はじめに
本稿は、オープンソースの可観測性(Observability)プロジェクトである OpenTelemetry を取り上げた書籍「Learning Opentelemetry」の読書感想文です。従来の可観測性の課題であったデータの分断を解消し、トレース、メトリクス、ログなどの様々なテレメトリデータを統合的に扱うことができる OpenTelemetry は、可観測性の分野における革命的な存在と言えます。
過去10年間で、可観測性はニッチな分野から、クラウドネイティブの世界のあらゆる部分に影響を与える数十億ドル規模の産業へと発展しました。しかし、効果的な可観測性の鍵は、高品質のテレメトリデータにあります。OpenTelemetryは、このデータを提供し、次世代の可観測性ツールと実践を開始することを目的としたプロジェクトです。
本書の想定読者は、アプリケーション開発者、オープンソースのメンテナー、運用・インフラチーム、マネージャーやチームリーダーなど幅広く設定されています。現代の可観測性の原則から、OpenTelemetry の導入、運用、トラブルシューティングに至るまで、大規模な組織における可観測性の実現に必要な知識が網羅的に提供されているのが特徴です。私が業務で利用している技術スタックの実装の詳細については説明されていませんでしたが、全てを網羅することは文量の制約がある以上、不可能であることは理解しています。また、実際に導入する際には泥臭い部分が相応に出てくるのですが、本書ではそれらがなんとなく回避されているようにも感じられ、Opentelemetryが万能の願望機に見えてしまうかもしれません。この辺りについては、OpenTelemetry MeetupやOpenTelemetry Casual Talkなどで先駆者達とお話をすれば、徐々に理解が深まるのではないかと思います。
- はじめに
- Chapter 1. The State of Modern Observability
- Chapter 2. Why Use OpenTelemetry?
- Chapter 3. OpenTelemetry Overview
- Chapter 4. The OpenTelemetry Architecture
- Chapter 5. Instrumenting Applications
- Chapter 6. Instrumenting Libraries
- Chapter 7. Observing Infrastructure
- Chapter 8. Designing Telemetry Pipelines
- Chapter 9. Rolling Out Observability
- おわりに
- 参考資料
以前、OpenTelemetry に関する社内勉強会の資料を作成した際、プロジェクトの全体像を理解することの難しさを感じました。OpenTelemetry は野心的なプロジェクトであり、各コンポーネントの役割や相互の関係性を把握するのは容易ではありません。国内でもOpenTelemetryに関するカンファレンスや勉強会が数多く開催されていますが、どのイベントに参加し、どの資料を読めば効率的に知識を習得できるのか、判断に迷うこともあります。しかし、本書は OpenTelemetry の設計思想から実践的な活用方法まで、体系的かつ平易に解説されており、可観測性に関する理解を深めるための良きガイドになるはずです。
近年、マイクロサービスアーキテクチャの普及やクラウドネイティブの進展に伴い、システムの複雑性は増す一方です。そのような環境において、可観測性は安定したサービス運用を実現するための鍵となります。本書を通じて、OpenTelemetry を活用した可観測性の向上について学び、自身の開発・運用プラクティスに活かしていきたいと思います。
本書は、OpenTelemetryの重要性とその応用を探る実践的なガイドであり、可観測性の分野で必読の一冊と言えるでしょう。本書は、可観測性の世界でOpenTelemetryが中心的な役割を果たしていることを強調し、その価値と組織にもたらすメリットを第2章で解説します。続いて、OpenTelemetryのモデル、主要な可観測性シグナルの関連性、アプリケーションの計装方法、オープンソースライブラリやサービスの計装、ソフトウェアインフラストラクチャの観測オプション、可観測性パイプラインの構築、そして組織全体でのOpenTelemetryの展開戦略について詳細に説明します。各章は、トレース、メトリクス、ログなどの可観測性シグナルの理解を深め、高品質のテレメトリデータの確保、ライブラリの可観測性への取り組み、OpenTelemetry Collectorを用いたパイプライン構築、そして組織的なアプローチに至るまで、広範囲にわたる知識を提供します。
")
本書は、OpenTelemetryを活用した可観測性の向上に向けた実践的な知見を得るための優れたリソースです。具体的な実装の詳細については、他の情報源も参照しながら、自身の環境に合わせて工夫していく必要がありますが、本書が提供する知識と洞察は、その過程で大いに役立つことでしょう。OpenTelemetryは可観測性の分野で大きな可能性を秘めたプロジェクトであり、本書はその理解と活用に向けた道しるべとなる一冊です。また、小項目は本書からの引用ではなくオレオレ分類です。
本稿は同僚であり友人の俺ですにレビューしていただきました。改めて感謝申し上げます。
Chapter 1. The State of Modern Observability
本章を読んで、現代のソフトウェアシステムにおけるObservabilityの重要性と課題について理解を深めることができました。著者は、Observabilityの歴史を理解することが、現在のソフトウェアシステムの課題を解決するために不可欠であると主張しています。これは、冒頭の "History is not the past but a map of the past, drawn from a particular point of view, to be useful to the modern traveler:歴史とは過去ではなく、現代の旅行者に役立つように特定の視点から描かれた過去の地図である。" という言葉に端的に表されています。著者の主張を踏まえると、Observabilityの歴史を学ぶことは、現代のソフトウェアシステムの課題を解決するための重要な手がかりになるでしょう。私は壮大な物語が大好きなので、『サピエンス全史』なども好きなので紹介しておきます(なぜ?)。

国内では、OpenTelemetryのこれまでとこれからなどのセッションが参考になるかもしれません。OpenTelemetryは、オープンソースのObservabilityフレームワークであり、その発展の歴史とこれからの方向性を理解することは、現代のソフトウェアシステムにおけるObservabilityの課題を考える上で役立つと思われます。また、Observability Conferenceなどのカンファレンスでは、Observabilityに関する様々なセッションが開催されています。興味のあるセッションを幅広く視聴することで、Observabilityの現状と将来の可能性について、多角的な視点から学ぶことができるでしょう。
Observabilityの重要性と課題
本章では、まずObservabilityに関連する重要な用語の定義が述べられています。分散システム、リソース、トランザクション、テレメトリ、分析、Observabilityなど、これらの用語を正しく理解することは、Observabilityについて議論する上で欠かせません。特に、分散システムをリソースとトランザクションの観点から捉えることが重要だと感じました。リソースには、サーバー、コンテナ、プロセス、RAM、CPU、ネットワークカードなどの物理的コンポーネントと、クライアント、アプリケーション、APIエンドポイント、データベース、ロードバランサーなどの論理的コンポーネントが含まれます。一方、トランザクションは、ユーザーに代わってシステムが必要とするリソースを編成し、利用するリクエストを指します。Observabilityとは、これらのリソースとトランザクションの振る舞いを理解するための手段だと言えます。
")
次に、テレメトリの歴史について触れられています。テレメトリは、電力プラントや公共電力網などの初期の分散システムを監視するために開発されたものであり、コンピュータシステムにおけるテレメトリは、ログ、メトリクス、分散トレーシングの順に発展してきました。これらは、現在の "Three Pillars of Observability:可観測性の3本柱" と呼ばれる概念の基礎となっています。これは本書だけが主張しているものではなく2022年にリリースされたObservability Engineeringにも言及があります。
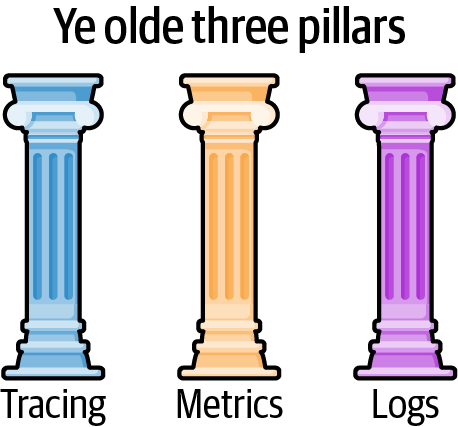
ログは、システムやサービスの状態を説明する人間が読めるテキストベースのメッセージです。メトリクスは、システムの状態とリソース使用率を表すコンパクトな統計情報です。分散トレーシングは、トランザクションを構成する個々のオペレーションを追跡し、レイテンシーの原因を特定するために使用されます。これらの情報は、それぞれ専用のシステムで収集、伝送、分析されてきました。
しかし、著者は "Three Pillars:3つの柱" アプローチの問題点を指摘しています。ログ、メトリクス、トレースが別々のシステムとして扱われているため、データが分断され、相関関係を見つけることが難しくなっているのです。現実のシステムはトランザクションとリソースで構成されており、問題の多くはこれらの相互作用から生じます。例えば、ログを見ただけでは、リソース使用率の変化パターンとの関連性を自動的に特定することはできません。そのため、データを統合し、相関関係を見つけることができるObservabilityシステムが必要となります。まぁ『TEMPLE: Six Pillars of Observability』みたいに6本柱として紹介している記事などもあるのでいろいろです。
著者が提案するのは、"Single Braid of Data:データの単一の編み込み" というコンセプトです。これは、データが互いに組み合わさって一つの流れや構造を形成している様子を表す比喩的な表現として使われることがあります。特に、複数の情報源や種類のデータが統合されて一つの目的や分析のために活用される状況を想像すると良いでしょう。

これは、ログ、メトリクス、トレースを別々のシグナルとして扱いつつ、それらを単一のグラフ構造にまとめるというアイデアです。各シグナルは独立していますが、接点によってすべてがつながっています。こうすることで、コンピュータがグラフを辿って遠く離れた重要な関連性を素早く見つけ出すことができるようになります。相関関係を見つけるには、データを接続する必要があります。そして、そのためには、システムが発するテレメトリに、統一性と一貫性が求められます。統一されたテレメトリは、統一された分析を可能にし、プロダクションシステムに内在する問題を深く理解するために不可欠なのです。そして、このようなテレメトリシステムが実際に存在しており、それがOpenTelemetryです。
OpenTelemetryは、ログ、メトリクス、トレースを単一の一貫したグラフにまとめることで、次世代のObservabilityツールの基盤となるものです。著者は、Observabilityの世界が大きく変わりつつあり、その中心にはOpenTelemetryがあると述べています。トレース、メトリクス、ログ、プロファイリングなど、あらゆる形式のテレメトリを相関させる能力が、これからのObservabilityの鍵となるでしょう。それは、私たちが切望してきたワークフローと自動化を実現するために不可欠です。
OpenTelemetryとObservabilityの未来
明確に言及されているのですが本書は、OpenTelemetryのドキュメントの代替ではなく、その哲学とデザインを説明し、効果的に活用するための実用的なガイダンスを提供することを目的としています。各章では、OpenTelemetryの価値、モデル、アーキテクチャ、インストルメンテーション、ライブラリ、インフラストラクチャ、パイプライン、組織への展開などについて詳しく説明されています。私自身、ソフトウェアエンジニアとして、本書を通じてOpenTelemetryとObservabilityについての理解を深め、実務に活かしていきたいと思います。現代のソフトウェアシステムが直面する課題を解決するために、OpenTelemetryを中心とした新しいObservabilityの時代に備えることが重要だと感じました。詳細については翻訳もされている『オブザーバビリティ・エンジニアリング』を読めば良いと思いました。

Chapter 2. Why Use OpenTelemetry?
