Information Retrieval and Web Search まとめ(25): パーソナライズ
前回は、質問応答とその手法(テキストベース、ナレッジベースを使った方法、それらのハイブリッド)について説明した。今回はパーソナライズについてまとめる。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の25日目の記事です。
パーソナライズ
クエリの曖昧性とパーソナライズ
- 短いクエリではユーザの情報ニーズを明確に表現できない
- たとえば
chiは以下のような意味をもつ- Calamos Convertible Opportunities & Income Fund quote
- The city of Chicago
- Balancing one’s natural energy (or ch’i)
- Computer-human interactions
- つまり、1つのランキングでは、すべてのユーザに最適なものにはできない
- パーソナライズドランキング (personalized ranking) がそのギャップを埋めるただ1つの方法
- パーソナライズに以下のような情報を使うことができる:
- ユーザの長期的な振る舞い(ユーザの長期的な興味を判定するため)
- 短期的なセッション情報(ユーザの現在のタスクを判定するため)
- ユーザの位置情報
- SNS (social network)
- ...
パーソナライズのポテンシャル
- [Teevan, Dumais, Horvitz 2010]
- RQ
- パーソナライズすることによってどのくらいランキングを改善できるか?
- そして、それをどのように計測するか?
- 評価者 (rater) に明示的に検索結果のレーティングを付けてもらう
- ただし、評価者にユーザの情報ニーズが何であったか予想してもらうのではなく、個人的な考えで適合しているかどうかの観点で評価
- 各クエリ q に対して
- 各検索結果の平均レーティングを計算
- 平均レーティングを使って最適ランキング
を決定
- 各評価者 i に対して、ランキング
- そうして計算された各評価者の NDCG の平均
を計算
- すべてのクエリでの
とする
- パーソナライズのポテンシャルを
とする

パーソナライズド検索の概要
- [Pitkow et al. 2002]
- パーソナライズド検索 (personalizing search) の2つの一般的な方法
- クエリ拡張 (query expansion)
- ユーザのクエリを、ユーザの意図 (intent) に応じて修正 (modify) もしくは拡張 (augment) する
- 例: IR --> "information retrieval", "Ingersoll-Rand"
- リランキング (reranking)
- 同じようにクエリを発行し、検索結果を取得したあと、それを並べ替える
- パーソナライズされた結果を得ることも、全体的に適合する (globally relevant) 結果を得ることもできる
- クエリ拡張 (query expansion)
ユーザ意図
- ユーザによって与えられたもの
- ときには役立つ(とくに新しいユーザの場合)
- ユーザの振る舞いやユーザのデータから推論されたもの
- 過去に発行されたクエリ
- 過去に訪れた Web ページ
- 個人の文書データ
- プライバシーを守ることが非常に重要
適合性フィードバックによるパーソナライズ
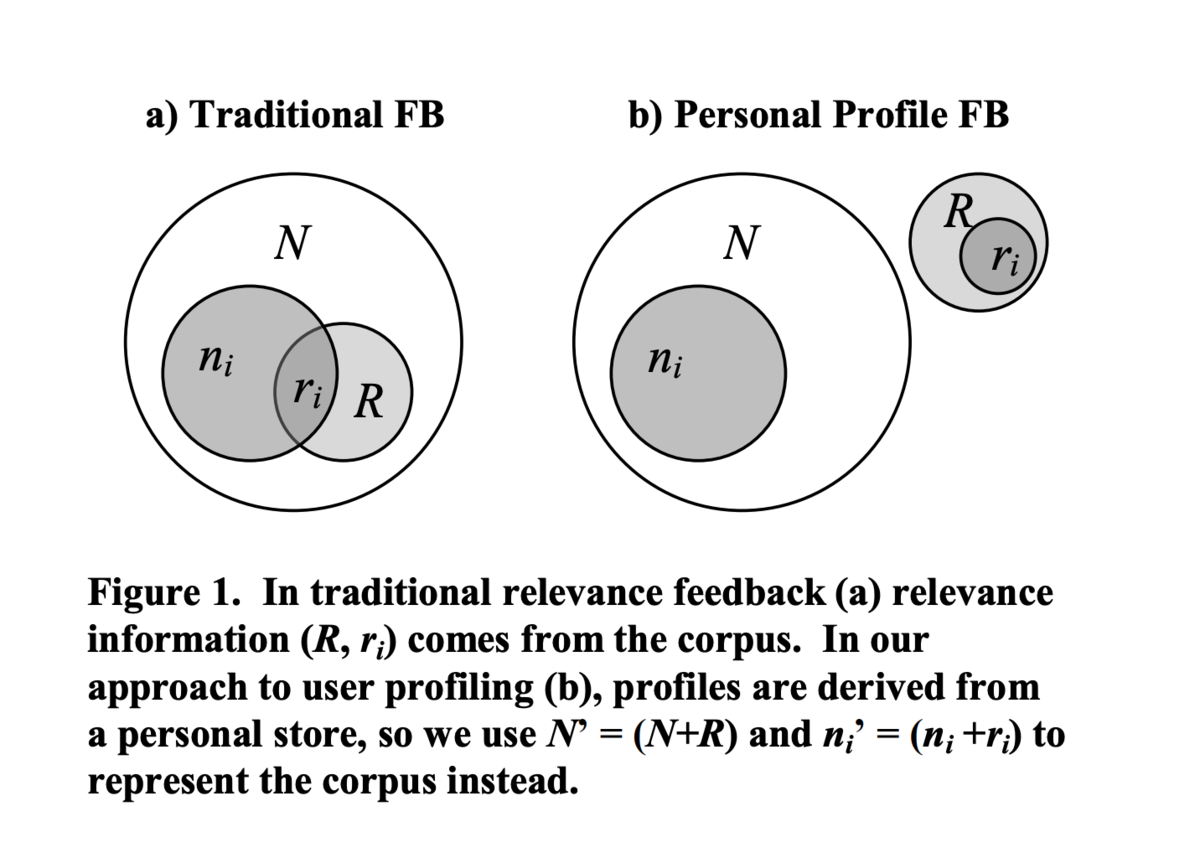
- 古典的な適合性フィードバック (traditional relevance feedback)
: コーパスの文書数
: ターム i を含む文書数
: 適合する文書数
: ターム i を含み、かつ適合する文書
- 個人プロファイル適合性フィードバック (personal profile relevance feedback)
リランキング
- スコア関数として、BM25 を変えたものを使う
- スコア関数は以下の形のものを使う:
はタームが文書中に出現した頻度 (term frequency)
はそのタームの重み (term weight)
- 古典的な適合性フィードバック ([Teevan+ 2005] Figure 1a) では、タームの重み
と
を使って、ユーザデータを使った適合性フィードバック ([Teevan+ 2005] Figure 1b) でのターム重み
コーパスの表現
ユーザの表現
- ユーザが閲覧したページ
- ユーザが閲覧したり送信した Email
- カレンダーの予定
- クライアントマシン上の文書
文書とクエリの表現
- 文書はタイトルとスニペットで表現される
- クエリは、クエリ文字列の近くに出現した単語で拡張される
- もとのクエリが cancer だったとき、以下の下線の単語がクエリになる
The American Cancer Society is dedicated to eliminating cancer as a major health problem by preventing cancer, saving lives, and diminishing suffering through...
