比率を変更できるのか?というご質問をよくいただくのですがこちらは変更できません。どうしても変更したい場合は以下の記事をご参照下さい。
さて本日紹介させて頂くのはデータ件数が少ない場合の分割方法についてです。
旧仕様
分類モデルの場合データ件数が1,000件以上(回帰モデルなら2,000件以上)の場合は75%-25%で交叉検証を行います。1,000件未満の場合は100%使って学習し、同じ学習データをそのまま評価データとして使います。
本来学習データで評価するということはするべきではありませんが件数が少ないため学習データの数を優先させていました。そのため検証結果を見る時はご注意くださいとご案内していました。
新仕様
こちらが2019年9月のバージョンアップで次のように変わりました。
具体的にはクロスバリデーション(以下CV)に対応しました。これによりデータ件数が少ない場合でもある程度安定した結果が得られるようになります。
CVというのはわかりやすく言うとデータをデータA、B、C、Dの4つに切り分けます。これを以下のようにして4回モデルを作って検証します。
- ABCで学習、Dで検証
- ABDで学習、Cで検証
- ACDで学習、Bで検証
- BCDで学習、Aで検証
最後に検証データを足し合わせて最終的な検証結果として表示しています。モデル自体は4つできますが、最終的なモデルはこの4つ全部使用して4つの予測結果の平均をとるようにしています。
CVの分割数(データ数毎)
ではこのCVの分割数ですが具体的にどう決めているかというと以下のようにデータ件数に応じて決めています。
- 2,000件以下 : 8分割
- 10,000件以下: 4分割
- 50,000件以下: 2分割
- 50,000件超: ~ CVなし ※学習=75%、検証=25%で評価
※分割後の目的変数の正例数が極端に少なくならないように分割します。もし少なくなるなら分割数を減らす対応をします。
例えば2,000件(正例が200件、負例が1,800件 ※1)というデータがあったとします。この場合データは8分割されます。そして8つそれぞれの中に正例が25件ずつ入っていたとします。この場合は8分割のままになります。
これが2,000件(正例が120件、負例が1,880件)というデータの場合、8つそれぞれの中に正例が15件ずつしか入りません。この場合分割数を8→4に変更して処理されます。
ちなみにその際の閾値※2は以下の通りです。
- 二値分類の時は20件
- 多値分類の時は10件
分割された一つ一つのクラスに入る正例数は一致するとは限りません。ランダムに振り分けていますので多かったり少なかったりバラつきますが、どこかひとつのクラスででも、この閾値を下回れば分割数を少なくします。
これは、正例数の少なさによる評価のブレが出なくなるようにするためです。CVと併せることで、評価結果の妥当性を向上させる仕組みとなっています。
※1)正例とは予測したいデータで、例えば商品の購入確率を予測したい場合、「購入した」データを正例データと呼びます。負例はその逆で「購入してない」データを指します。
※2)回帰モデルの場合はこの閾値は設けず単純にデータ件数だけ見てます。
注意事項
- トライアルでは旧仕様のままです。
- 新仕様のアウトプットでも評価データの欄に「学習データと同一」となっており旧仕様と新使用の見分けがつきません。こちらは12月のバージョンアップで例えば「4分割CVで評価」のような表現で何をしたのかわかるように変更する予定です。少々お待ちください。

生存力スコア~AIがあなたの生存力をスコア化します~
セカンドサイト株式会社は、現代社会を生き抜く力を数値化した「生存力スコア」を本日一般公開いたしました。
生存力スコアはオープンデータを含むセカンドサイトが保有するデータとSXスコアの技術をベースに開発したAIスコアです。この時代、お金が全てでしょうか。お金が無くても気持ち次第で充実した人生を送ることが可能です。また、育った環境によって価値観も人それぞれです。
この社会で生き残るために何が必要なのか、そして、あなたの表面上の情報だけでは知り得ない、真の生き抜く力をAIで評価してみませんか。
ご利用は専用のウェブサイト上で9つの簡単な質問に回答するだけで、個人を特定する情報は一切必要ございません。どなたでも無料でご使用頂けますので、ご家族、ご友人とゲーム感覚でご利用ください。
生存力スコアのウェブサイト https://survivor.sx-score.sxi.co.jp

【お問い合わせ先】
セカンドサイト SXスコア担当
石橋・星野
Tel. 03-4405-9914