本章を読んで、OpenTelemetryが可観測性の課題を解決するための重要な手段であることを改めて理解しました。現代のソフトウェア開発において、システムの複雑性が増大する中で可観測性の重要性が高まっていますが、同時に様々な課題に直面していることが明らかになりました。 システムの複雑性と向き合う書籍は色々ありますがBuilding Microservices, 2nd EditionやEnabling Microservice Success、Software Architecture: The Hard Partsなどの書籍を読むことをお勧めします。
本章では、まず現代のソフトウェア開発における可観測性の重要性が述べられています。ソフトウェアシステムの複雑性が増す中で、開発者やオペレーターは限られたリソースでより多くのことをこなすことを求められています。しかし、システムの規模が大きくなるほど、その動作を正確に把握することは容易ではありません。コードやドキュメントだけでは、実際のプロダクション環境でのシステムの振る舞いを完全に理解することはできないのです。著者は、テレメトリ(遠隔測定)と可観測性(Observability)は、このような課題に立ち向かうための最も強力な武器だと述べています。テレメトリとは、システムが何をしているかを示すデータのことで、可観測性とは、そのデータを分析してシステムを理解する能力を指します。
現代のソフトウェア開発における可観測性の課題
次に、プロダクションモニタリングの現状と課題について触れられています。多くの組織では、メトリクス、ログ、トレースなど、様々なシグナル(信号)を異なるツールで収集し、複数のストレージに保存しています。データのフォーマットや収集頻度もバラバラで、システム全体を把握することが非常に難しくなっているのが実情です。組織の複雑性が増すほど、インシデントの検知や診断、修復に時間がかかるようになります。これは、インシデント対応者が適切なデータを手に入れられないことが大きな原因だと指摘されています。著者によると、データの量、品質、関連性の欠如が、プロダクションデバッグを困難にしているのです。
この課題を解決するために、著者は統一されたテレメトリの重要性を説いています。OpenTelemetryは、ハードコンテキストとソフトコンテキストという概念を用いて、テレメトリデータに豊富なメタデータを付与します。
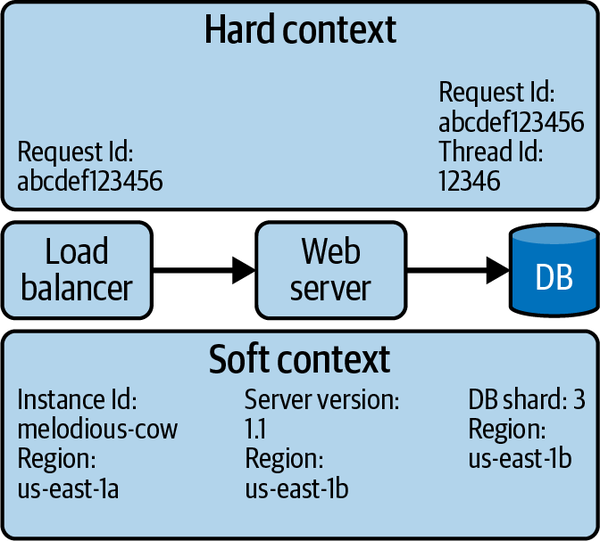
ハードコンテキスト(Hard Context)は、サービス間の因果関係を明示的にリンクするユニークな識別子です。具体的には、各リクエストに割り当てられる一意のIDのことで、分散システム内のサービスがそのIDを伝播させることで、同じリクエストに属するテレメトリデータを関連付けることができます。これにより、個々のテレメトリデータを関連付けるだけでなく、異なるタイプの計装を結びつけることができます。例えば、メトリクスをトレースに関連付けたり、ログをスパンにリンクしたりできるようになります。ハードコンテキストの存在により、人間のオペレーターがシステムの異常動作を調査する時間を大幅に短縮できると著者は述べています。
一方、ソフトコンテキスト(Soft Context)は、各テレメトリが表すものを説明する様々なメタデータです。これには、顧客ID、リクエストを処理したロードバランサのホスト名、テレメトリデータのタイムスタンプなどが含まれます。ソフトコンテキストは、ハードコンテキストほど明示的ではありませんが、データの解釈に役立ちます。ソフトコンテキストは、テレメトリデータに固有の次元を追加し、そのデータが何を表しているのかを説明するのに役立ちます。
また、著者はテレメトリのレイヤリングの重要性についても言及しています。
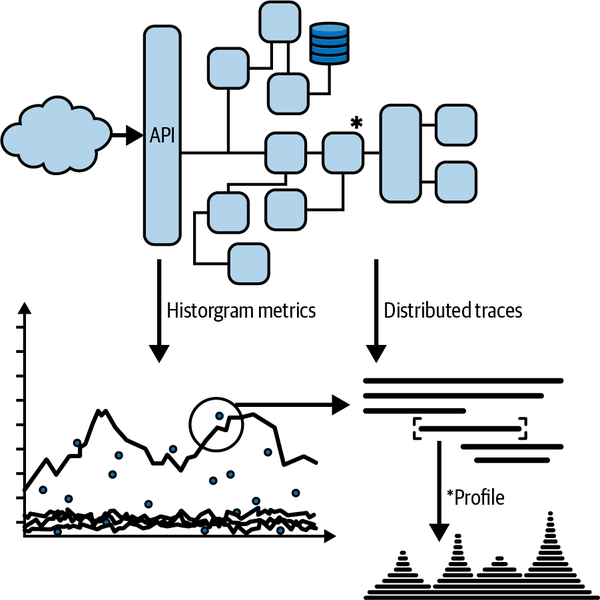
メトリクス、トレース、ログなどの異なるシグナルを補完的に使用し、適切な抽象度でシステムの動作を測定することで、より深い洞察が得られるというのです。メトリクスは統計情報を提供し、トレースは個々のリクエストの詳細を示し、ログはイベントの記録を提供します。単一の "dense" なシグナルを他の形式に変換するのではなく、各レイヤーに適したテレメトリを生成し、コンテキストを介してそれらのシグナルをリンクすることが重要だと指摘しています。そうすることで、システムについて知りもしなかった疑問に答えられるようになるのです。例えば、メトリクスでAPIのレイテンシの異常を検知し、exemplar(代表例)を通じて関連するトレースを特定し、そのトレースからプロファイルやログにリンクすることで、コンポーネントやファンクションレベルの詳細な洞察を得ることができます。
さらに、セマンティックテレメトリ(Semantic Telemetry)という概念も紹介されています。これは、テレメトリデータに意味的な情報を付与することを指します。OpenTelemetryは、自己記述的で移植可能なテレメトリデータを提供することで、あらゆる可観測性フロントエンドで活用できるようにしています。例えば、OpenTelemetryのメトリックポイントには、メトリックの粒度や各属性の説明などのメタデータが含まれています。これにより、フロントエンドはメトリッククエリをより適切に可視化し、測定値の名前だけでなく、実際に何を測定しているのかを検索できるようになります。セマンティックテレメトリにより、開発者はデータの表現や分析方法に縛られることなく、必要な情報にアクセスできるようになります。著者は、OpenTelemetryがシステムを理解するための進化的なステップであり、可観測性の概念を定義し統一するための過去20年間の取り組みの集大成だと述べています。
本章では、開発者、オペレーター、チーム、組織など、様々なステークホルダーの観点から、OpenTelemetryの価値について論じられています。開発者にとってOpenTelemetryは、言語、ランタイム、クラウドなどを問わず、高品質で広範なテレメトリを一貫した方法で生成するための手段です。OpenTelemetryは、テレメトリをソフトウェアの組み込み機能にすることを目指しており、その目標を達成しつつあります。オペレーターにとっては、膨大なデータから重要なシグナルを見つけ出し、システムの信頼性と回復性を確保するための強力なツールとなります。特に、クラウド環境では、ワークロードが実行されるノードが頻繁に変更されるため、障害の原因特定が極めて困難になります。OpenTelemetryは、そのような環境でもテレメトリデータを効果的に収集・分析するための仕組みを提供します。
チームや組織にとっては、ベンダーロックインを防ぎ、既存の計装との互換性を確保するオープンな標準がメリットです。独自のソリューションに依存することは、コストや柔軟性の面でリスクがあります。オープンな標準とオープンソースは、リスクを軽減するだけでなく、将来に備えるためにも不可欠だと著者は主張しています。OpenTelemetryは、テレメトリデータを商品化し、その未来を実現するために尽力しているのです。
最後に、OpenTelemetryが可観測性の課題を解決する理由として、普遍的な標準と相関データの2つが挙げられています。OpenTelemetryは、高品質で普遍的なテレメトリを生成するための標準的な方法を提供し、ベンダーロックインを排除します。すでに主要なクラウドプロバイダーやオブザーバビリティプラットフォームがOpenTelemetryをサポートしており、その採用は避けられない流れになっています。また、OpenTelemetryのデータは、単なるトレース、メトリクス、ログの寄せ集めではありません。それらはすべて同じデータ構造の一部であり、システム全体を記述する単一のグラフとして時間とともに関連付けられているのが特徴です。OpenTelemetryは、オペレーターがシステムを調査する際のワークフローを効果的にモデル化し、相関関係を見つけ出すための機械学習を活用するために、この統合されたデータが不可欠だと考えているのです。
OpenTelemetryがもたらす可観測性の未来
ソフトウェアエンジニアである私にとって、OpenTelemetryは非常に興味深いプロジェクトです。複雑化するシステムを運用する上で、可観測性は欠かせない要素となっています。特に、マイクロサービスアーキテクチャやクラウドネイティブの普及に伴い、システムの動作を把握することがますます難しくなっているのを実感しています。OpenTelemetryは、その課題を解決するための有望なアプローチであり、業界標準となる可能性を秘めていると感じました。統一されたテレメトリ、コンテキストの伝播、レイヤリング、セマンティックテレメトリなど、OpenTelemetryの提供する概念は、可観測性を向上させるための重要な指針になるはずです。本書を通じて、OpenTelemetryの理念と実践方法をしっかりと学び、自身の開発・運用プラクティスに活かしていきたいと思います。
Chapter 3. OpenTelemetry Overview
本章を読んで、OpenTelemetryが提供する統一された可観測性データのモデルとその重要性について理解を深めることができました。
冒頭の "You can't communicate complexity, only an awareness of it.:複雑さを伝えることはできず、それを認識することしかできません。" という言葉が印象的でした。現代のクラウドネイティブなソフトウェアシステムは非常に複雑であり、その複雑さをそのまま伝えることは不可能です。しかし、OpenTelemetryは、システムの動作を把握し、その複雑さを認識するための強力なツールを提供してくれます。
OpenTelemetryの主要コンポーネント
本章では、OpenTelemetryのモデルを構成する主要なコンポーネントについて詳しく解説されています。OpenTelemetryは、トレース、メトリクス、ログという3つの主要な可観測性シグナルを扱います。これらのシグナルは、分散システムにおけるリクエストの流れや、システムの状態、イベントの記録を表現するための手段であり、OpenTelemetryはこれらを統一的かつ効果的に扱うためのデータモデルを提供しているのです。
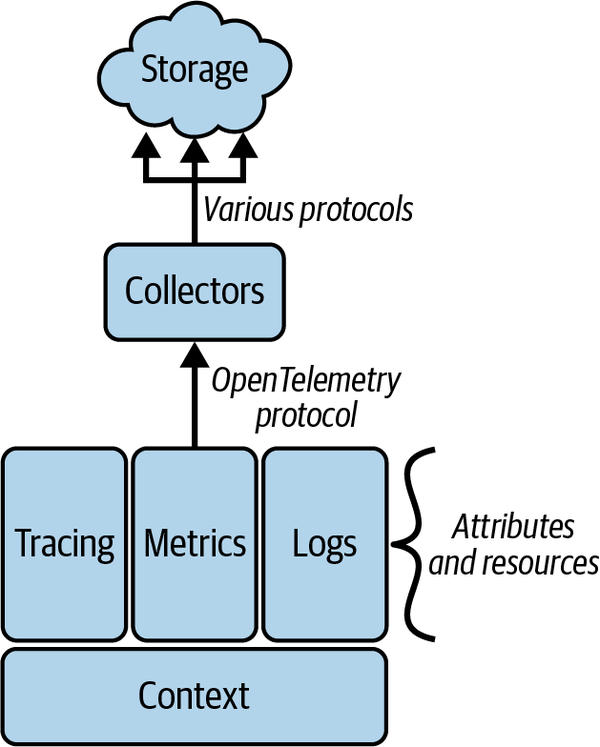
トレースは、分散システムにおける一連の処理の流れを表現するための重要な機能です。OpenTelemetryのトレースは、スパンと呼ばれる個々のログの集まりとして構成され、これらのスパンがトレースコンテキストを介して関連付けられることで、エンドツーエンドのトランザクションを表現します。各スパンには、名前、開始時間と終了時間、属性、イベント、リンク、ステータスなどの情報が含まれており、これらを組み合わせることでリクエストの詳細な流れを追跡できます。
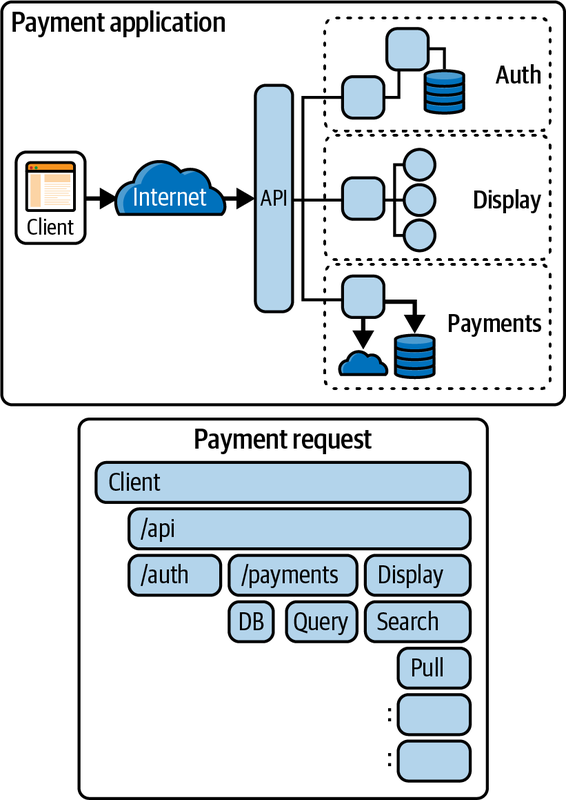
トレースは、エンドユーザーのエクスペリエンスをモデル化するのに最適なシグナルです。1つのトレースが1人のユーザーのシステム内の経路に対応するため、パフォーマンスの問題を特定しやすくなります。また、複数のトレースを集約して分析することで、さまざまな角度からシステムのパフォーマンス特性を把握することもできます。
一方、メトリクスは、システムの状態を数値化してモニタリングするための機能です。OpenTelemetryのメトリクスは、開発者が意味のあるイベントを定義し、そのイベントがどのようにメトリックシグナルに変換されるかを指定できるように設計されています。これにより、オペレーターはコストやデータ量、解像度を制御しながら、メトリックの収集と集約を柔軟に行うことができます。
メトリックには、カウンター、ゲージ、ヒストグラムなどの種類があり、それぞれがシステムの異なる側面を測定するのに適しています。例えば、あるサービスが受信したリクエストのサイズをバイト単位で記録するメトリックを定義し、そのイベントに対して、一定期間の最大値を求めたり、属性ごとの合計値を算出したりするようなアグリゲーションを適用できます。こうした柔軟なメトリックの処理は、OpenTelemetryの大きな強みの一つです。
また、OpenTelemetryのメトリックには、エグゼンプラー(Exemplar)という特殊なハードコンテキストが用意されています。これにより、メトリックのイベントを特定のスパンやトレースにリンクさせ、より詳細なコンテキストを提供することができます。エグゼンプラーを活用することで、メトリックとトレースを効果的に組み合わせたテレメトリのレイヤリングが可能になります。
ログについては、OpenTelemetryは既存のロギングAPIとの互換性を重視しつつ、ログをトレースやメトリクスと関連付けることでその価値を高めています。分散システムでは、ログが異なるコンポーネントから収集され、別々のツールで集約されることが多いため、因果関係を把握するのが難しいという課題がありました。OpenTelemetryは、ログにトレースコンテキストを付与し、メトリクスやトレースへのリンクを提供することで、この課題に対処しているのです。
OpenTelemetryにおけるログの主な用途は、トレース化できないレガシーシステムからシグナルを取得すること、インフラストラクチャリソースとアプリケーションイベントを関連付けること、定期的なバッチ処理のような非ユーザーリクエストの動作を理解すること、他のシグナルへの変換を行うことなどが挙げられます。
OpenTelemetryのコンテキスト伝播
本章で特に重要な概念は、コンテキストです。OpenTelemetryにおけるコンテキストは、テレメトリデータを関連付けるためのメタデータであり、ハードコンテキストとソフトコンテキストの2種類に分けられます。ハードコンテキストは、トレースIDなどの一意の識別子を通じてサービス間の因果関係を明示的に関連付けるものであり、ソフトコンテキストは、各テレメトリが表す情報を説明する属性や資源情報などを指します。