Personalized PageRank
- [Haveliwala 2002]
- [Jeh and Widom 2003]
- 通常の PageRank では、すべてのページにおいてテレポート確率ベクトル (teleportation probability vector) p は一様 (uniform) だった
- ユーザの嗜好 (preference) をその p によって表現する
- ユーザがどのページにテレポートするかが、ユーザによって変わる
- p はユーザのブックマークにあるページのなかで一様とする
- もしくは、ユーザが興味をもっているトピックのページについてはテレポート確率が存在することにする
- しかし、 Personalized PageRank を計算するのは高コスト
Linearity theorem
- 任意の preference vector
と
に対して、
と
がそれぞれに対応する personalized PageRank vector だとする
- このとき、
となる任意の非負の定数
,
に対して以下が成り立つ
Topic-sensitive PageRank
クエリタイミングでの計算
- クエリのトピックに対する分布を構築する
- ユーザプロファイルからトピックの分布を計算
- 他のコンテキスト情報も使える
- トピックの preference を使って、topic PageRank vector の重み付き線形和を計算し、それを通常の PageRank の代わりに使う
ソーシャルネットワークでのパーソナライズド検索
- [Curtiss et al. 2013]
- Unicorn: Facebook Graph Search のバックエンド
- Facebook Graph Search
- ノード (node) は人やもの(エンティティ)を表す
- エンティティ (entity) はユニークな 64 ビットの
id - エッジ (edge) はノード間の関係 (relationship) を表す
- エッジの種類は数千タイプある:
friendlikeslikers...
- エッジの種類は数千タイプある:
Unicorn のデータモデル
- ノード数は数億だが、グラフは疎 (sparse)

Unicorn の基本的な集合演算
- クエリ言語は基本的な集合演算をサポートしている
andordifference
- 例1:
id 5かid 6どちらかの友達(or(friend:5 friend:6))
- 例2:
id 5の女性の友達で、id 6の友達ではない人(difference (and friend:5 gender:1) friend:6)
サジェスト (Typehead)
- 最初の数文字を入力するだけでユーザを見つける
- インデックスサーバは、ある一定の文字数までのすべての名前の接頭辞 (prefix) に対してポスティングリストを持っている
- 他の演算子と組み合わせられる
- 例:
(and mel* friend:3)
- 例:
weak-and 演算子
- Unicorn は
weak-andという特殊な演算子をサポートしている optional-hitsoptional-weightというオプションをもつ- その条件が満たされていなくてもよいという意味

(weak-and (term friend:3 :optional-hits 2) (term malanie) (term mars*))の検索:optional-hits 2は、2件まで、この条件(1つめのterm)が満たされていなくても結果に含める、という意味- 検索結果は
2078864となる 62は返されない- 3 つの
term条件の全てを満たしているのは7と64だけ - 左から順番に見ていって、
20と88は条件を 2 つしか満たしていないが、この2つまでは検索結果に含まれる 62に達したときにはすでにoptional-hitsの2を使い果たしているので、これは含まれない
講義資料
参考資料
- J. Teevan, S. Dumais, E. Horvitz. Potential for personalization. 2010
- J. Pitkow et al. Personalized search. 2002
- J. Teevan, S. Dumais, E. Horvitz. Personalizing search via automated analysis of interests and activities. 2005
- P. Bennett et al. Inferring and using location metadata to personalize Web search. 2011
- T. Haveliwala. Topic-sensitive pagerank. 2002. (PDF)