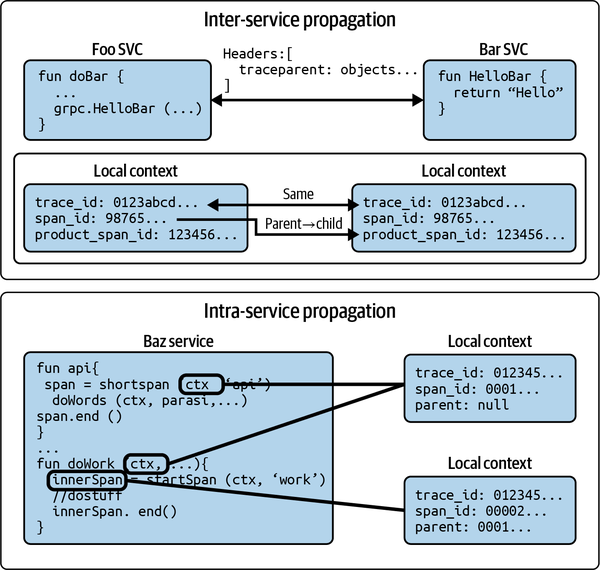
OpenTelemetryの中核をなすのが、こうしたコンテキストを伝播させるための仕組みです。OpenTelemetryでは、プロパゲーターと呼ばれるコンポーネントを使って、コンテキストを異なるプロセス間で受け渡しします。リクエストが開始されると、OpenTelemetryは登録されたプロパゲーターに基づいてそのリクエストの一意の識別子を生成します。この識別子がコンテキストに追加され、シリアライズされて次のサービスに送信されます。受信側のサービスはそれをデシリアライズし、ローカルのコンテキストに追加します。これにより、分散トレーシングにおけるスパン間の関係性を維持したまま、テレメトリデータを収集・伝送することができるのです。
プロパゲーターは、W3C Trace Contextのようなハードコンテキストだけでなく、Baggageと呼ばれるソフトコンテキストの値も伝播させることができます。Baggageは、顧客IDやセッションIDのような、他のシグナルに付与したい値を、それが作成された場所から、システムの他の部分に伝送するためのメカニズムです。ただし、一度追加されたBaggageは削除できず、外部システムにも伝播されるため、その使用には注意が必要です。
コンテキストに含まれるもう一つの重要な要素が、属性(Attribute)とリソース(Resource)です。属性は、テレメトリデータが表す内容を説明するためのキーと値のペアであり、OpenTelemetryにおけるメタデータの基本的な形式です。属性を使うことで、テレメトリデータを特定の次元でフィルタリングしたり、グループ化したりすることができます。
属性には、文字列、真偽値、数値などのシンプルな値を割り当てることができます。また、同じ型の値の配列を割り当てることもできますが、属性のキーは一意でなければならないという制約があります。属性の数は無制限ではなく、デフォルトでは1つのテレメトリデータにつき最大128個に制限されています。これは、属性の作成やアサインにはコストがかかるためであり、また、メトリックに属性を追加する際には、時系列データベースへの書き込み時にカーディナリティ爆発を引き起こす可能性があるためです。
カーディナリティ爆発を防ぐには、可観測性パイプラインやビューを使ってメトリックのカーディナリティを削減したり、高カーディナリティの属性をメトリックから除外してスパンやログに使用したりするのが効果的です。
リソースは、属性の特殊なタイプで、プロセスの存続期間中は変化しない情報を表します。ホスト名やクラウドプロバイダーのゾーン、Kubernetesのノード名などがリソース属性の例です。
また、セマンティック規約も重要な概念です。OpenTelemetryは、属性のキーや値に関する一貫した規約を定めることで、テレメトリデータの解釈を容易にし、異なるシステム間での相互運用性を高めています。これらの規約は、OpenTelemetryプロジェクト自体が提供するものと、各組織が独自に定義するものの両方があります。セマンティック規約を活用することで、開発者は意味のある属性を使ってテレメトリデータを記述し、オペレーターはそのデータを一貫した方法で分析できるようになります。
例えば、OpenTelemetryのセマンティック規約では、HTTPルートの命名規則、サーバーレスの実行環境情報、pub-subメッセージングのキュー方向などが定義されています。こうした規約に従うことで、異なるサービスや環境から収集されたテレメトリデータを統一的に扱うことができます。
OpenTelemetryのもう一つの重要な特徴は、OpenTelemetry Protocol (OTLP)の存在です。OTLPは、テレメトリデータを異なるコンポーネント間で効率的かつ柔軟に伝送するための標準的なデータフォーマットとプロトコルであり、多様な生成者と消費者に対して大きなメリットをもたらします。生成者は既存のフォーマットからOTLPへの変換レイヤーを介してOpenTelemetryと統合できるようになり、消費者は特定のベンダーに縛られることなく、幅広いオープンソースおよび商用ツールとのインターフェースを確保できます。
OTLPは、バイナリとテキストベースの両方のエンコーディングをサポートしており、CPUとメモリの使用量を抑えることを目指しています。また、新しいシグナルが追加された場合にも、レガシーのレシーバーとエクスポーターとの下位互換性を維持するよう設計されているため、長期的な投資の保護にもつながります。
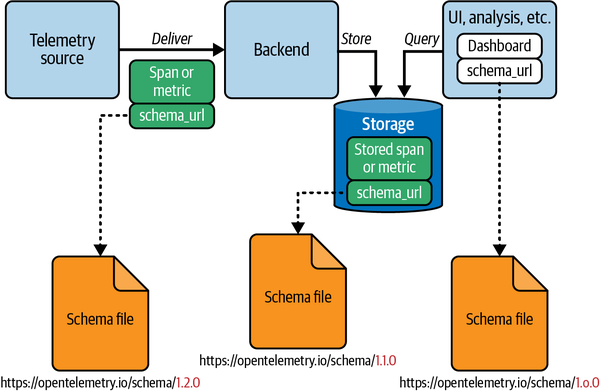
最後に、OpenTelemetryのバージョニングと安定性についても言及されています。OpenTelemetryでは、厳密なバージョニングと安定性のガイドラインが定められており、ユーザーは長期的なサポートとスムーズなアップグレードを期待できます。また、テレメトリスキーマの概念を通じて、セマンティック規約の変更に柔軟に対応することも可能です。スキーマを認識するバックエンドを構築したり、OpenTelemetry Collectorでスキーマ変換を行ったりすることで、分析ツールで新しいセマンティック規約のサポートを活用しつつ、既存のサービスの再計装やテレメトリ出力の再定義を行わずに済むようになります。
OpenTelemetryのバージョニングは、v1.0ラインに沿って継続的に更新されていきます。APIとSDKの安定性についても、明確なポリシーが定められています。例えば、安定版のAPIには12ヶ月間のバグ修正サポートと24ヶ月間のセキュリティサポートが提供されます。こうした長期的なサポート体制により、ユーザーは安心してOpenTelemetryを採用し、継続的に活用していくことができるのです。
SREにとってのOpenTelemetryの意義
SREの立場から見ると、OpenTelemetryの登場は大きな意味を持ちます。複雑化するシステムを運用する上で、可観測性は欠かせない要素です。しかし、従来のアプローチでは、異なるシグナルを別々のツールで収集・分析する必要があり、システム全体の把握が難しいという課題がありました。OpenTelemetryは、トレース、メトリクス、ログを統一的に扱うためのデータモデルを提供し、コンテキストの伝播によってそれらを関連付けることで、この課題に対処しようとしています。
単一障害点の特定、パフォーマンスボトルネックの分析、異常検知など、SREが日々直面する課題に対して、OpenTelemetryの統一されたテレメトリデータは大きな力を発揮するはずです。また、分散トレーシングを活用することで、マイクロサービス間の複雑な相互作用を可視化し、問題の根本原因を素早く特定することもできます。
加えて、OpenTelemetryのセマンティック規約は、SREにとって大きなメリットをもたらします。規約に沿ったテレメトリデータを活用することで、サービスのSLOを定義したり、システム全体のヘルスを評価したりするための指標を統一的に扱えるようになります。これは、複数のチームやサービスが関わる大規模なシステムの運用において特に重要な意味を持ちます。
また、OpenTelemetryがベンダー中立であることも見逃せません。クラウドプロバイダーやオブザーバビリティツールの乗り換えを検討する際に、テレメトリデータの継続性や移植性が確保されるのは大きなメリットです。特定のベンダーに縛られることなく、柔軟にツールを選択し、組み合わせることができるのです。
セマンティック規約やOTLPのような標準化の取り組みは、ベンダーロックインを回避し、相互運用性を高めるために重要です。マイクロサービスアーキテクチャやクラウドネイティブ環境が普及する中で、オープンでポータブルな可観測性データは、SREにとって不可欠な資産となるでしょう。
本章を通じて、OpenTelemetryが提供する可観測性データのモデルとその設計思想について深く理解することができました。トレース、メトリクス、ログの統一、コンテキストの伝播、セマンティック規約、標準プロトコル、安定性へのコミットメント。これらの要素が組み合わさることで、OpenTelemetryは現代の複雑なソフトウェアシステムに立ち向かうための強力な武器になると確信しました。
私は今後、自身の開発や運用の現場において、OpenTelemetryを積極的に活用し、その効果を実感していくことを強く意識しています。この決意のもと、以下のような具体的な取り組みを計画しています。その過程を読者諸兄とも共有していきたい。
- 既存のサービスへのOpenTelemetryの導入と、レガシーシステムとの統合
- 分散トレーシングを活用したパフォーマンスの可視化と改善
- セマンティック規約に基づくSLOの定義とモニタリング
- 自動化されたオブザーバビリティパイプラインの構築
- OpenTelemetryを活用したサービスマップやトポロジーの可視化
- AIを活用した異常検知やパフォーマンス最適化への挑戦
これらの取り組みを通じて、OpenTelemetryの真価を見極め、その可能性を最大限に活かしていきたいと思います。また、OpenTelemetryの進化を注視し、その発展に貢献する方法も積極的に探求していきます。オープンソースプロジェクトとしてのOpenTelemetryは、世界中の技術者が協力し合うことで、さらなる飛躍を遂げるでしょう。可観測性の未来を切り拓くOpenTelemetry。その可能性に大きな期待を寄せつつ、本書の続きを読み進めていきます。次章では、OpenTelemetryのコンポーネントの詳細と、それらがオブザーバビリティスタックにどのように適合するのかを探っていきます。
Chapter 4. The OpenTelemetry Architecture
本章を読んで、OpenTelemetryの全体像と、実際のアプリケーションにおける活用方法について理解を深めることができました。
冒頭の "Everyone knows that debugging is twice as hard as writing a program in the first place. So if you're as clever as you can be when you write it, how will you ever debug it?:そもそもデバッグはプログラムを書くことの 2 倍難しいことは誰もが知っています。 では、できるだけ賢く書いたとしても、どうやってデバッグできるでしょうか?" という言葉が印象的でした。デバッグの難しさを考えると、可観測性の重要性は明らかです。OpenTelemetryは、アプリケーションやインフラストラクチャのデバッグを効率化するための強力なツールを提供してくれます。特に、大規模で複雑な分散システムにおいては、システムの動作を把握することが非常に難しくなります。そのような環境でこそ、OpenTelemetryの価値が発揮されるのだと感じました。
OpenTelemetryのアーキテクチャ
本章では、まずOpenTelemetryを構成する主要なコンポーネントについて解説されています。
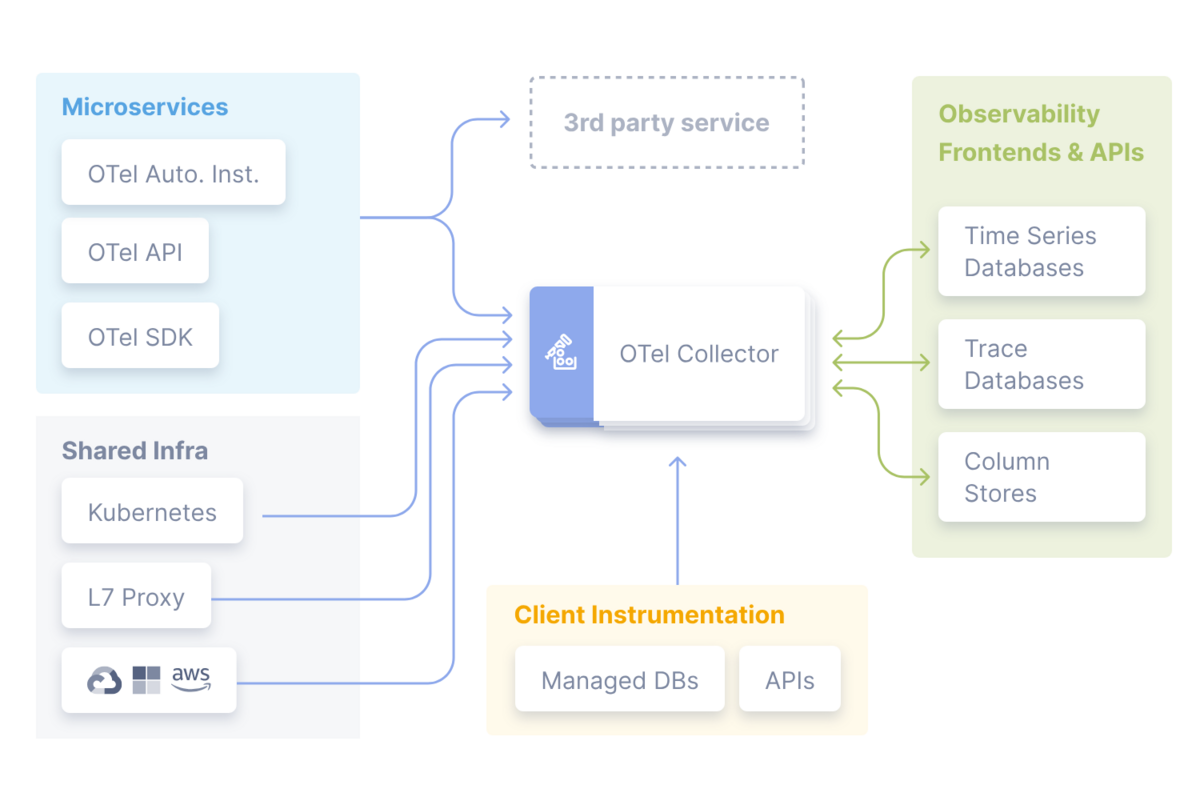
OpenTelemetryは、アプリケーション内に組み込まれる計装、インフラストラクチャ用のエクスポーター、そしてテレメトリデータをストレージシステムに送信するためのパイプラインコンポーネントから構成されています。これらのコンポーネントが連携することで、エンドツーエンドの可観測性が実現されるのです。
アプリケーションレベルでは、ライブラリの計装とOpenTelemetry APIを使った手動の計装の2つのアプローチがあります。
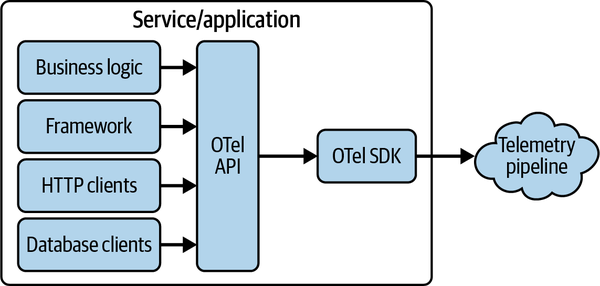
多くの場合、フレームワークやデータベースクライアントなどのライブラリレベルでの計装だけでも、アプリケーションの動作を把握するのに十分なテレメトリデータが得られます。これは、OpenTelemetryがポピュラーなOSSライブラリに対する計装を豊富に提供しているためです。開発者は、これらのライブラリを使うだけで、特別なコードを書くことなくテレメトリデータを収集できるようになります。
さらに、OpenTelemetry SDKを導入することで、これらのライブラリやアプリケーションコードからのAPIコールを実際に処理し、サンプリングやエクスポートを行うことができます。SDKはプラグイン式のフレームワークで、サンプリングアルゴリズムやライフサイクルフック、エクスポーターなどをYAML設定ファイルや環境変数で柔軟に構成できます。開発者は、必要に応じてSDKの機能を拡張し、自分たちのユースケースに合わせたテレメトリパイプラインを構築できるのです。
ただし、ライブラリの計装だけでは不十分な場合もあります。ビジネスロジックに関連する重要なメトリクスを収集したり、より詳細なコンテキスト情報をテレメトリデータに付与したりするためには、OpenTelemetry APIを使った手動の計装が必要になります。特筆すべきは、OpenTelemetry APIが、OpenTelemetryが組み込まれていない環境でも安全に呼び出せるよう設計されていることです。つまり、OSSライブラリの開発者は、OpenTelemetryの計装をライブラリに含めておくことで、そのライブラリを使うアプリケーションがOpenTelemetryを採用しているかどうかに関わらず、シームレスにテレメトリデータを収集できるようになるのです。
一方、インフラストラクチャのテレメトリも重要です。OpenTelemetryは、Kubernetesやクラウドサービスへの統合を進めており、既存のテレメトリデータをOpenTelemetryのパイプラインに取り込むためのコンポーネントも提供しています。例えば、Kubernetesのメトリクスを収集するためのレシーバーや、AWSのCloudWatchLogsからログデータを取り込むためのエクスポーターなどが提供されています。これらのコンポーネントを活用することで、インフラストラクチャ層とアプリケーション層のテレメトリを統合し、より包括的な可観測性を実現できます。