- G. Jeh and J. Widom. Scaling personalized Web search. 2003(PDF)
- M. Curtiss et al. Unicorn: A system for searching the social graph. 2013(PDF)
Information Retrieval and Web Search まとめ(24): 質問応答
前回は、shingle とスケッチを利用した重複検知について説明した。今回は、Web における質問応答を扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の24日目の記事です。
情報検索と質問応答
- 情報検索 (information retrieval) という名前は標準になっているが、実際に行われているのは文書検索 (document retrieval) であることが多い
- それ以上のことはユーザが自身に任されている
- 2025 年のウェブ検索はどうなっているだろう?
- 検索ボックスにキーワードを入力している?
- セマンティックウェブを使っている?
- 自然言語でコンピュータに質問している?
- ソーシャル検索、もしくは人力の (human powered) 検索を使っている?
Google 検索の歴史
- Pigeon アップデート (July 2014)
- ランキングシグナルとして距離や位置情報をより重視するようになった
- Mobilegeddon (Apr 21, 2015)
- モバイル親和性 (mobile friendliness) が主要なランキングシグナルに組みこまれた
- App Indexing (Android, iOS support May 2015)
- 検索結果からアプリに遷移できるようになった
- Mobile-friendly 2 (May 12, 2016)
- 約半数の検索がモバイル由来になった
- Fred (1Q 2017)
- スパムサイト (spammy, clickbaity, fake) を下げるような様々な変更が入った
- 検索結果ページのスニペットがより長くなった (Nov 2017)
- Mobile-first Index (Mar 2018)
- デスクトップ版ではなくモバイル版のページをインデックスするようになった
- 検索結果ページのスニペットの長さが元に戻った (May 2018)
- Medic アップデート
- ページの専門性、権威性、信頼性をより重視するようになった
- ダイエットや栄養、医療品に関するサイトでランキングに大きな変化があった
- コアアルゴリズムアップデート (Mar 2019)
- "Medic 2" 的なアップデートがされた
ナレッジベースを使った検索
- 古典的なテキスト検索ではなく、構造化されているナレッジベース (knowledge base) を使ってグラフ検索を行う
- Google Knowledge Graph
- Facebook Graph Search
- Bing’s Satori
- Wolfram Alpha
- Web ページに埋め込まれている半構造化データを使ったアプリケーションも増えている
Web 検索における最近の課題
- モバイル検索の増加
- 情報の質
- 情報源 (information provenance) や情報の信頼性 (information reliability) は Web においてずっと懸念されてきたが、近年、「フェイクの (fake)」情報が拡散されるようになっている
知的エージェントに向けて
- 2つのゴール
- 文字列を使わない (things, not string)
- 検索ではなく推論 (inference)
質問応答
質問応答のパラダイム
- テキストベースのアプローチ
- TREC QA, IBM Watson, DrQA
- 構造化されたナレッジベースを使ったアプローチ
- Apple Siri, Wolfram Alpha, Facebook Graph Search
- 上記のハイブリッド
"Things, not strings"
| From | To | Requires |
|---|---|---|
| ターム (term) | 概念 (concept) | パース (parsing)、曖昧性解消 (disambiguation)、共参照解析 (coreference) |
| タームの同一性 (term identity) | 含意 (entailment) | 概念の関係性 (concept relations) |
| 共起 (co-occurrence) | 構文的関係 (syntactic relation) | 文書構造、パース (parsing) |
| タームインデックス (term index) | 意味インデックス (semantic index) | 概念の曖昧性解消 (concept disambiguation)、推論 (inference) |
行動と意図
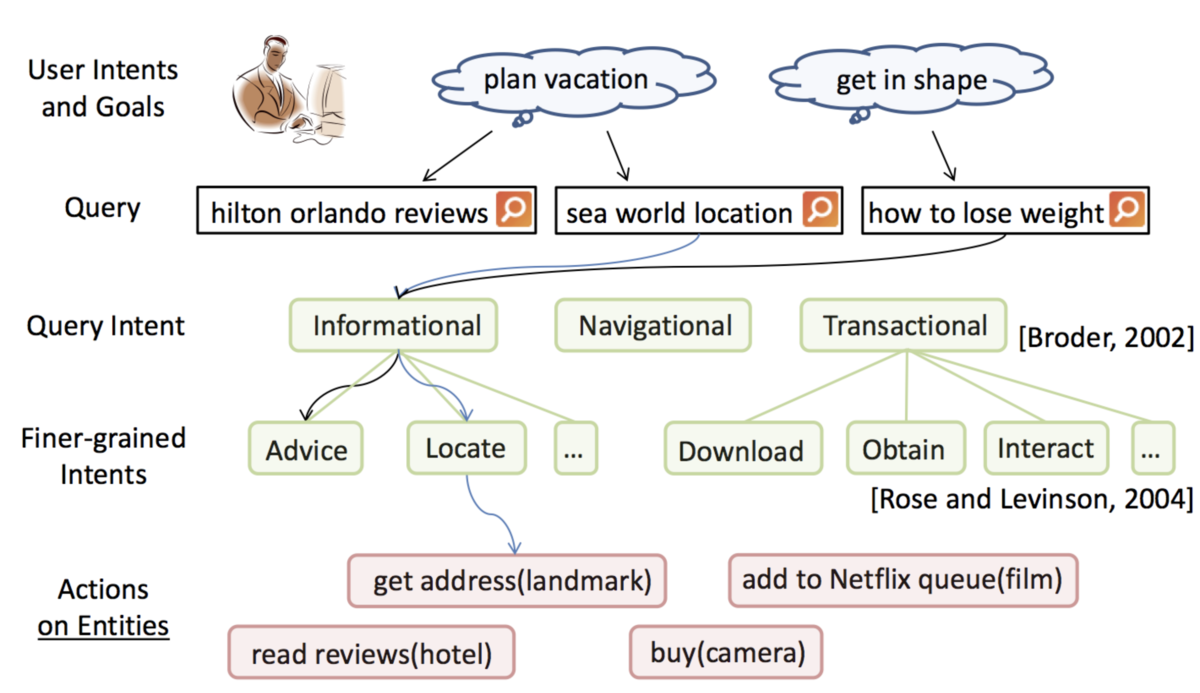
エンティティの曖昧性解消とリンキング
- エンティティが identify されていることが必要
- 固有表現抽出 (named entity recognition; NER)(例: Stanford NER)
- 曖昧性の解消
Siri のアプローチ
- クエリの意味表現 (semantic representation) を構築
- 時刻、日付、場所、エンティティ、数量
- このセマンティクスで構造化データベースにクエリ
- 地理空間データベース
- オントロジー(Wikipedia の infobox、dbPedia、WordNet、Yago)
- レストランのレビュー情報や予約サービス
- 科学データベース
- Wolfram Alpha
テキストベース質問応答
- 質問処理 (question processing)
- パッセージ検索 (passage retrieval)
- 回答処理 (answer processing)
IBM Watson
- ハイブリッドアプローチ
- クエリの浅い (shallow) 意味表現を構築
- 情報検索の手法で回答候補を生成
- オントロジーや半構造化データで augment している
- よりリッチな知識情報を使って、各候補をスコア付けする
- 地理空間データベース
- 時間の推論 (temporal reasoning)
- タクソノミー (taxonomical classification)
言語から知識へ
単語アラインメント
- Wen-tau Yih et al. 2013. Question Answering Using Enhanced Lexical Semantic Models
- 単語のアラインメント(対応関係)があると仮定

LCC の質問応答システム
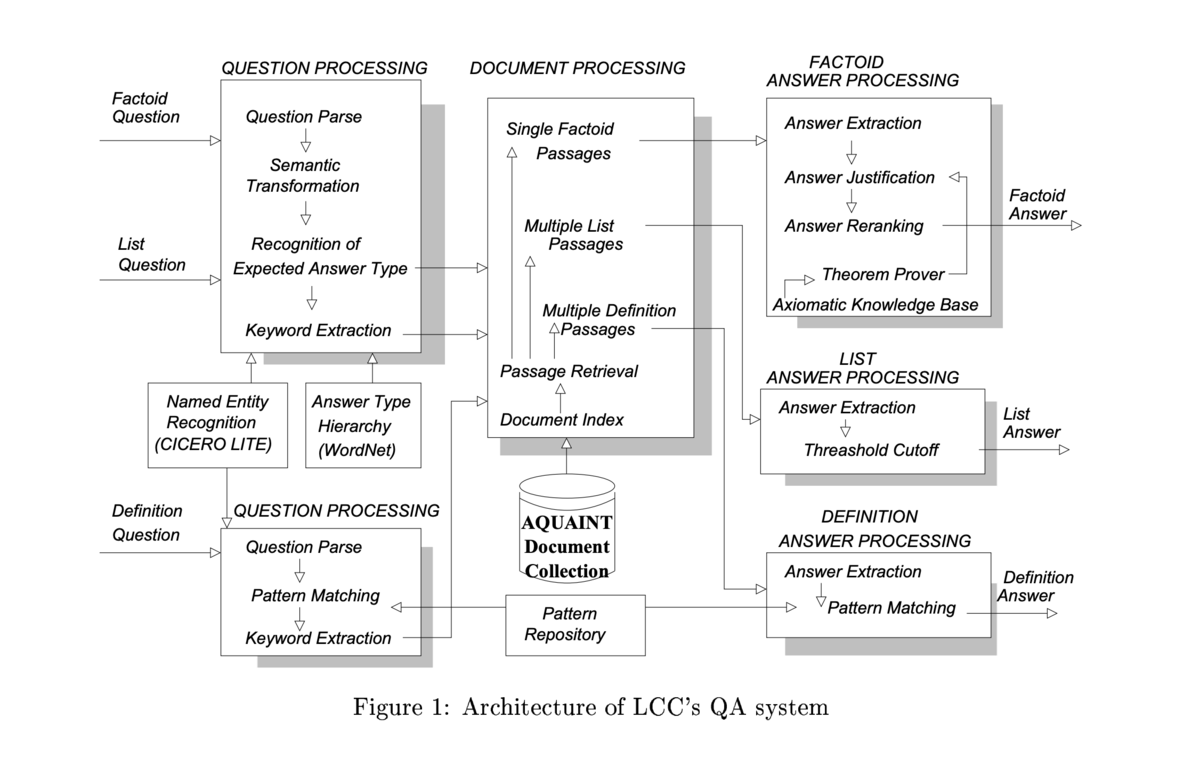
Open-domain Question Answering
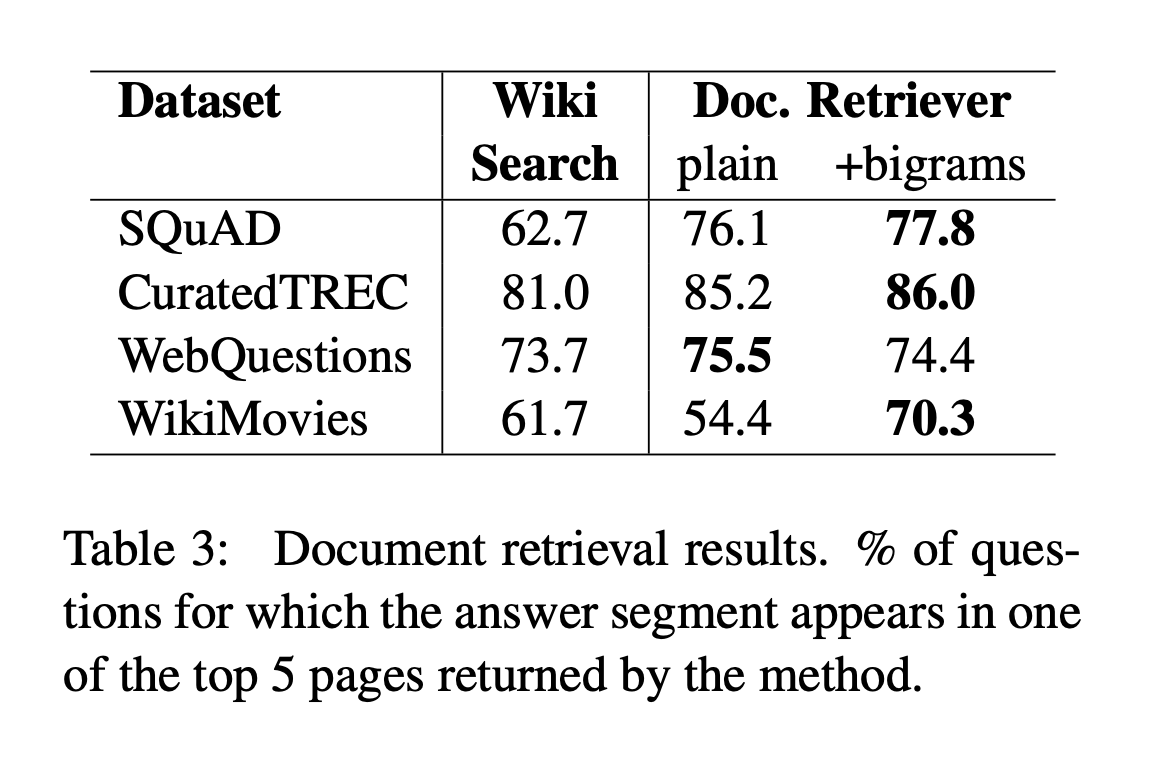
- Chen et al. 2017. Reading Wikipedia to Answer Open-Domain Questions
- 質問応答システム DrQA
- open-domain question: 該当する Wikipedia の記事内の範囲を返すタスク
- 適合する記事の検索 (document retriever) + その記事のテキスト理解 (document reader)

- 古典的な TF-IDF とバイグラムのハッシュを組み合わせると document retriever の性能が上がった
講義資料
Information Retrieval and Web Search まとめ(23): 重複検知
前回は Web クローラの要件やそのアーキテクチャについて解説した。今回は、重複した文書の検知について扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の23日目の記事です。
重複ページの検知
- Web には重複コンテンツがたくさんある
- 厳密な重複検知(= 完全一致 (exact match))は一般的ではない
- だが、準重複 (near duplicate) 検知の例は非常に多い
- 例:ページ内容は同じだが更新日だけが違う
重複・準重複検知
- 重複 (duplication): 完全一致はフィンガープリント (fingerprint) によって検知できる
- 準重複 (near-duplication): 近似マッチ (approximate match)
- 構文的な類似度を編集距離によって計算する
- その類似度の閾値で準重複コンテンツを検知する
- これは推移的にはならないが、推移的として扱うこともある
- A と B、B と C がそれぞれ準重複だったとして、A と C は準重複とは限らない
類似度の計算
- 特徴量
- 文書のセグメント
- 自然な、もしくは人工的な場所で分割
- shingles
- 単語 n-gram などを使う
- 文書のセグメント
- 類似度の指標
- それぞれの文書の shingles に対して定義される
- ジャッカード係数 (Jaccard coefficient)
共通集合の要素数 / 和集合の要素数
- 文書
のshingleを
で表すとすると、文書
と
のジャッカード係数は
スケッチ
- shingles どうしの正確な共通集合 (intersection)
を計算するのは高コスト
- それぞれの shingles から、部分集合を賢く選んで近似する