テレメトリパイプラインについては、OpenTelemetry Protocol (OTLP)とOpenTelemetry Collectorが中心的な役割を果たします。大規模な分散システムでは、膨大な量のテレメトリデータが生成されるため、ネットワークの負荷分散やバックプレッシャーなどの課題に対処する必要があります。OpenTelemetry Collectorは、データの収集、処理、エクスポートを柔軟かつ効率的に行うための機能を提供します。現段階で「OpenTelemetry Collectorってなに?」と思った方はkatzchangさんの『入門 OpenTelemetry Collector』をとりあえず、聞いておいてください。
具体的には、Collectorは複数のフォーマット(OTLP、Jaeger、Prometheus、その他の商用/独自ツールなど)でテレメトリデータを受信し、1つ以上のバックエンドにデータを送信できます。また、Collectorはプラグイン式のアーキテクチャを採用しており、受信したデータに対してフィルタリング、属性の追加・削除、サンプリング、バッチ処理などの様々な処理を適用できます。これらの処理をCollectorで集中的に行うことで、アプリケーションへのオーバーヘッドを最小限に抑えつつ、必要なデータを効率的にバックエンドに送信できるようになります。
Collectorのもう一つの重要な役割は、テレメトリデータのセマンティクスを保証することです。Collectorは、OpenTelemetryのセマンティック規約に基づいて、受信したデータの属性をOpenTelemetryの標準的な属性にマッピングします。これにより、異なるフォーマットから収集されたデータを統一的に扱えるようになり、分析ツールやダッシュボードでのデータの解釈が容易になります。
OpenTelemetryを活用したデモアプリケーション
本章では、OpenTelemetryの実際の活用例として、Astronomy Shopというデモアプリケーションが紹介されています。このデモアプリケーションは、マイクロサービスベースのeコマースアプリケーションで、14の独立したサービスから構成されています。
デモアプリケーションのアーキテクチャは、ビジネスロジックを扱うアプリケーションコンポーネントと、可観測性に関連するコンポーネントに大別できます。アプリケーションコンポーネントには、注文処理を担うCheckout Service、在庫管理を行うInventory Service、決済を処理するPayment Serviceなどが含まれます。一方、可観測性に関連するコンポーネントとしては、データの収集・変換を行うOpenTelemetry Collector、ストレージとクエリを担うJaegerやPrometheus、可視化のためのGrafanaなどが含まれます。
これらのサービス間の通信には、gRPCが使用されています。gRPCは、Protocol Buffersを利用した効率的なバイナリ通信プロトコルで、特にマイクロサービス間の通信に適しています。OpenTelemetryは、gRPCのクライアントとサーバーの両方に対する計装ライブラリを提供しているため、gRPCを使ったサービス間通信からも豊富なテレメトリデータを収集できます。これは、OpenTelemetryとgRPCを組み合わせるだけで、ある程度の可観測性が "無料で" 手に入ることを意味しています。
デモアプリケーションを使って、OpenTelemetryによるアプリケーションパフォーマンスの管理方法を実践的に学ぶことができます。例えば、Feature Flag UIを使ってある特定のサービスにエラーを発生させ、そのエラーがどのようにトレースされ、Grafanaのダッシュボードに反映されるかを確認できます。
OpenTelemetryが提供するスパンメトリクスを活用することで、エラーが発生しているサービスやルートを特定し、根本原因の調査に役立てることができます。スパンメトリクスは、トレースデータからメトリクスを生成する仕組みで、OpenTelemetry Collectorの spanmetrics プロセッサを使って実現されます。これにより、個々のトランザクションの詳細を捨象しつつ、システム全体のパフォーマンスを俯瞰的に理解することができるようになります。
デモアプリケーションでは、トレースデータを使った柔軟な分析方法も示されています。GrafanaのExploreビューでは、Jaegerに保存されたトレースデータを検索し、特定のスパンに関連するエラーを調査できます。例えば、oteldemo.AdService/GetAdsというスパンに着目することで、広告サービスの特定のルートで発生しているエラーを発見できました。こうした分析は、メトリクスだけでは難しいものです。トレースデータは、個々のリクエストに関する詳細なコンテキストを提供するため、パフォーマンスの問題を特定するための強力な手がかりとなります。
ただし、フレームワークレベルの自動計装だけでは、こうした詳細な分析には限界があります。アプリケーション特有のビジネスロジックに関連する情報を取得するためには、カスタム計装が必要になります。
デモアプリケーションでは、gRPCの計装に加えて、ビジネスロジックに関連するメタデータをスパンに付加することで、より詳細な分析が可能になっています。例えば、Product Catalog Serviceでは、GetProductメソッドのスパンにapp.product.id属性を追加しています。
func (p *productCatalog) GetProduct(ctx context.Context, req *pb.GetProductRequest) (*pb.Product, error) { span := trace.SpanFromContext(ctx) span.SetAttributes(attribute.String("app.product.id", req.Id)) // ... }
これにより、特定の商品IDに関連するエラーを検出し、トラブルシューティングを効率化できます。こうしたカスタム属性は、ドメイン知識に基づいて開発者自身が定義する必要がありますが、それだけの価値は十分にあるでしょう。
デモアプリケーションでは、OpenTelemetry Collectorを活用したオブザーバビリティパイプラインも実装されています。各サービスからCollectorにデータをプッシュすることで、アプリケーションレベルでの処理オーバーヘッドを最小限に抑えつつ、フィルタリングやバッチ処理、メトリックビューの作成などを柔軟に行うことができます。
この手法には、いくつかの利点があります。まず、テレメトリデータをアプリケーションから可能な限り早く送信することで、予期せぬ負荷による影響を最小限に抑えられます。また、Collectorでデータの処理を集中化することで、ネットワークのトラフィックを削減し、バックエンドへの負荷を分散させることができます。ただし、あまりにも大量のテレメトリを生成すると、ローカルネットワークを圧迫し、別の層でパフォーマンスの問題を引き起こす可能性もあります。状況に応じて適切なバランスを見極める必要があるでしょう。
最後に、OpenTelemetryがもたらす新しい可観測性モデルについて議論されています。従来の「Three Pillars」モデルとは異なり、OpenTelemetryはトレース、メトリクス、ログ、リソースを単一のデータモデルに統合します。これにより、高度に相関性のある均一で高品質なデータが得られるようになります。
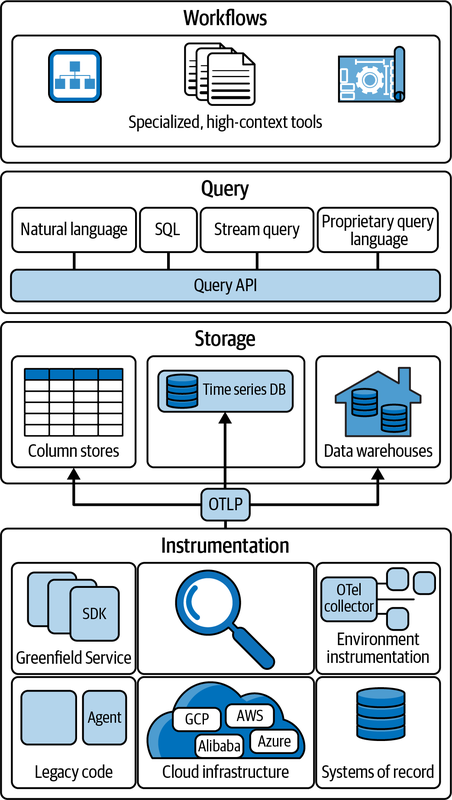
OpenTelemetryは、あらゆるソースからのテレメトリを統合し、OTLPを介して(少なくとも)1つのデータストアに送信するための普遍的な基盤となります。これにより、ビジネスにとっての価値や実現したいユースケースに基づいて、テレメトリストリームを柔軟に処理・送信できるようになります。
将来の可観測性プラットフォームでは、ユニバーサルクエリAPI、自然言語検索、AIアシスタントとの統合、データポータビリティに基づく柔軟なツール選択などの機能が提供されるでしょう。OpenTelemetryは、そうした未来の高コンテキストなデータと、それを理解するためのツールを実現するための重要な構成要素なのです。
実際、OpenTelemetryの登場以降、新しい可観測性ツールが続々と登場しています。これらのツールの多くは、OpenTelemetryを唯一の計装手段として採用しており、オープンソースのカラムストアをベースに構築されています。こうしたツールは、OpenTelemetryが提供する高コンテキストなテレメトリデータを効果的に活用するのに適しています。
さらに、MicrosoftやAmazon Web Servicesなどの大手クラウドプロバイダーもOpenTelemetryを積極的にサポートし始めています。MicrosoftはAzure Monitorの一部としてOpenTelemetryをサポートし、AWSはEKSアプリケーション用のOpenTelemetryベースのAPMエクスペリエンスを発表しました。OpenSearchやClickHouseなどのオープンソースツールも、OpenTelemetryデータのストレージとして人気が高まっています。こうした動きは、OpenTelemetryが業界標準になりつつあることを示しています。
本章を通じて、OpenTelemetryのアーキテクチャと、実際のアプリケーションにおける活用方法について深く理解することができました。アプリケーションとインフラストラクチャの両方から収集されたテレメトリを統合し、パイプラインを通じて効率的に処理・送信するためのコンポーネントの役割が明確になりました。OpenTelemetryは、分散システムの可観測性を実現するための包括的なソリューションであり、その設計思想は非常に合理的で説得力があります。
また、デモアプリケーションを通じて、自動計装とカスタム計装を組み合わせることで、アプリケーションのパフォーマンス管理やトラブルシューティングをどのように強化できるかを実践的に学ぶことができました。OpenTelemetryのスパンメトリクスや、セマンティックに豊富なテレメトリデータは、複雑な分散システムの動作を理解するための強力な武器となります。
OpenTelemetryによる可観測性データの統一性と相関性
特に印象的だったのは、OpenTelemetryがもたらす可観測性データの統一性と相関性です。従来のように、メトリクス、ログ、トレースが別々のシステムで管理されていては、システム全体の動作を俯瞰的に理解することは困難です。OpenTelemetryは、これらのデータを単一のモデルに統合することで、より深い洞察を可能にします。データ間のつながりが明確になれば、パフォーマンスの問題の根本原因を特定したり、異常を早期に検知したりすることが容易になるでしょう。
そして何より、OpenTelemetryが可観測性の新しいモデルを切り拓いていることを実感しました。従来の縦割りのアプローチを脱却し、テレメトリデータの相関性と統一性を追求することで、より深い洞察が得られるようになるでしょう。それは、我々ソフトウェアエンジニアやSREにとって、システムの理解とデバッグを飛躍的に向上させてくれるはずです。
本章で得られた知見を基に、次章以降ではOpenTelemetryのより具体的な活用方法について学んでいきます。アプリケーション、ライブラリ、インフラストラクチャへの計装、テレメトリパイプラインの設計、組織へのオブザーバビリティの展開など、実践的なアドバイスが満載です。
OpenTelemetryの導入に向けて
OpenTelemetryを導入する際のチェックリストが本章で提供されています。このチェックリストには、主要なライブラリの計装状況、SDKへのプロバイダの登録、エクスポーターの設定、伝播形式の選択、SDKとCollector間のデータ送信、Collectorと分析ツール間のデータ送信、リソース属性の設定、トレースの完全性と連続性など、多岐にわたる項目が含まれています。
ただし、チェックリストをなぞるだけでは不十分です。自分たちのシステムの特性をよく理解し、OpenTelemetryをどう活用すべきかを見極める必要があります。例えば、サービスの規模や複雑性、パフォーマンス要件、障害時の影響度などを考慮し、適切なサンプリングレートや収集するテレメトリデータの種類を決定する必要があります。また、既存の監視システムとの連携方法や、運用プロセスへの組み込み方なども検討しなければなりません。
可観測性の未来を切り拓くOpenTelemetry。その真価を見極め、自身の開発・運用プラクティスに活かしていくことが、これからのエンジニアリングに求められているのだと感じました。分散システムの複雑さが増す中で、我々ソフトウェアエンジニアに求められるスキルセットも変化しています。もはや、個々のサービスを深く理解するだけでは不十分です。システム全体を俯瞰し、サービス間の相互作用を追跡し、データの流れを把握する。そうした能力が、これからのソフトウェアエンジニアには必要不可欠になるでしょう。
Chapter 5. Instrumenting Applications
本章を読んで、OpenTelemetryを実際のアプリケーションに導入する際の具体的な手順と考慮点について理解を深めることができました。
冒頭の "It is easier to write an incorrect program than understand a correct one.:正しいプログラムを理解するよりも、間違ったプログラムを書く方が簡単です。" 。アプリケーションの動作を正確に理解することの難しさを表していると同時に、OpenTelemetryによる可観測性の重要性を示唆しているように感じました。