- 近似した shingles の部分集合をスケッチ (sketch) と呼ぶ
共通集合の要素数 / 和集合の要素数()を、スケッチから推定する
スケッチベクトルの計算とジャッカード係数の推定
- 各文書に対してスケッチベクトル (sketch vector) を作成する
- スケッチベクトルの次元数 m は ~200 次元
- スケッチベクトルの要素が t 以上(80% 以上など)かぶっている文書は準重複 (near duplicate) であるとみなせる
- 準備
- 文書
によるスケッチ
は
(
のうち最小の整数)で計算される

- このスケッチの計算を 200 個のランダム置換
に対して行う
- 200 次元のスケッチベクトルを計算する場合
- このようにして得られた 200 個のスケッチ
を並べたものを、文書 j のスケッチベクトル
とする
- 文書 i と文書 j のペアに対するジャッカード係数
を
で推定する
置換の効率化
- ランダムな置換は計算コストが高い
- 線形の置換でも実用上はうまくいく
- 大きな素数 p に対して、以下のような
{0, ..., p-1}上の置換の集合を考える
- 大きな素数 p に対して、以下のような
まとめ
- shingling は乱択アルゴリズム (randomized algorithm) である
- なんの確率モデルも仮定していない
- ある確率で正しい答えを返す
- 文書のペアに対して準重複検知を行う方法を示した
講義資料
参考資料
Information Retrieval and Web Search まとめ(22): Webクローリング
前回は PageRank などのリンク解析手法について説明した。今回は、Web のクローリングを扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の22日目の記事です。
クローリングの概要
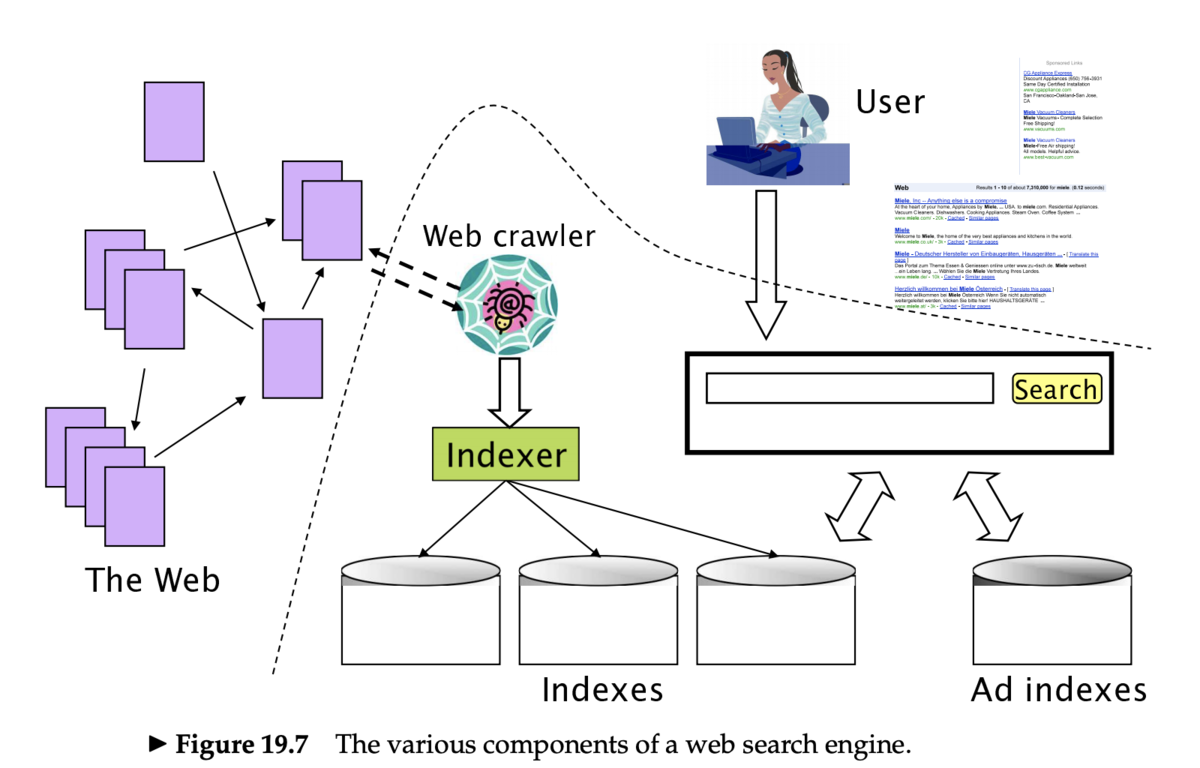
- クローラ (crawler) (もしくはスパイダー (spider)、ロボット (robot)、ボット (bot) とも)は、Web ページのリンクを辿り、検索エンジンにページをインデックスするためのコンポーネント
- これらの一連の処理をクローリング (crawling) という
クローラの動作
- 「シード (seed)」となる既知の URL から開始する
- Web ページをフェッチしたあとパースする
- ページに含まれる URL を抽出する
- 抽出した URL をキューに入れる
- キューにある URL をフェッチし、繰り返す
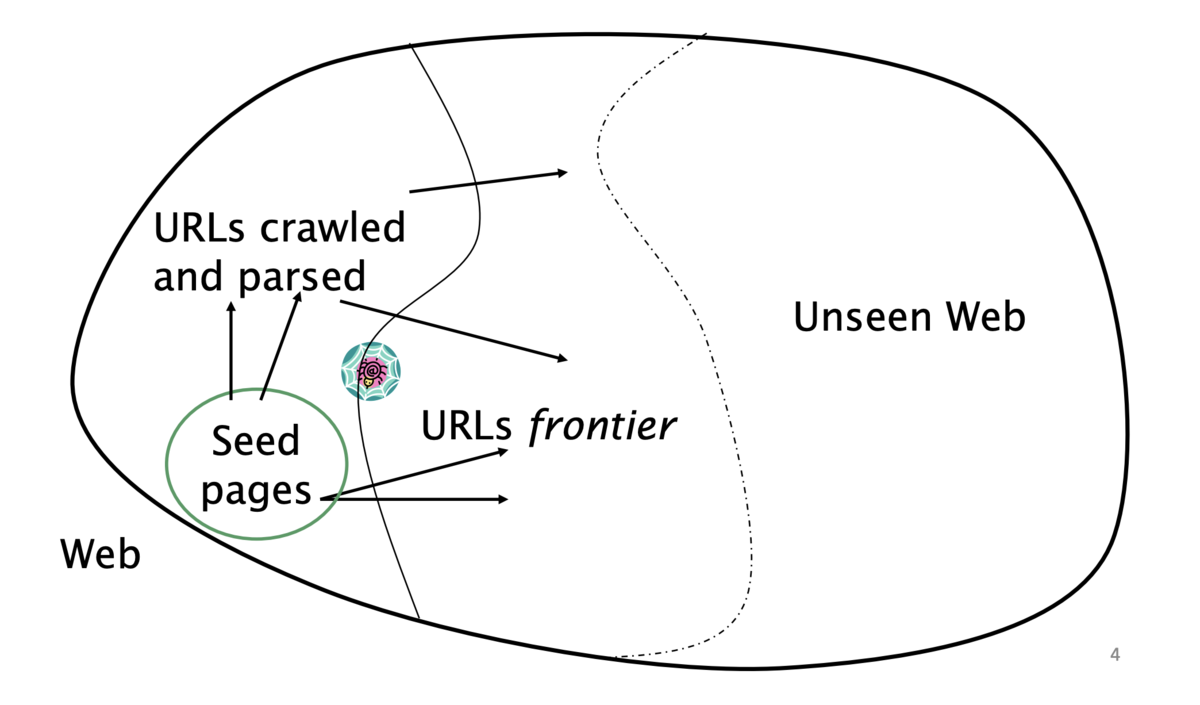
クローリングの難しさ
- Web のクローリングは1台のマシンでは実現不可能
- 上記のすべてのステップは分散化される必要がある
- 悪質なページへの対応
- スパムページ
- スパイダートラップ (spider trap)
- 動的に生成されるページを含む
- リモートサーバへの礼儀正しさ (politeness)
- サーバを高頻度で叩かない
- その他の課題
- リモートサーバのレイテンシや帯域は様々
- ウェブマスターの規定 (webmasters' stipulation)
- サイトの URL の階層をどこまで辿るか
- ミラーサイトや重複ページ
クローラの要件
クローラの MUST 要件
- 頑健 (robust) である
- スパイダートラップや悪質なページから影響を受けないこと
- 礼儀正しい (polite)
- 暗黙的・明示的な礼儀正しさを考慮していること
- 明示的な礼儀正しさ
- クロールするサイトのウェブマスターからの仕様を守る
- 暗黙的な礼儀正しさ
- (仕様になくても)サーバを高頻度で叩かない
robots.txt
- スパイダー(= ロボット)によるアクセスを制限するためのプロトコル (1994-)
- どのページがクロールされるべきで、どのページはされるべきではないのかをアナウンスする
- サーバ側で
/robots.txtファイルを作成する
- サーバ側で
robots.txt の例
searchengineという名前のロボット以外は/yoursite/temp/から始まる URL を訪問してはいけない
User-agent: * Disallow: /yoursite/temp/ User-agent: searchengine Disallow:
クローラの SHOULD 要件
- 分散化されていること
- 複数台のマシンで実行されるように設計されていること
- スケーラブルであること
- マシンを追加することでクロール速度を上げることができるように設計されていること
- 効率的であること
- CPU/ネットワークリソースを使い切れること
- 質の高いページから先にフェッチすること