OpenTelemetryのセットアッププロセス
本章では、まずOpenTelemetryのセットアッププロセスが2つのステップ、つまりSDKのインストールと計装(Instrumentation)で構成されることが説明されています。SDKは、テレメトリの処理とエクスポートを担当するOpenTelemetryクライアントであり、一方、計装は、OpenTelemetry APIを使ってテレメトリを生成するためのコードを指します。
計装の自動化については、言語ごとに異なるアプローチが取られています。エージェントを使った完全な自動化を提供する言語もあれば、まったく自動化をサポートしない言語もあります。自動計装は、セットアッププロセスを大幅に簡略化できる一方で、カスタマイズの柔軟性は犠牲になるというトレードオフがあることを理解しておく必要があります。自動計装に関しては逆井さんの計測の手間を省きたい!OpenTelemetry に見る”自動計装”のイマがめちゃくちゃに良い資料なので読んでほしいです。
SDKのインストールでは、OpenTelemetry APIにプロバイダを登録することが重要です。プロバイダは、TracerProvider、MeterProvider、LoggerProviderの3つに分かれており、それぞれがトレース、メトリクス、ログの機能を実装しています。
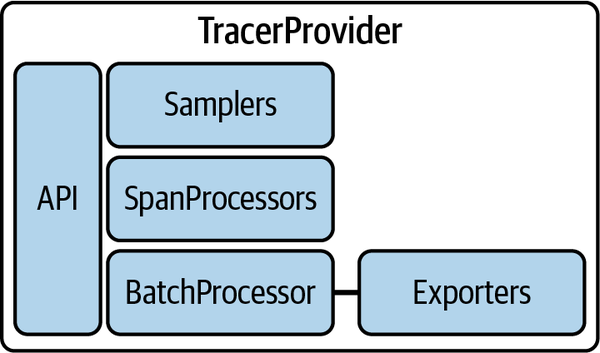
TracerProviderは、サンプラー、SpanProcessor、エクスポーターから構成されます。サンプラーは、トレースをサンプリングするためのアルゴリズムを提供し、SpanProcessorは、スパンの加工や送信を制御します。エクスポーターは、テレメトリデータをバックエンドに送信する際のフォーマットと宛先を定義します。
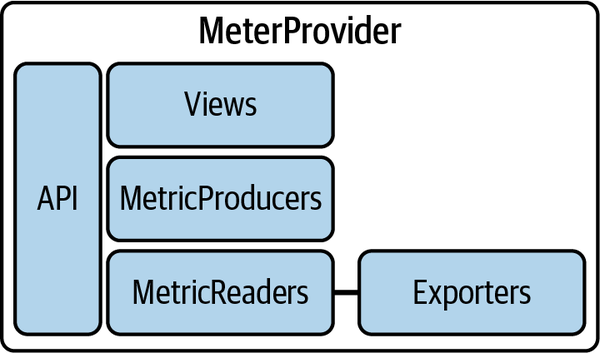
MeterProviderは、ビュー、MetricReader、MetricProducer、MetricExporterから構成されます。ビューは、メトリックのカスタマイズを可能にし、MetricReaderは、メトリックデータの収集とバッファリングを行います。MetricProducerは、サードパーティの計装とのブリッジとして機能し、MetricExporterは、メトリックデータをバックエンドに送信します。
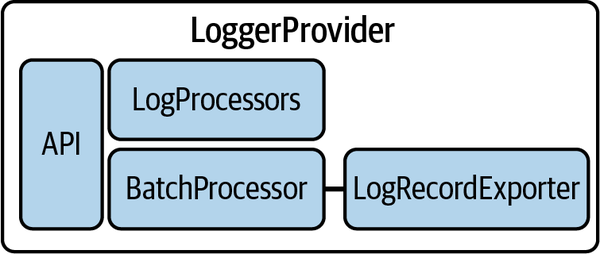
LoggerProviderは、LogRecordProcessorとLogRecordExporterから構成されます。これらは、ログデータの処理と送信を担当します。
プロバイダの設定では、プロトコル、エンドポイント、ヘッダー、圧縮、タイムアウトなどの詳細な設定が可能です。特に、OTLPエクスポーターの設定は重要で、ローカルのCollectorにデータを送信する場合は、パフォーマンスを考慮して scheduledDelayMillis を小さな値に設定することが推奨されています。
また、アプリケーションのシャットダウン時には、SDKのフラッシュ処理が欠かせません。これにより、バッファリングされたテレメトリデータが確実にエクスポートされ、データの欠落を防ぐことができます。
カスタムプロバイダの実装についても言及されていますが、これは非常にまれなケースです。OpenTelemetryのAPIとSDKを分離することで、特殊な要件に対応できる柔軟性を確保しているのです。
OpenTelemetryの設定のベストプラクティス
本章では、設定のベストプラクティスについても詳しく説明されています。設定方法には、コード内での直接指定、環境変数の使用、YAMLファイルの利用の3つがあります。環境変数を使用することで、デプロイ時に設定を切り替えられるため、開発、テスト、本番環境に応じた柔軟な設定が可能になります。最近では、YAMLファイルによる設定が推奨されるようになっており、環境変数よりも簡潔で検証しやすいという利点があります。
リモート設定の分野では、OpAMP(Open Agent Management Protocol)の開発が進められています。これにより、Collectorや SDKの動的な設定変更が可能になり、再起動やデプロイを必要とせずに設定を最適化できるようになるでしょう。
リソース属性の設定も重要なトピックの1つです。リソースは、テレメトリが収集される環境を定義する属性のセットで、サービス、仮想マシン、プラットフォーム、リージョン、クラウドプロバイダーなど、問題の特定に必要なコンテキスト情報を提供します。
リソース属性の多くは、resource detectorと呼ばれるプラグインを使って自動的に収集できます。Kubernetes、AWS、GCP、Azureなど、一般的な環境の情報は、ほとんどの場合、resource detectorでカバーされています。一方、service.name、service.namespace、service.instance.id、service.versionなど、アプリケーション固有のリソース属性は、手動で設定する必要があります。これらの属性は、アプリケーションの動作を理解し、問題の切り分けを行ううえで欠かせない情報となります。
OpenTelemetryの計装のベストプラクティス
計装の設定では、OSSライブラリの自動計装が鍵となります。フレームワークやデータベースクライアントなど、一般的なライブラリの多くは、OpenTelemetryの計装を提供しているため、これらを活用することで、アプリケーションコードへの変更を最小限に抑えつつ、豊富なテレメトリデータを収集できます。一方、ビジネスロジックに特化した情報を取得するためには、手動での計装が必要になるでしょう。
手動の計装を行う際は、新しいスパンを追加するのではなく、既存のスパンにアプリケーション固有の属性を付与することが推奨されています。これにより、スパンの数を抑えつつ、より意味のある情報を取得することができます。
また、計装の粒度を適切に設定することが重要です。関数ごとにスパンを作成したり、コードの行ごとにログを出力したりすることは、必ずしも適切とは言えません。OpenTelemetryを導入する際は、まずは自動計装で提供されるテレメトリから始め、必要に応じて段階的に計装を追加していくのが賢明だと著者は述べています。
ヒストグラムメトリックの活用も推奨されています。特に、指数関数バケットヒストグラム(Exponential Bucket Histogram)は、スケールと範囲が異なる測定値を自動的に調整し、集計することができるため、サービスのパフォーマンス分析に非常に役立ちます。これにexemplarを組み合わせることで、統計情報とトレースの紐付けが可能になり、より詳細な分析が行えるようになります。
特に、自動計装とカスタム計装のバランス、適切なサンプリングとエクスポーターの設定、リソース属性の付与、ヒストグラムメトリックの活用など、具体的な手法については、実践的な示唆に富んでいました。これらを参考に、自社のアプリケーションにおけるOpenTelemetryの設定を最適化していきたいと思います。
OpenTelemetryの導入に向けた考察
また、OpAMPに代表されるリモート設定の動向にも注目したいと考えています。動的な設定変更は、運用の柔軟性を高め、コストの最適化にもつながる重要な技術だと感じました。
一方で、OpenTelemetryの導入にはある程度の学習コストが伴うことも事実です。特に、大規模な分散システムでは、多数のサービスに対して計装を行う必要があり、複数の開発チームが関わることもあるでしょう。そのため、1つのアプリケーションでの導入が成功した後は、セットアップ手順やベストプラクティスをパッケージ化し、社内で共有することが重要だと感じました。
OpenTelemetryへの移行は、一時的なコストを伴うかもしれません。しかし、一度移行が完了すれば、ベンダーロックインから解放され、あらゆる可観測システムと連携できるようになります。長期的な視点に立てば、OpenTelemetryは明らかに投資に値するテクノロジーだと言えるでしょう。
個人的には、2年前に調査した時に比べてOpenTelemetryの自動計装機能の充実ぶりに感銘を受けました。フレームワークやライブラリレベルでの計装が進むことで、アプリケーション開発者の負担が大幅に軽減されるでしょう。今後は、社内の共通ライブラリへのOpenTelemetry組み込みも検討していきたいと考えています。
また、リソース属性の重要性も再認識させられました。特に、service.nameやservice.versionなどの属性は、問題の切り分けに欠かせない情報です。これらの属性を確実に設定することで、障害対応の効率化が期待できます。
ヒストグラムメトリックとexemplarの組み合わせも、非常に興味深い手法だと感じました。レイテンシの分布と、各バケットに対応するトレースを関連付けられることで、パフォーマンスの問題を細かく分析できるようになります。
OpenTelemetryは、アプリケーションの可観測性を飛躍的に向上させる技術であり、SREにとって必須のスキルセットになりつつあります。本章で得た知識を活かし、自社のアプリケーションにOpenTelemetryを適切に導入することで、より堅牢で可観測性の高いシステムを構築していきたいと思います。
可観測性の向上は、単なる技術的な問題ではなく、ビジネスの成功に直結する重要な課題です。OpenTelemetryを活用することで、システムの動作を正確に把握し、パフォーマンスの問題や障害の兆候を早期に検出できるようになります。そのような高度な可観測性を実現することが、私たちSREに課せられた使命だと感じています。
本章で学んだ知識を基盤に、次章ではOpenTelemetryのライブラリへの組み込み方法が説明されるようです。アプリケーションと合わせて、ライブラリレベルでの計装を進めることで、より網羅的で詳細な可観測が可能になるでしょう。引き続き、OpenTelemetryの実践的な活用方法を学んでいきたいと思います。
Chapter 6. Instrumenting Libraries
本章 を読んで、ライブラリへのOpenTelemetryの組み込みが、可観測性の向上に果たす重要な役割について理解を深めることができました。
冒頭の "The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay." という言葉が印象的でした。信頼性を追求するには、究極のシンプルさが必要であり、それは多くの人にとって難しいことだというメッセージが込められています。ライブラリの設計においても、可観測性を考慮に入れることで、シンプルさと信頼性の両立を目指すことができるのだと感じました。
ライブラリの重要性と可観測性の意義
本章では、まずライブラリの重要性について説明されています。ほとんどのアプリケーションでは、リソースの大部分がライブラリ内で消費されていることが指摘されています。アプリケーションコード自体はリソースをほとんど消費せず、代わりにライブラリコードにリソースの利用を指示します。したがって、本番環境での問題を調査する際には、ライブラリの利用パターンに着目することが重要になります。
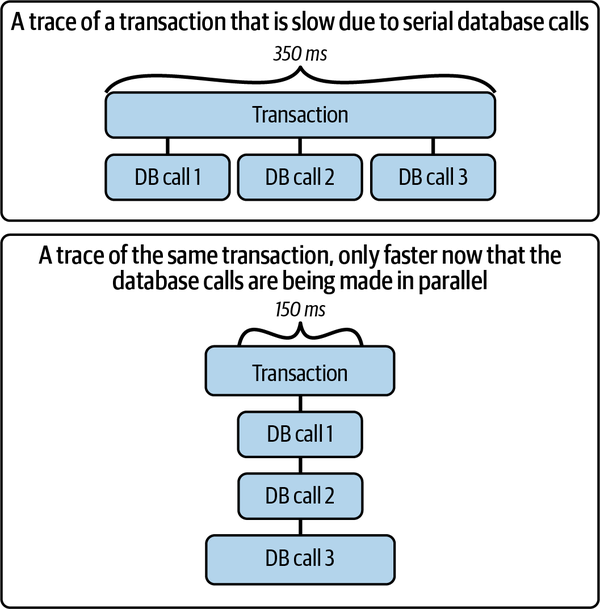
上図は、データベースへのシリアルなコールをパラレルなコールに置き換えることで、レイテンシを大幅に削減できる例を示しています。このように、ライブラリの利用方法を最適化することが、アプリケーションのパフォーマンス向上に直結することがわかります。
それでは、なぜライブラリの開発者自身が計装を行うべきなのでしょうか。著者は、これをネイティブ計装(Native Instrumentation)と呼び、サードパーティによる従来の計装方法よりも優れていると主張しています。
ネイティブ計装には、いくつかの利点があります。まず、ユーザーがOpenTelemetryを導入した瞬間から、すべてのライブラリで自動的に可観測性が有効になることです。これにより、可観測性システムのセットアップにおける障壁が大幅に下がります。
また、ネイティブ計装によって、ライブラリの開発者はユーザーとのコミュニケーションを促進できます。テレメトリデータを通じて、ライブラリの構造や動作を説明したり、ユーザーに警告やアドバイスを提供したりすることが可能になります。ドキュメントやプレイブック、ダッシュボードやアラートなどを充実させることで、ユーザーはライブラリをより効果的に利用できるようになるでしょう。
さらに、ネイティブ計装は、ライブラリの開発者がパフォーマンスを重視していることを示す強力なシグナルにもなります。可観測性をテストの一環として捉え、開発プロセスに組み込むことで、ライブラリの品質向上が期待できます。
OpenTelemetryによるライブラリ計装の課題解決
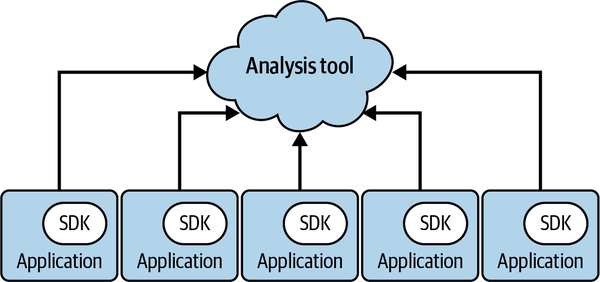
一方で、これまでライブラリの計装があまり進んでこなかった理由として、コンポジションの問題とトレーシングの課題が挙げられています。
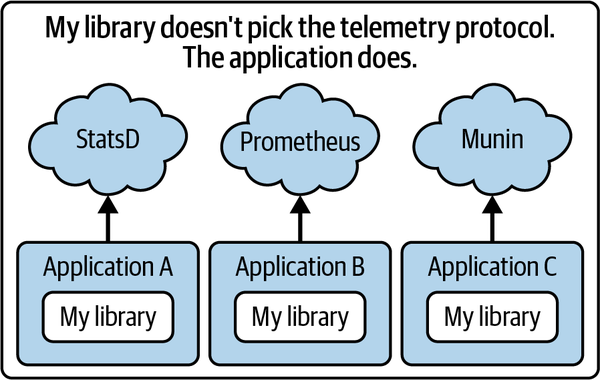
上図のように、アプリケーションごとに異なる可観測性システムが使われている状況では、ライブラリの開発者にとって適切な選択肢がないことがわかります。特にトレーシングは、ライブラリ間でコンテキストを伝播させる必要があるため、すべてのライブラリが同じトレーシングシステムを使用しなければ機能しません。こうした課題を解決するために、OpenTelemetryはライブラリの計装をサポートするための様々な工夫を取り入れています。
まず、OpenTelemetryは計装用のAPIと実装を分離しています。これにより、ライブラリの開発者はAPIを使って計装を行い、アプリケーションの開発者はSDKを設定するという、役割の明確化が図られます。またAPIは最小限の依存関係しか持たないため、依存関係の競合を避けることができます。
次に、OpenTelemetryのAPIは下位互換性を維持しています。APIのメジャーバージョンが頻繁に更新されると、ライブラリ間の互換性が失われてしまいます。そこでOpenTelemetryでは、安定版のAPIをv1.0としてリリースし、v2.0を出す予定はないとしています。これにより、既存の計装が将来にわたって機能することが保証されます。
さらに、OpenTelemetryの計装はデフォルトでオフになっていることも重要なポイントです。
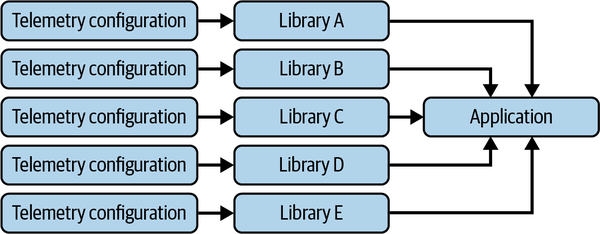
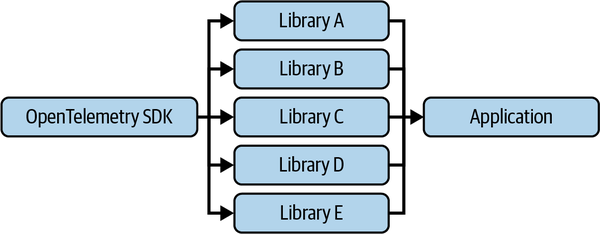
上図を比較すると、ネイティブ計装ではSDKを登録するだけですべてのライブラリから自動的にテレメトリを受信できるのに対し、非ネイティブな計装では各ライブラリに対して個別の設定が必要になることがわかります。これは、ユーザーにとって大きな負担となります。
ライブラリ計装のベストプラクティスと今後の展望
本章の後半では、ライブラリの計装における具体的なベストプラクティスが紹介されています。ライブラリの開発者は、以下のようなチェックリストに沿って計装を行うことが推奨されます。
- OpenTelemetryをデフォルトで有効にする
- APIをラップしない
- 既存のセマンティック規約を使用する
- 必要に応じて新しいセマンティック規約を作成する
- APIパッケージのみをインポートする
- ライブラリをメジャーバージョン番号にピン留めする
- 包括的なドキュメントを提供する
- パフォーマンステストを実施し、結果を共有する
また、データベースやプロキシ、メッセージングシステムなどの共有サービスについては、以下の点にも留意すべきだとしています。
- OpenTelemetryの設定ファイルを使用する
- デフォルトでOTLPを出力する
- ローカルのCollectorをバンドルする
本章で紹介されたベストプラクティスは非常に参考になりました。特に、ネイティブ計装の重要性と、それを実現するためのOpenTelemetryの設計思想は、深く理解しておくべき点だと感じました。自社で開発しているライブラリにOpenTelemetryを組み込むことで、アプリケーションの可観測性を飛躍的に高められるはずです。その際は、本章のチェックリストを活用し、ユーザーにとって使いやすく、パフォーマンスに優れた計装を心がけたいと思います。
また、オープンソースのライブラリについても、積極的にコントリビューションしていきたいと考えています。ライブラリのメンテナーと協力し、ネイティブ計装の普及に貢献できればと思います。
さらに、共有サービスについても、OpenTelemetryを活用した可観測性の向上が期待できます。特に、Kubernetesなどのコンテナプラットフォームとの連携は、運用の効率化に大きく寄与するでしょう。
本章を通じて、改めてライブラリの重要性と、その計装の難しさについて認識を新たにしました。というか言うは易く行うは難しだなって思いました。OpenTelemetryは、これまで困難だったライブラリの可観測性を、エレガントかつ実践的な方法で実現するためのプロジェクトだと言えます。
著者が理想として掲げている、"In five years, we’d like developers to be thinking of runtime observability as being just as important as testing.:5年後にはテストと同じぐらい実行時の可観測性が重要だと開発者が考えるようになる"という未来。その実現に向けて、私もOpenTelemetryコミュニティに参加し、微力ながら貢献していきたいと思います。
Chapter 7. Observing Infrastructure
本章を読んで、クラウドネイティブな環境におけるインフラストラクチャの可観測性の重要性と、OpenTelemetryを活用した具体的な手法について理解を深めることができました。
冒頭の "We build our computer systems the way we build our cities: over time, without a plan, on top of ruins." という言葉が印象的でした。複雑化するソフトウェアシステムは、計画性のない都市の発展と同じように、ruins(廃墟)の上に継ぎ接ぎで構築されているという比喩は的を射ていると感じました。インフラストラクチャの可観測性は、そのような複雑なシステムを理解し、制御するための重要な手段だと改めて認識させられました。
本章では、まずインフラストラクチャ可観測性の定義と意義について説明されています。インフラストラクチャの可観測性とは、単なるリソース使用率のモニタリングではなく、アプリケーションのテレメトリデータとインフラストラクチャのメトリクスを関連付けることで、システム全体の動作を把握する取り組みだと言えます。
著者は、インフラストラクチャのシグナルを収集する際の2つの重要な問いを提示しています。
- アプリケーションのシグナルとインフラストラクチャのシグナルの間にコンテキストを確立できるか?
- これらのシステムを可観測性を通じて理解することが、特定のビジネス/技術的な目標の達成に役立つか?
この2つの問いに対する答えがNoである場合、そのシグナルを可観測性フレームワークに組み込む必要はないと指摘しています。可観測性に組み込むべきシグナルを見極めることが、効果的なインフラストラクチャ可観測性戦略の鍵となるのです。
クラウドプロバイダーのテレメトリデータの収集と活用
続いて、クラウドプロバイダーからのテレメトリデータの収集方法について詳しく解説されています。クラウドプロバイダーは、膨大な量のメトリクスとログを提供しますが、そのすべてが可観測性に有用とは限りません。著者は、クラウドテレメトリを "iceberg" に例えています。
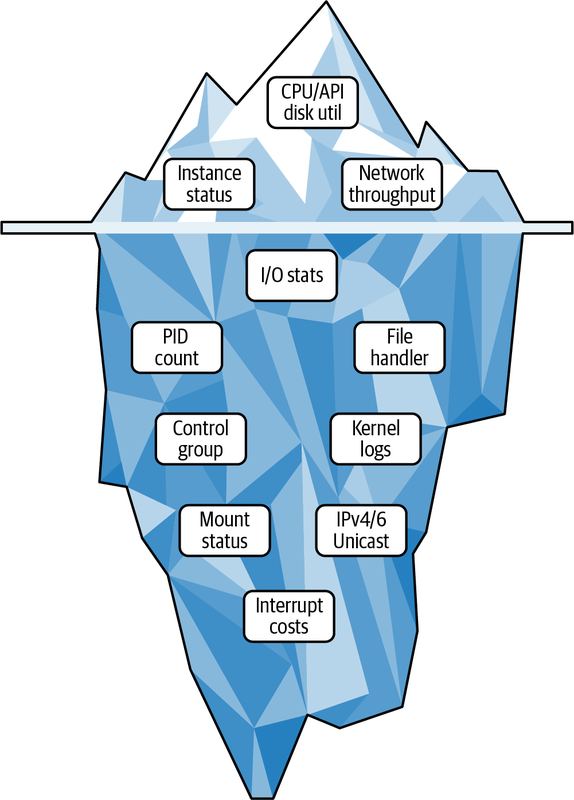
OpenTelemetryはこれらのシグナルをすべて収集することができますが、全体的なモニタリングの姿勢にどのように適合するかを考える必要があります。例えば、単一のインスタンスの稼働状況は、分散システムの全体像を把握する上では限定的な意味しか持ちません。しかし、そのイベントをAPI Gatewayのルーティングの問題と関連付けることができれば、ユーザーリクエストのパフォーマンス低下の診断に役立つでしょう。個々のシグナルが単独では価値がなくても、全体的な可観測性戦略の一部として捉えることが重要なのです。
クラウドメトリクスとログの収集には、主にOpenTelemetry Collectorが使用されます。著者は、本番環境へのデプロイメントにあたって、Collector Builderを使ってカスタムビルドを生成することを推奨しています。これにより、必要なレシーバー、エクスポーター、プロセッサーのみを組み込んだ最適化されたCollectorを構築できます。
また、属性の設定では、パイプラインの早い段階で "too many" の側に寄せることが推奨されています。必要のないデータを後から捨てる方が、存在しないデータを追加するよりも簡単だからです。ただし、新しいdimensionを追加すると、メトリックデータベースが保存する時系列の数が劇的に増加する cardinality explosion を引き起こす可能性があるため、後段でメトリックをallow-listingすることで制御する必要があります。
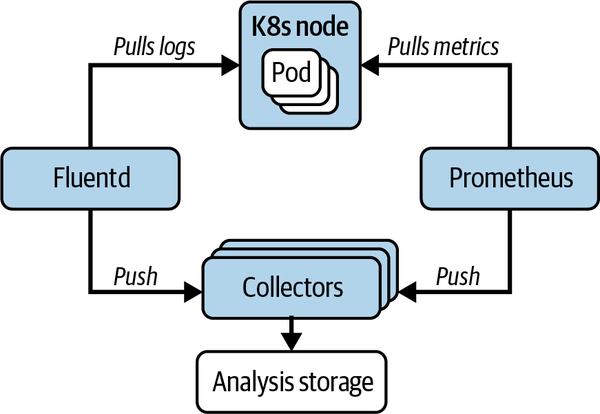
Collectorのデプロイメントアーキテクチャとしては、複数のアグリゲーターやテクノロジーからのテレメトリを統合する "gateway" 方式が紹介されています。
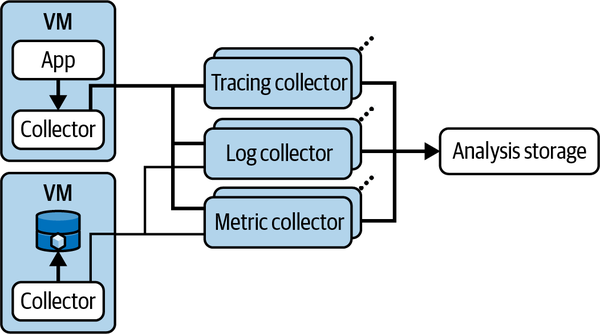
さらに発展させたアーキテクチャでは、各コンポーネントが独立したCollectorを持ち、シグナルタイプごとに水平にスケールできるようになっています。
また、Collectorのパフォーマンスをモニタリングする Metamonitoring の重要性についても言及されています。Collectorが公開するメトリクスを監視することで、リミッターによるデータの拒否やキューの容量不足を検知し、スケールアップの判断に活用できます。
Kubernetesプラットフォームにおける可観測性
次に、Kubernetesプラットフォームにおける可観測性について解説されています。OpenTelemetryは、Kubernetesクラスタ上で稼働するアプリケーションのモニタリングとプロファイリングのためのツール、およびKubernetesコンポーネント自体のテレメトリデータを扱うための手段を提供しています。
Kubernetesのテレメトリデータを収集するには、OpenTelemetry Operatorが重要な役割を果たします。OperatorのTarget Allocator (TA)機能を使うことで、クラスタ内のPrometheusエンドポイントを自動検出し、複数のcollector間でスクレープジョブを均等に分散させることができます。または、k8sclusterreceiver、k8seventsreceiver、k8sobjectsreceiver、kubeletstatsreceiverなどのレシーバーを使って、クラスターのメトリクスとログを直接収集することもできます。
一方、Kubernetes上で稼働するアプリケーションに対しては、Operatorが提供するカスタムリソースを使って、自動計装パッケージをPodにインジェクトすることができます。これにより、既存のアプリケーションコードにトレース、メトリクス、ログの計装を追加できるようになります。
本番環境へのデプロイメントでは、以下のようなアドバイスが示されています。
- 各PodにサイドカーCollectorを配置し、テレメトリの最初の停止点とする
- シグナルタイプごとにCollectorを分割し、独立してスケールできるようにする
- テレメトリの作成と設定の関心を明確に分離する(例: リダクションやサンプリングはプロセスではなくCollectorで行う)
Kubernetesの次は、サーバーレスプラットフォームの可観測性について説明されています。AWS LambdaやAzure Cloud Functionsなどのサーバーレスプラットフォームは、その利便性と独自の構造から人気を博していますが、一方で可観測性の課題も持ち合わせています。
サーバーレスプラットフォームの可観測性
サーバーレスの可観測性では、標準的なアプリケーションテレメトリに加えて、呼び出し時間、リソース使用量、コールドスタート時間などに注目する必要があります。これらのメトリクスは、サーバーレスプロバイダーから提供されるはずですが、アプリケーションテレメトリ自体をどのように取得するかは課題となります。OpenTelemetry Lambda Layerなどのツールを使うことで、AWS Lambdaの呼び出しからトレースとメトリクスを効率的にキャプチャできます。
ただし、関数がアプリケーションアーキテクチャの中でどのような役割を果たしているかによって、サーバーレスインフラストラクチャを監視するための戦略は異なります。Lambda呼び出しを直接トレースするのをスキップし、属性やSpanイベントを介してLambdaを呼び出し元のサービスにリンクするだけで十分な場合もあるでしょう。その場合、Lambdaのサービスログを使って、障害やパフォーマンスの異常に関する特定の実行を特定し、詳細を取得することができます。
非同期ワークフローの可観測性
最後に、キュー、サービスバス、その他の非同期ワークフローの可観測性について議論されています。Apache Kafkaのようなイベントやキューベースのプラットフォームを活用するモダンなアプリケーションでは、可観測性にいくつかの興味深い課題が生じます。
トランザクションのトレースは、"traditional" なリクエスト/レスポンスアーキテクチャほど有用ではない場合があります。トランザクションがいつ終了するのかを特定するのが難しいためです。そのため、可観測性の目標、最適化したいこと、最適化できることについて、多くの決定を下す必要があります。
著者は、銀行ローンの例を挙げて、ビジネスフローと技術フローの違いを説明しています。
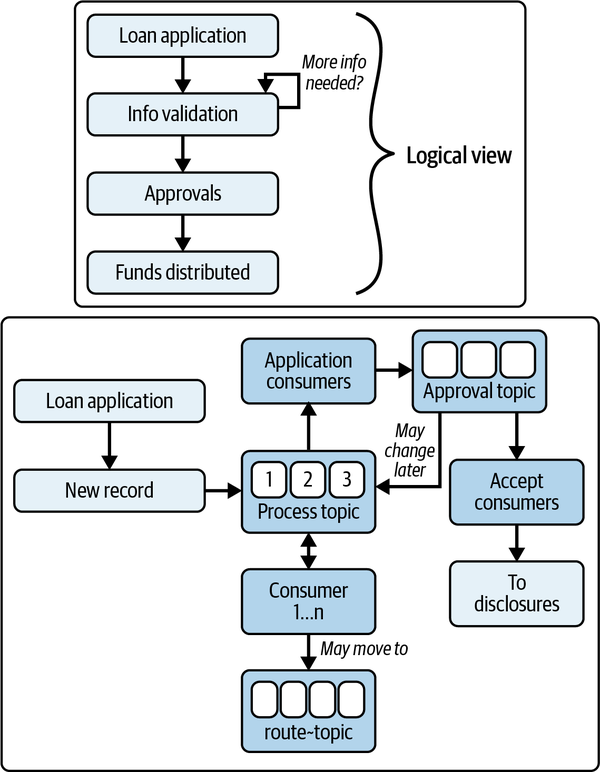
ビジネスフローは比較的シンプルですが、技術フローはパーミュテーションとギャップを考慮する必要があります。ワークフロー図が木というよりも「木の木」のように見える場合は、非同期ワークフローである可能性が高いと指摘しています。
このような状況では、高度に非同期なワークフローを1つのトレースとして考えるのではなく、多くのサブトレースとして捉え、カスタムの相関IDやSpanリンクを介してオリジンにリンクすることが推奨されます。例えば、最初のトレースを「プライマリ」トレースと見なし、各トレースの終端Spanを次のルートSpanにリンクさせる方法があります。
ただし、非同期トランザクションのすべてのサブトレースが同等に有用なわけではありません。Collectorのフィルタとサンプラーを慎重に使用することで、特定のサブトレースをフィルタリングし、カウントやヒストグラムに変換することができます。これにより、ルートSpanを保持しつつ、関連する作業について正確なカウントとレイテンシーを維持することが可能になります。
本章を通じて、インフラストラクチャ可観測性の戦略が、全体的な可観測性の目標に沿って明確かつ簡潔に定義されるべきであることを学びました。アプリケーションやサービスの可観測性とは異なり、仮想マシン、マネージドデータベース、サーバーレステクノロジーを使用したイベント駆動アーキテクチャには、一般的なアプリケーション計装戦略がそのまま適用できるとは限りません。