- 前にフェッチしたページの新しいコピーもフェッチし続けること
- 拡張可能であること
- 新しいデータフォーマットやプロトコルに適応できること
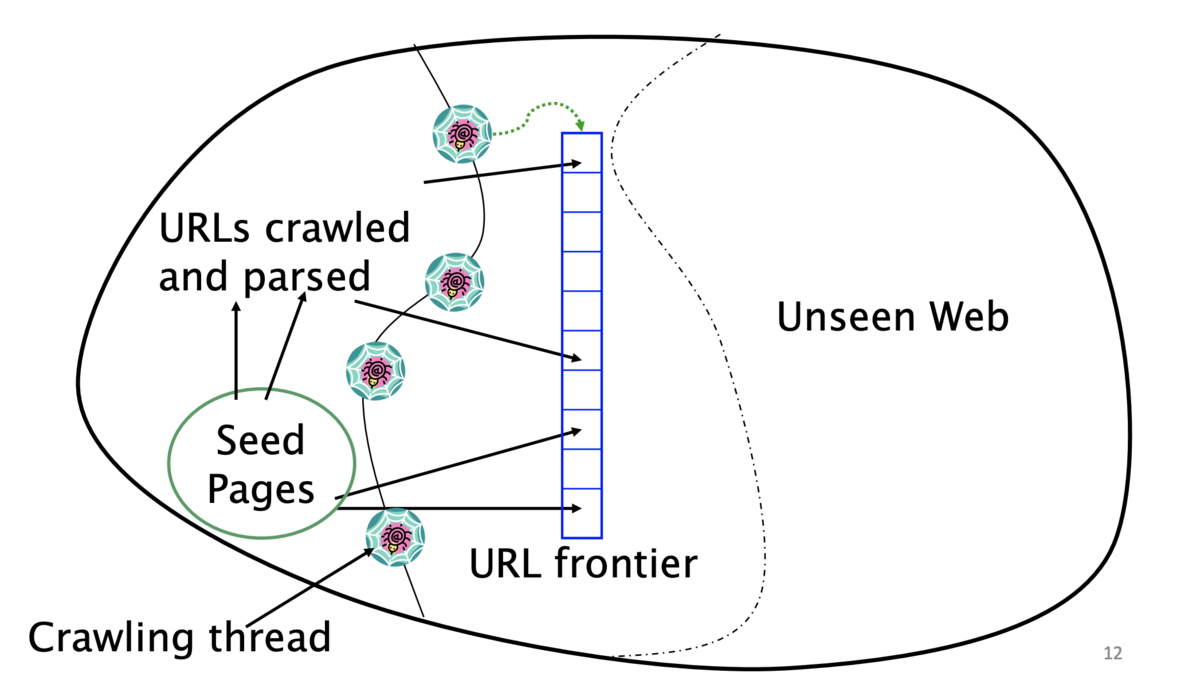
- URL frontier
- 同じホストのページを複数含んでいてもよい
- ただし、同じタイミングでフェッチすることは避けなければならない
- すべてのクローラのスレッドはビジー状態をキープしなければならない
- 同じホストのページを複数含んでいてもよい
クローラのアーキテクチャ
クローラの処理ステップ
- URL frontier から URL を1つ選択する
- その URL をフェッチする
- URL をパースする
- 他の URL を抽出する
- URL がすでに見ているかどうかチェックする
- 見ていなければインデックスに追加する
- 抽出された URL に対して
- フィルタ条件に引っかかっていないか確かめる
- robots.txt のチェックなど
- URL frontier にすでにあるかどうかチェックする
- 重複 URL の排除
- フィルタ条件に引っかかっていないか確かめる
クローラの基本アーキテクチャ
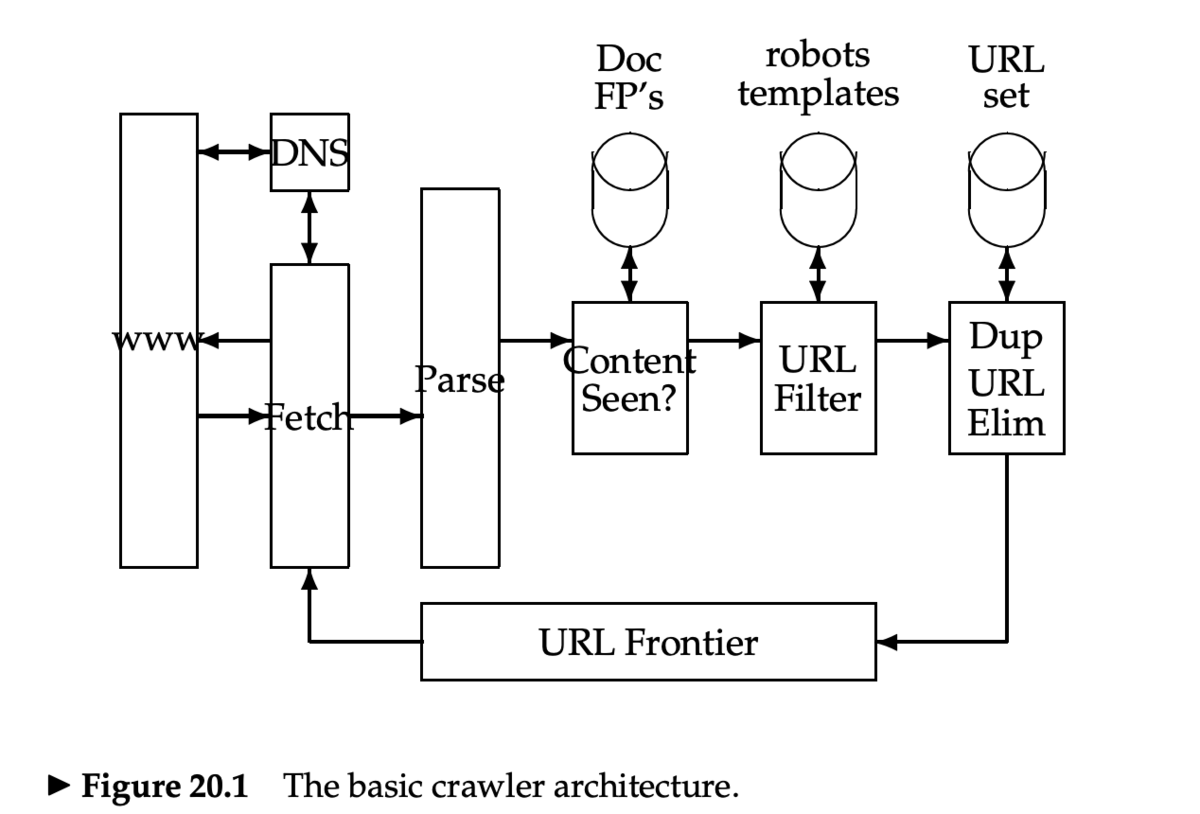
- DNS のルックアップは処理をブロック (blocking) する
- URL 正規化
- URL のパース時に、リンクが相対 URL になっていることがあるので、正規化(展開)する
- 重複ページの判定
- すでに見たページは処理しないようにする
- 文書の fingerprint もしくは shingle を使う
- 次回扱う
- robots.txt
- 1度 robots.txt をフェッチしたら、繰り返しフェッチしないようにする(キャッシュする)
分散型クローラ
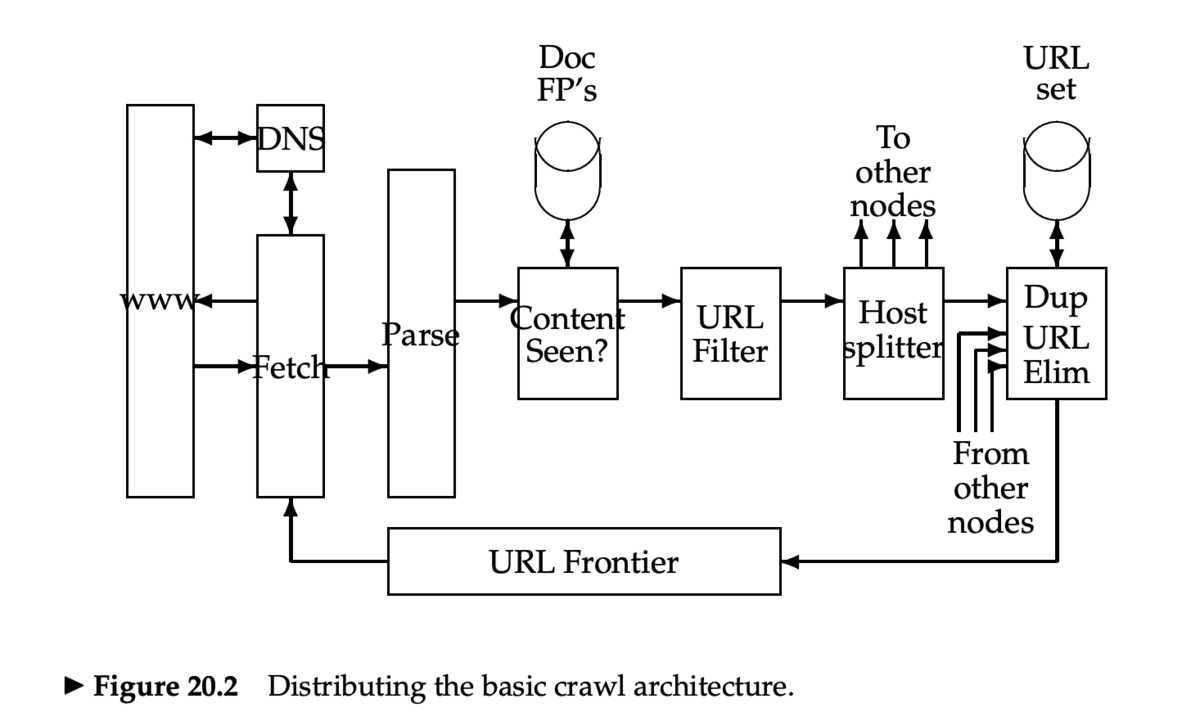
URL frontier
- 2つの主な目標
- Politeness: 頻繁に Web サーバを叩きすぎない
- Freshness: いくつかのページは優先的にクロールする
- ニュースサイトのように、頻繁に更新されるページ
- この2つの目標はコンフリクトする
- たとえば、シンプルな優先度付きキューでは不可能
- 多くのリンクが自身のサイトへのリンクなので、アクセスがバーストする
- 一般的なヒューリスティック:前回のリクエストから時間をおいてアクセスする
Mercator URL frontier
- Mercator クローラ [Heydon et al. 1999]
- 多くの研究や商用のクローラの基礎となったクローラの実装 (Java)
- Mercator のスキームは、2つの FIFO キューを使う
- Front queue: 優先度を管理する
- Back queue: Politeness を強制する
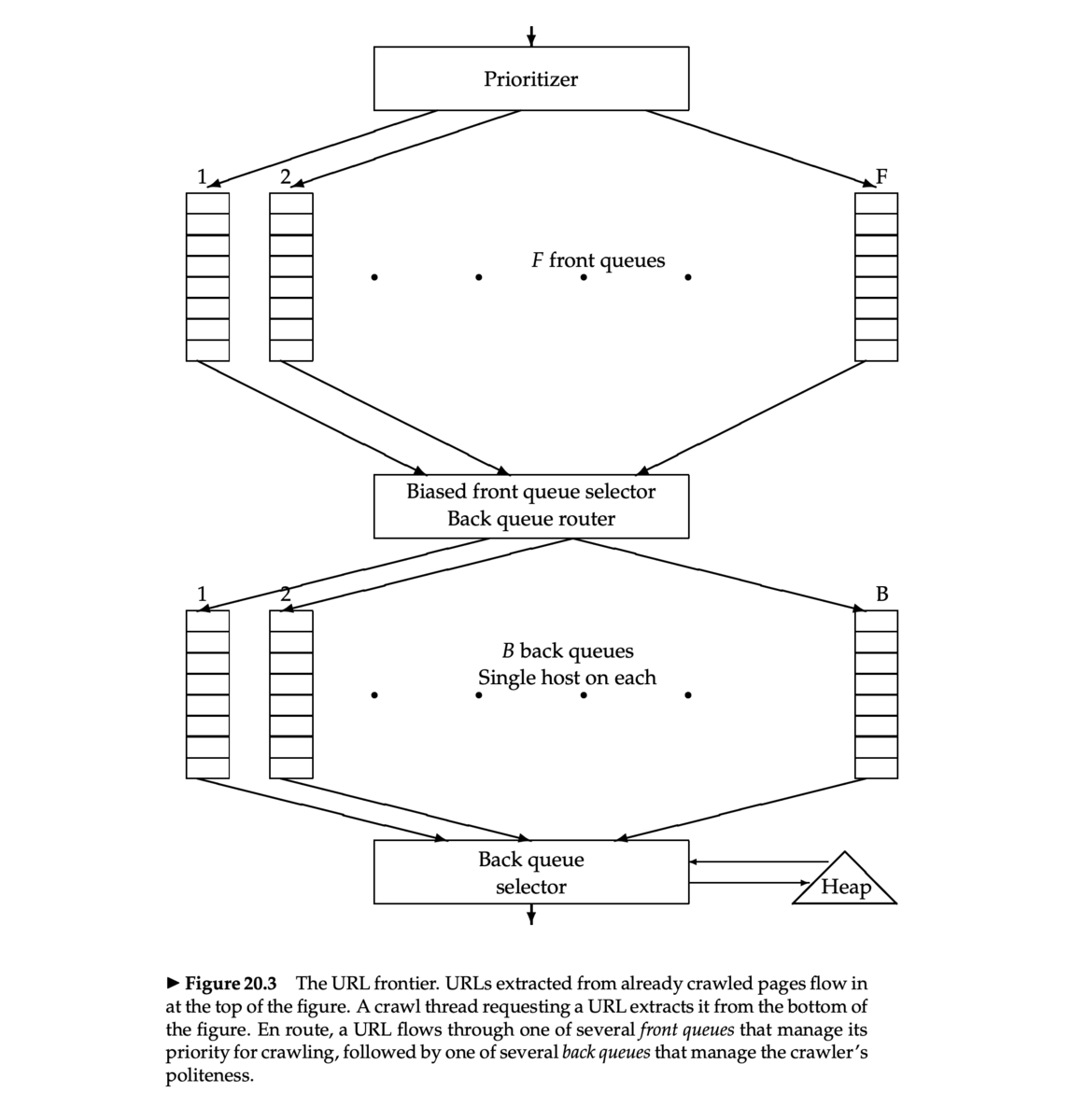
Front queue
- Prioritizer が URL に 1 から F までの優先度を割り当てる
- その URL を、各優先度に対応するキューに append する
- 優先度割当てのヒューリスティック
- 前回のクロール時にリフレッシュレートをサンプルしておく
- アプリケーション依存の方法:サイトの種類(ニュースサイトなど)によって優先度を決める
Biased front queue selector
- Biased front queue selector は、Back queue が URL をリクエストしたとき、その URL を pull するために Front queue を1つ選ぶ
- pull 型なので Back queue がリクエストする
- この選択は優先度でバイアスがかけられたラウンドロビンで行うことができる
- 他のもっと sophisticated な方法を使っても良い
- ランダマイズしてもよい
Back queue
- Back queue はクローリングしているあいだは休まないようにする
- Back queue の数 B で調整(すべてのスレッドがビジーになるように)
- Mercator の推奨設定:クローラスレッド数の3倍
- それぞれの Back queue は1つのホストからの URL のみを含む
- ホスト名から Back queue への対応(マッピング)はテーブルで管理
Back queue heap
- Back queue heap は、1つの Back queue ごとに1つのエントリをもつ
- エントリには、 Back queue に対応するホストが次に叩かれる最も速い時刻を保存
- この時刻は、以下から決定される
- そのホストへの最終アクセス時刻
- 様々な時間バッファのヒューリスティック
Back queue の処理
- クローラスレッドはクロールすべき URL を探す
- Back queue heap のルートを取得
- テーブルをひき、対応する Back queue
qの先頭から URL をフェッチ - Back queue
qが空になったかどうかチェックし、もし空なら Front queue から URLvを pull する- もし URL
vのホストに対応する Back queue がすでにあったら、URLvをそれに append し、別の URL を Front queue から pull し、繰り返す - そうでなければ、
vをqに入れる
- もし URL
qが空でなければ、Back queue heap にそのための新しいエントリを作成する
講義資料
参考資料
Information Retrieval and Web Search まとめ(21): リンク解析
前回はランク学習手法について説明した。今回は、リンク解析について扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の21日目の記事です。
リンク解析の概要
ハイパーテキストとリンク
- 文書のコンテンツ以外のものもスコアリングに取り入れる
- まずそれらのハイパーリンクに注目
- リンクは権威 (authority) をページに与えることを意味するのか?ランキングに役立てることはできるか?
- CERN のホームページからリンクされたページは高エネルギー物理に関するページ?
- 応用範囲
- Web
- SNS
リンク解析と情報検索
- スコアリングとランキング
- リンクベースでのクラスタリング
- トピックによる文書分類
- リンクを分類の特徴量として使う
- 同じ文書を指している文書たちは同じようなテーマである可能性が高い
- クローリング
- 次回扱う
有向グラフとしての Web
- Web はページ内にアンカー (anchor) をもつ
- ハイパーリンク (hyperlink) と呼ばれる別のページへの有向のリンク
- Web はページを頂点、ハイパーリンクを辺とする有向グラフとみなせる
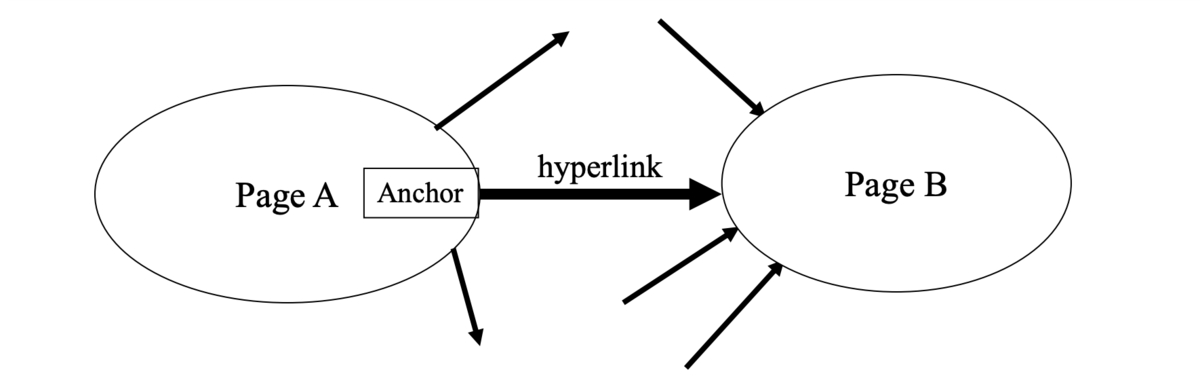
PageRank
引用解析
- 論文などの学術文献の引用関係を解析
- 同じ文献を引用している文献同士は関連している
- PageRank の基礎となった
学術文献と Web との違い
- Web は数百万の書き手がいて、それぞれが違う興味を持っている
- スパムが多い
- 検索エンジンがリンクをランキングに使い始めると、リンクスパムが増える
- お互いにリンクを張り合うリンクファーム (link farm) も存在する
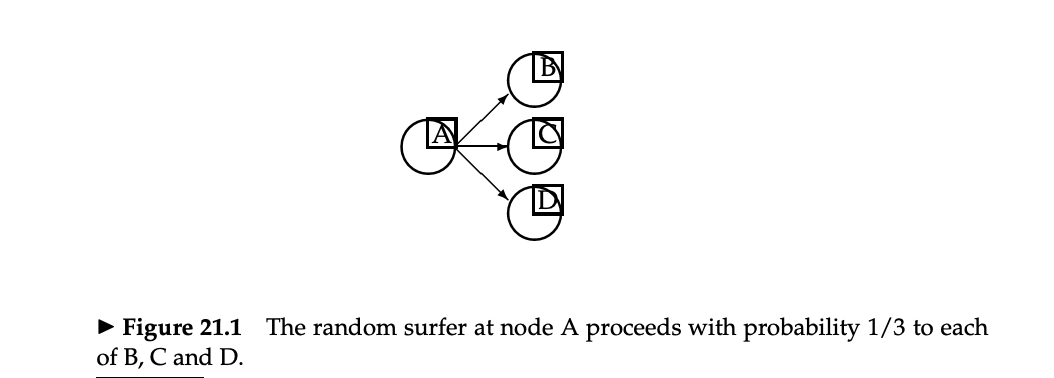
PageRank スコアの基本的な考え方
- ユーザはページ間をランダムウォークすると仮定する
- ランダムなページから開始
- 各ステップで、ユーザはページから出ているリンクの中から等確率で1つ選んで遷移する
- 長い時間のあと、各ページはある一定の訪問率 (vist rate) に落ち着く
- これをそのページのスコアとする
テレポート
- しかし、この方法には問題がある
- dead-end (リンクを持たない Web ページ)がたくさんある
- ランダムウォークを継続できない(スタック (stuck) する)
- 訪問率が意味を持たなくなる
- dead-end に行き当たったら、次はランダムなページに遷移する
- スタックしなくなる
- また、dead-end でないページでも、ある確率(たとえば 10%)の確率でランダムなページに遷移する
- この確率は PageRank のパラメータであり、テレポート確率 (teleportation probability) と呼ぶ
- Web のユーザがどこか他のページに行く挙動をシミュレートしている
- すべてのページに訪問率が存在するようになる
- この訪問率をどうやって計算するか?
マルコフ連鎖
- マルコフ連鎖 (Markov chain) は n 個の状態 (state) と、 n×n の遷移確率行列 (transition probability matrix) P からなる
- 各ステップで、状態のうちのどれか1つの中にいる
は、状態 i から状態 j へ遷移する確率を表す
も認められる
- すべての i に対して
マルコフ連鎖の例
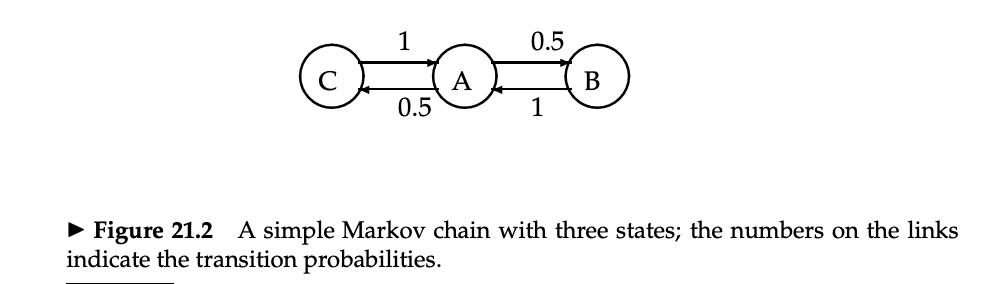
エルゴード的マルコフ連鎖
- エルゴード的マルコフ連鎖 (ergodic Markov chain) は、各状態での長期的な訪問率がユニーク(一意)である
- エルゴード的:周期的なパターンがない
- テレポートによりエルゴード性が満たされる
- 長期的には、この訪問率に比例して各状態に遷移する
- どこから開始するかには依存しない