著者が強調しているのは、インフラストラクチャ可観測性の戦略は、システムが生成する可観測性データを使用するための組織的なインセンティブに沿って、全体的な可観測性の目標に基づいて策定されるべきだということです。この点を理解することが、重要なシグナルに焦点を当て、チームが実際に活用できるデータを収集するための鍵となるのです。
個人的には、本章で紹介されたOpenTelemetryの各プラットフォームへの統合方法が非常に参考になりました。特に、Kubernetesにおける自動計装の仕組みや、サーバーレスプラットフォームでのLambda Layerの活用法は、実務で即座に役立てられる知見だと感じました。
また、非同期ワークフローの可観測性の難しさについても共感を覚えました。ビジネスフローと技術フローのギャップを埋めるために、どのようなテレメトリ設計が求められるのか。著者の提示したアプローチは、非常に示唆に富んでいると思います。
本章で得られた知見を活かし、自社のインフラストラクチャ可観測性を見直していきたいと考えています。特に、クラウドプロバイダーから収集するシグナルの取捨選択や、Kubernetes環境におけるOpenTelemetryの活用、サーバーレスアーキテクチャのための計装戦略などは、優先的に取り組むべき課題だと感じました。
また、非同期ワークフローの可視化についても、著者の提案を参考にしながら、自社の状況に合った手法を探っていきたいと思います。ビジネス要件とシステムアーキテクチャのギャップを可観測性の力で埋めることができれば、より俊敏で信頼性の高いサービス提供が可能になるはずです。
本章のエッセンスは、インフラストラクチャ可観測性の真の目的を見失わないことだと感じました。テレメトリデータの収集や統合は手段であって目的ではありません。あくまでも、ビジネス価値の創出と、エンジニアリング課題の解決に資するものでなくてはならないのです。
そのためには、可観測性戦略を練る前に、自組織の目指すゴールを明確にしておく必要があります。そして、そのゴール達成のために、どのようなシグナルが必要で、どのように活用するのかを設計しなければなりません。本章で紹介された数々の手法は、そのための強力な武器になってくれるでしょう。
読者諸兄には、ぜひ自組織のインフラストラクチャ可観測性の現状を振り返っていただきたいと思います。収集しているテレメトリデータは、本当にビジネスや技術の意思決定に活用できているでしょうか? OpenTelemetryを導入・活用することで、より効果的で統一的な可観測性を手に入れられるかもしれません。
クラウドネイティブ時代のインフラストラクチャ可観測性。それは、複雑さと不確実性に立ち向かうための羅針盤であり、イノベーションを加速させるためのエンジンです。本章で得られた知見を最大限に活用し、自組織の可観測性ジャーニーを着実に前進させていきましょう。
Chapter 8. Designing Telemetry Pipelines
本章を読んで、テレメトリパイプラインの設計と運用が、可観測性の実現に果たす重要な役割について理解を深めることができました。
冒頭の "I have always found that plans are useless, but planning is indispensable." という言葉が印象的でした。計画そのものは役に立たないかもしれないが、計画を立てること自体は不可欠だというメッセージには深く共感しました。テレメトリパイプラインの設計においても、綿密な計画と柔軟な対応の両立が求められるのだと感じました。
テレメトリパイプラインのトポロジーとCollectorの役割
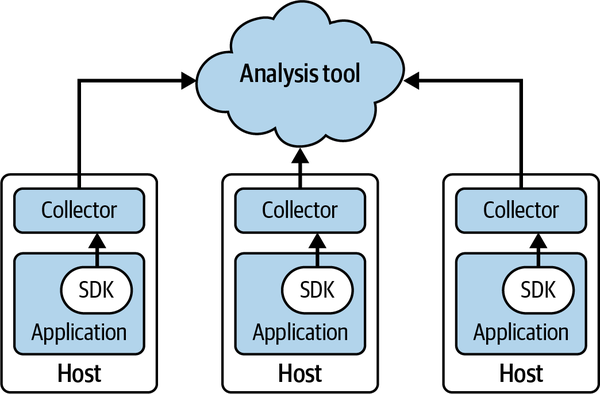
本章では、まずテレメトリパイプラインのトポロジーについて解説されています。システムが小規模な場合は、Collectorを使わずにSDKから直接バックエンドにデータを送信するのが最もシンプルな方法です。
しかし、ホストメトリクスの収集やデータの一時的なバッファリングが必要になると、アプリケーションと同じマシン上でCollectorを実行するローカルCollectorの構成が推奨されます。
さらに、大規模なシステムでは、ロードバランサーを使ってトラフィックを分散するCollectorプールを導入することで、バックプレッシャーへの対応や、リソース消費の最適化が可能になります。
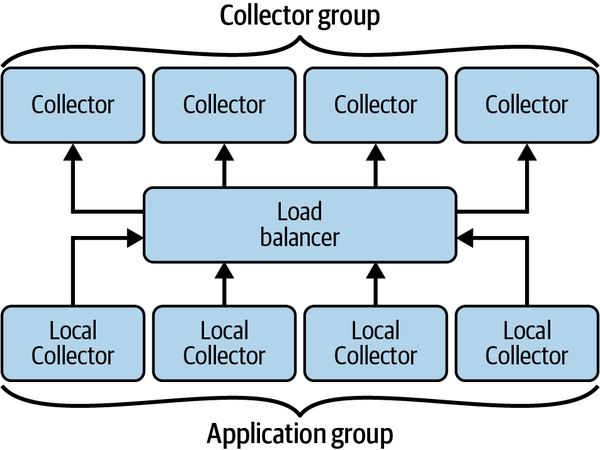
さらに、ゲートウェイとワークロード固有のCollectorプールを組み合わせることで、より複雑なパイプラインを構築できます。
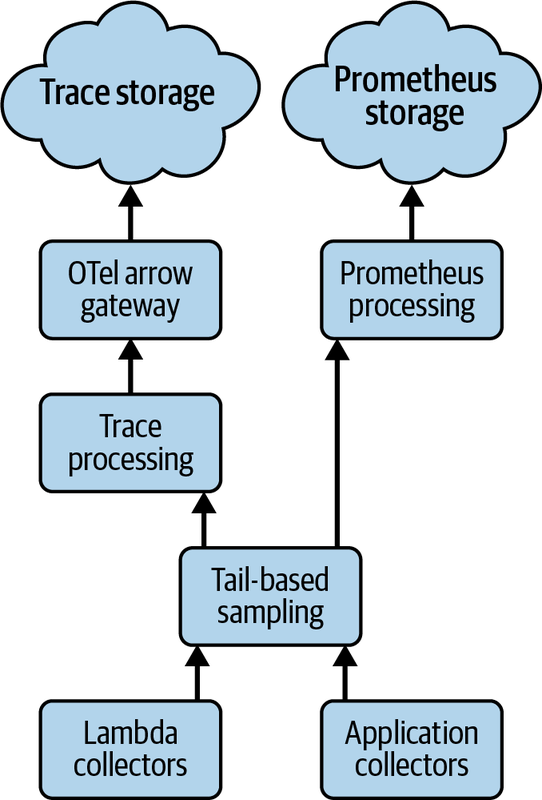
このような特殊なCollectorプールを作成する理由としては、バイナリサイズの縮小、リソース消費の削減、テールベースのサンプリング、バックエンド固有のワークロード、送信コストの削減などが挙げられています。
パイプラインオペレーションの重要性
次に、パイプラインオペレーションについて解説されています。フィルタリングとサンプリングは、不要なデータを削除し、データ量を削減するための重要な手段です。フィルタリングは特定のタイプのデータを完全に削除するプロセスであり、サンプリングは統計的に代表的なデータのサブセットを識別し、残りを削除するプロセスです。
ただし、著者は、サンプリングは危険であり、慎重に行う必要があると警告しています。サンプリング手法とその設定は、データの量と分析の種類に大きく依存するため、普遍的な答えは存在しません。著者は、自社の分析ツールのベンダーやOSSプロジェクトと相談することなく、サンプリングを実装しないことを強く推奨しています。
変換、スクラビング、バージョニングについても詳しく説明されています。属性の変更、機密情報の難読化、セマンティック規約の統一、シグナル間の変換など、テレメトリデータを加工するための様々な手法が紹介されています。特に、OpenTelemetry Transformation Language (OTTL)を使った変換ルールの定義は、柔軟性と可読性に優れていると感じました。
また、プライバシーと地域規制への対応の重要性も指摘されています。テレメトリデータにはPIIが含まれる可能性があるため、データのスクラビングとルーティングを適切に行う必要があります。
バッファリングとバックプレッシャーについては、データ損失を避けるためにパイプラインに十分なリソースを確保することが重要だと述べられています。予期せぬトラフィックのスパイクや問題が発生した場合に備えて、データを一時的にメモリに保持するためのバッファリング容量を確保し、必要に応じてリソースを迅速にスケールできるようにしておく必要があります。
最後に、データのエクスポートについて解説されています。テレメトリデータをどこにエクスポートするかは、組織のニーズに応じて決定する必要があります。デフォルトのオープンソースの可観測性スタックには、Prometheus、Jaeger、OpenSearch、Grafanaなどが含まれますが、OpenTelemetryをサポートする商用ツールも数多くあります。
ルーティングプロセッサを使えば、テレメトリの属性に基づいてデータの送信先を動的に決定することもできます。例えば、有料ユーザーと無料ユーザーのトラフィックを別々のツールに送信するといった使い方が可能です。また、ジョブのステップ数の分布を測定するために、スパンをキューにルーティングしてヒストグラムを作成するといったクリエイティブな方法も提案されています。
Collectorのセキュリティと運用
本章では、CollectorのセキュリティとKubernetesにおける運用についても言及されています。Collectorは、他のソフトウェアと同様に、セキュリティを考慮して展開・維持する必要があります。具体的には、受信インターフェースのバインド先の制限、SSL/TLSによるデータの暗号化、認証・認可の設定などが推奨されています。
Kubernetesについては、OpenTelemetry Kubernetes Operatorを使ってCollectorを管理する方法が紹介されています。DaemonSetやSidecarを使ってローカルCollectorを実行したり、DeploymentやStatefulSetを使ってCollectorプールを実行したりできます。また、Operatorを使って、アプリケーションに自動計装を注入し、設定することもできます。
テレメトリコストの管理
最後に、テレメトリコストの管理について議論されています。テレメトリのコストを管理するための最も一般的なアドバイスは、「重要でないものをモニタリングしないこと」だと著者は述べています。誰も注目していないものを追跡し続ける価値はないのです。オブザーバビリティにはあなたが思っているよりもお金がかかるかもしれない。
また、コストと価値のトレードオフを考慮することも重要です。例えば、ユーザーIDなどのカスタムメトリクスは、カーディナリティが高くコストがかかる場合がありますが、特定のユーザーのエクスペリエンスを理解するためには必要不可欠な情報かもしれません。
コスト管理の観点からは、データの解像度を最適化する方法を検討するのが良いアプローチだと著者は提案しています。ヒストグラムメトリクスから正確なカウントが得られる場合は、「速い」トレースの収集と保存を控えることで、コストを節約できる可能性があります。また、個々のログ行を大量に取り込むのではなく、収集時に重複を排除し、メトリクスや構造化されたログに変換するのも効果的です。
本章を通じて、テレメトリパイプラインの設計と運用が、可観測性の実現において極めて重要な役割を果たすことを再認識しました。単にデータを収集するだけでなく、フィルタリング、サンプリング、変換、バッファリング、エクスポートなど、データを適切に処理し、管理することが求められます。
特に、コスト管理とデータの価値のバランスを取ることの難しさについては、示唆に富む議論がなされていました。テレメトリのコストを最小限に抑えつつ、システムの問題を特定し、改善するために必要な情報を確保するには、慎重な判断が必要です。
本章で得られた知見を活かし、自社のテレメトリパイプラインの設計と運用を見直していきたいと思います。特に、Collectorのトポロジーの選択、フィルタリングとサンプリングの適用、データ変換ルールの定義、コスト管理戦略の策定などは、優先的に取り組むべき課題だと感じました。
テレメトリパイプラインは、単なるデータの通り道ではなく、可観測性の要となるコンポーネントです。その設計と運用に十分な時間と労力を投じることで、システムの動作をより深く理解し、問題の予防と解決に役立てることができるはずです。
個人的には、OpenTelemetryの登場によって、テレメトリパイプラインの構築と管理がより容易になったと感じています。かつては、各種ツールやフォーマットの違いに悩まされていましたが、OpenTelemetryがデファクトスタンダードになりつつある今、よりシームレスなデータの統合と処理が可能になりました。
一方で、OpenTelemetryの普及に伴い、テレメトリデータの量と種類が爆発的に増加しているのも事実です。その中で、本当に必要なシグナルを見極め、適切に処理していくことが、これまで以上に重要になってくるでしょう。
本章で紹介されたベストプラクティスやピットフォールは、そのための指針になるはずです。フィルタリングやサンプリングを適切に行い、変換やエクスポートを戦略的に設計することで、コストと価値のバランスを取りながら、可観測性を最大限に引き出していきたいと思います。
可観測性の実現は、単なる技術的な課題ではなく、ビジネスの成功に直結する重要なテーマです。テレメトリパイプラインの設計と運用を通じて、システムの動作を正確に把握し、問題の予兆を早期に検出し、素早く対処することができれば、より信頼性の高いサービスを提供できるようになるはずです。
読者諸兄には、ぜひ自社のテレメトリパイプラインの現状を見直してみていただきたいと思います。OpenTelemetryを活用し、データの収集、処理、エクスポートを最適化することで、可観測性のレベルを引き上げられるのではないでしょうか。
可観測性の未来を切り拓くOpenTelemetry。テレメトリパイプラインの設計と運用は、その実現に向けた重要な一歩です。本章で得られた知見を糧に、自社のシステムにおける可観測性の向上に取り組んでいきましょう。
次章では、OpenTelemetryへの移行戦略について解説されるそうです。レガシーシステムからのスムーズな移行や、組織全体でのオブザーバビリティの文化の醸成など、大規模な導入に向けたヒントが得られるはずです。引き続き、OpenTelemetryの実践的な活用方法を学んでいきたいと思います。
Chapter 9. Rolling Out Observability
本章を読んで、可観測性の組織への展開における重要な考慮事項と戦略について理解を深めることができました。
冒頭の "Just because the standard provides a cliff in front of you, you are not necessarily required to jump off it." という言葉が印象的でした。標準が目の前に崖を提供しても、必ずしもそこから飛び降りる必要はないというメッセージには深く共感しました。可観測性の導入においても、標準的なアプローチに盲目的に従うのではなく、自組織の状況に合わせて柔軟に対応することが重要だと感じました。
可観測性の真の価値
本章では、可観測性の価値について次のように述べられています。可観測性の真の価値は、組織を変革し、ソフトウェアのパフォーマンスがビジネスの健全性にどのように変換されるかについての共通の言語と理解を提供する力にあります。可観測性は信頼や透明性と同じように、価値そのものなのです。可観測性とは、チーム、組織、ソフトウェアシステムを、その結果を解釈、分析、疑問視できるように構築することへのコミットメントなのだと著者は主張しています。
この課題は、特定の個人やグループだけのものではありません。データを意思決定のインプットとして活用する方法について、組織全体でコミットメントを得る必要があります。そのために、本章では、OpenTelemetryを実装した組織やプロジェクトのいくつかのケーススタディが紹介され、成功への道筋が示されています。
可観測性の展開における3つの軸についても詳しく説明されています。
- Deep(深さ)対Wide(広さ)
- Code(コード)対Collection(収集)
- Centralized(中央集権)対Decentralized(分散)
これらの軸は、OpenTelemetryの実装を推進しているのは誰で、組織のどの部分に触れることができるのかという問いに関連しています。
Deepアプローチの例として、GraphQLサービスを計装した大規模な金融サービス組織のケースが紹介されています。この組織では、GraphQLのトレースが他のシステムから分離されており、エラーの発生場所や下流への影響を可視化することが困難でした。OpenTelemetryのトレースファーストアプローチは、GraphQLの課題に対処するために非常に有効だったそうです。
一方、Wideアプローチの例としては、既存のトレーシングソリューションからOpenTelemetryへの移行を行ったSaaS企業のケースが取り上げられています。この組織では、システムがKubernetes上で動作し、Goで書かれていたため、Wideな移行が容易な判断でした。ただし、移行時には、既存のアラートやダッシュボードが壊れないように注意深く比較する必要があったそうです。
Deepな計装は、単一のチーム、サービス、フレームワークに重点を置いています。特に計装ライブラリが存在する場合は、素早く価値を提供できます。カスタムコード(プロパゲーターなど)を使用して、既存のソリューションに統合することもできます。Deepな計装は、大規模な組織や、より大きな可観測性プラクティスが整備されていない組織で始めるのに適しています。
一方、Wideな計装は、できるだけ多くのサービスに計装を展開することに注力します。システムアーキテクチャによっては、事前の作業がより多く必要になる場合があります。一般的に、完全な移行、または並行して実行するための手段が必要です。Wideな計装は、全体的なシステムモデルの洞察を提供することで、長期的にはより多くの価値をもたらします。
Code対Collectionの軸は、OpenTelemetryエコシステムのどの部分に注力すべきかという問いに関連しています。データの生成に注力するべきか、それとも収集と変換に注力するべきか。理想的には、コードとコレクターの両方を採用し、一方の使用と実装がもう一方を前進させるべきだと著者は述べています。
Centralized対Decentralizedの軸は、組織の規模や形状に関係なく、可観測性の展開において考慮すべき重要な側面です。大規模な組織では、中央の可観測性チームがOpenTelemetryの採用を推進することが多いのに対し、小規模な組織では、個々のサービスチームが浸透によって採用を広めることが多いそうです。
OpenTelemetryの展開における3つの格言
著者は、OpenTelemetryの展開における3つの格言を示しています。
- Do no harm, break no alerts.(害を与えず、アラートを壊さない)
- Prioritize value.(価値を優先する)
- Don't forget the business.(ビジネスを忘れない)
これらの格言は、可観測性の導入が技術的な課題であると同時に、ビジネス上の課題でもあることを示唆しています。
OpenTelemetryの展開後の差別化
次に、OpenTelemetryの導入後に、どのように差別化を図るかについて議論されています。テストとしての可観測性、グリーン可観測性、AI可観測性など、新たな可能性を探ることで、組織に優位性をもたらすことができると著者は主張しています。
特に、テストとしての可観測性は興味深いアイデアだと感じました。トレースとメトリクスを使って、既知の良好な状態に対するシステムの動作を比較し、リグレッションを検出するというアプローチは、継続的デリバリーの品質ゲートとしても活用できそうです。
最後に、大規模な組織でOpenTelemetryを展開するためのチェックリストが提供されています。
- 経営陣が関与しているか?
- 小さいが重要な最初のゴールを特定したか?
- 最初のゴールを達成するために必要なことだけを実装しているか?
- 早期の成功事例を見つけたか?
- 可観測性を集中化したか?
- ナレッジベースを作成したか?
- 新旧の可観測性システムを併存させられるか?
これらのチェック項目は、OpenTelemetryの展開を成功に導くための重要な指針になるはずです。特に、早期の成功事例を見つけ、それを組織全体に広めていくことの重要性は、多くの組織で当てはまるのではないでしょうか。
本章を通じて、可観測性の展開が、単なる技術的な課題ではなく、組織全体で取り組むべき変革の旅であることを再認識しました。OpenTelemetryは、その旅を支える強力な武器になるはずです。しかし、それを最大限に活用するには、自組織の状況を見極め、適切な戦略を選択することが求められます。
Deep対Wide、Code対Collection、Centralized対Decentralizedという3つの軸は、その選択を導くための羅針盤になるでしょう。早期の価値の実現とビジネスへの貢献を意識しながら、段階的にOpenTelemetryを展開していくことが成功の鍵だと感じました。
個人的には、テストとしての可観測性やAI可観測性など、OpenTelemetryの新たな可能性についても興味をかき立てられました。従来のモニタリングの枠を超えて、より高度な分析や自動化につなげていくことで、可観測性の真価を発揮できるはずです。
本章のチェックリストを参考に、自社におけるOpenTelemetryの展開計画を見直してみたいと思います。特に、早期の成功事例の発掘と、組織全体への波及効果の創出には注力したいと考えています。
可観測性は、ソフトウェアエンジニアリングの未来を切り拓く重要な鍵です。OpenTelemetryを活用し、自組織に適した展開戦略を練ることで、その扉を開くことができるはずです。
読者諸兄も、ぜひ自組織における可観測性の現状を振り返り、OpenTelemetryによる変革の機会を探ってみてください。Deep対Wide、Code対Collection、Centralized対Decentralizedの3つの軸を意識しながら、自組織に適したアプローチを見出していくことが重要です。
可観測性の実現は、単なる技術の導入ではなく、組織文化の変革でもあります。OpenTelemetryを起点に、データ駆動の意思決定を根付かせ、ソフトウェアのパフォーマンスとビジネスの成果を強く結びつけていく。そのような組織づくりに、本章の知見が活かされることを期待しています。
皆さんの組織では、可観測性の展開においてどのような課題に直面していますか? Deep対Wide、Code対Collection、Centralized対Decentralizedという3つの軸で見たとき、どのようなアプローチが有効だと考えますか? ぜひ、自組織の状況を共有し、知見を交換し合えればと思います。
本章のまとめと著者の主張
本書のまとめとして、著者らは次のように述べています。OpenTelemetryは、可観測性に必要不可欠なテレメトリデータを標準化・合理化し、従来の「3本柱」の考え方から脱却して、相関性の高い豊かなテレメトリデータの束へと移行するための戦略的な選択肢になる、と。可観測性の実現を通じて、ソフトウェアとビジネスの成果をより強く結びつけていく。そのような取り組みをしてみるのも良いのではないでしょうか(言うは易く行うは難し)?
おわりに
本書『Learning Opentelemetry』を通して、現代のソフトウェアシステムにおける可観測性の重要性と、それを実現するためのOpenTelemetryの役割について深く学ぶことができました。
従来の可観測性の課題であったデータの分断を解消し、トレース、メトリクス、ログなどの様々なテレメトリデータを統合的に扱えるOpenTelemetryは、まさに可観測性の分野における革命的な存在だと言えるでしょう。本書は、OpenTelemetryの設計思想から実践的な活用方法まで、体系的かつ平易に解説されており、可観測性に関する理解を深めるための良きガイドとなりました。
本書を読み進める中で、私自身、以下のような気づきと学びを得ることができました。
- 現代のソフトウェアシステムの複雑性に立ち向かうには、可観測性が欠かせない要素であること。
- OpenTelemetryは、データの相関性と統一性を追求することで、より深い洞察を可能にすること。
- アプリケーション、ライブラリ、インフラストラクチャの各層で適切な計装を行うことが重要であること。
- テレメトリパイプラインの設計と運用が、可観測性の実現において極めて重要な役割を果たすこと。
- 可観測性の展開は、単なる技術の導入ではなく、組織文化の変革でもあること。
以下は、文章の順番を変更し、自然な流れになるように書き換えた結果です。
OpenTelemetryがもたらすデータの相関性と統一性は、従来の縦割りのアプローチからの脱却を意味します。トレース、メトリクス、ログが別々のシステムで管理されていては、システム全体の動作を俯瞰的に理解することは困難です。OpenTelemetryは、これらのデータを単一のモデルに統合することで、より深い洞察を可能にするのです。さらに、可観測性の実現は、単なる技術的な問題ではなく、ビジネスの成功に直結する重要なテーマだと言えます。OpenTelemetryを活用することで、システムの動作を正確に把握し、パフォーマンスの問題や障害の兆候を早期に検出し、素早く対処できるようになります。
また、可観測性の展開が組織文化の変革でもあるという点も非常に重要です。可観測性の真の価値は、組織を変革し、ソフトウェアのパフォーマンスとビジネスの成果を強く結びつけることにあります。そのためには、データを意思決定のインプットとして活用する方法について、組織全体でコミットメントを得る必要があります。
本書で得られた知見を活かし、自社における可観測性の向上に取り組んでいきたいと強く意識しています。具体的には、OpenTelemetryを導入し、アプリケーション、ライブラリ、インフラストラクチャの各層で適切な計装を行うこと、テレメトリパイプラインを設計し、データの収集、処理、エクスポートを最適化すること、そして何より、可観測性をデータ駆動の意思決定の基盤とし、ソフトウェアとビジネスの成果を強く結びつけていくことが重要だと考えています。これらは、これからのソフトウェアエンジニアリングに求められる重要な課題であり、そのような高度な可観測性を実現することが、私たちSREやソフトウェアエンジニアに課せられた使命だと感じています。
そして、読者諸兄にも感謝を申し上げます。1つ1つの気づきや学びを積み重ねることが、私たち自身の成長につながるだけでなく、ひいては業界全体の発展にもつながるのだと信じています。引き続き、OpenTelemetryと可観測性について学び、実践し、議論を深めていければと思います。
みなさん、最後まで読んでくれて本当にありがとうございます。途中で挫折せずに付き合ってくれたことに感謝しています。
読者になってくれたら更に感謝です。Xまでフォロワーしてくれたら泣いているかもしれません。
参考資料
- OpenTelemetry 公式サイト
- OpenTelemetry | Documentation
- Datadog’s $65M Bill and Why Developers Should Care
- Distributed Systems Observability
- Designing Distributed Systems
- Report shows consumers won’t wait long for web pages to load
- Burnout in software engineering: A systematic mapping study
- Observability Engineering
- Introducing Domain-Oriented Microservice Architecture
- Context
- The Four Golden Signals
- Glossary
- Propagators API
- Trace Context | W3C Recommendation
- OpenTelemetry Transformation Language
- Specifications
- End-User Q&A Series: Using OTel at Farfetch
- Why and How eBay Pivoted to OpenTelemetry
- Open Agent Management Protocol
- OpenTelemetry Lambda
- OpenTelemetry Protocol with Apache Arrow
- Certain specialized transformations
- Collector
- OpenTelemetry Semantic Conventions 1.25.0
- OpenTelemetry Operator for Kubernetes
- stanza
- Building a custom collector
- Routing processor
- OpenTelemetry Operator Helm Chart
- Target Allocator
- Traces For Kubernetes System Components