確率ベクトル
- 確率(行)ベクトル
は、どの状態にいるかを示す
(0, 0, ..., 0, 1, 0, ..., 0)(i 番目の要素だけ 1)のとき、状態 i にいる- より一般には、確率ベクトル
を意味する
- このステップでの確率ベクトルが
- 行列 P が、状態 i からの遷移確率を示していることを思い出すと、次の状態は
と表せる
- その次は
、更にその次は
...
- これは収束するか?
- これを計算して調べるのがべき乗法 (power method, power iteration)
- 初歩的な方法
- 訪問頻度が一定の閾値以下に「落ち着く」までシミュレートを繰り返す
- その次は
- 確率行ベクトルの定常状態を
と書くことにする
- これは定常状態なので、
- これは定常状態なので、
- この方程式を解くと a を求めることができる
Web グラフの例

- dead-end (sink) となるページ(状態 2)からは、ランダムなページに遷移するように修正する

- テレポートの効果を入れる

- べき乗法によるイテレーションを行う

HITS
講義資料
参考資料
Information Retrieval and Web Search まとめ(20): ランク学習
前回は Word2vec, BERT などの単語埋め込み手法と、それらの情報検索への応用について説明した。今回は、ランク学習について紹介する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の20日目の記事です。
情報検索のための機械学習
- これまでに検索における文書のランキング手法をいくつか見てきた
- コサイン類似度、BM25...
- また、教師ありの機械学習を使った文書分類(クラス分類)の方法も見てきた
- ロッキオの方法、kNN、決定木...
- 文書のランク付けにも機械学習を使えないか?
- "machine-learned releance", "learning to rank" として知られている
歴史
- 検索ランキングのための機械学習はアクティブに研究されてきた
- また、この10年で主要な検索エンジンにデプロイされている
- 過去の研究
- Wong, S.K. et al. 1988. Linear structure in information retrieval. SIGIR 1988.
- Fuhr, N. 1992. Probabilistic methods in information retrieval. Computer Journal.
- Gey, F. C. 1994. Inferring probability of relevance using the method of logistic regression. SIGIR 1994.
- Herbrich, R. et al. 2000. Large Margin Rank Boundaries for Ordinal Regression. Advances in Large Margin Classifiers.
- 初期の研究はそれほどうまくいっていなかった
- 訓練データが少なかった
- 特に実世界のデータ
- クエリログ、適合性判定のデータを集めるのは大変
- 機械学習手法もまだ発展していなかった
- 情報検索の問題への適用が不十分だった
- 特徴量が十分ではなかった
- 訓練データが少なかった
機械学習の必要性
- 現代的な(Web の)システムは大量の特徴量を扱う
- ターム頻度などの古典的な特徴量だけではなく、ページ中の画像の数、リンクの数、PageRank、URL、更新日時、ページの表示速度...
- Google は 2008 年には 200 以上の特徴量(シグナル)を使っており、今日では 500 以上になっているだろう
ランク学習
- クラス分類はアドホック検索への適切なアプローチではない
- ランキング問題では、文書が他の文書に対してよいかどうかを議論する
- よさの絶対的な尺度は必要ない
- ランク学習 (learning to rank)
- 以下のような適合性のカテゴリの集合 C が存在すると仮定する
- C のすべてのカテゴリ
には全順序がついている (totally ordered)
- (これは順序付き回帰の問題設定と同じ)
- C のすべてのカテゴリ
- 以下のような文書とクエリのペア
(d, q)からなる訓練データを仮定する(d, q)は特徴量ベクトル
- 以下のような適合性のカテゴリの集合 C が存在すると仮定する
検索ランキングのためのアルゴリズム
- SVM (Vapnik 1995) のランキングへの適用:Ranking SVM (Joachims 2002)
- ニューラルネット:RankNet (Burges et al. 2006)
- Tree Ensemble
- ランダムフォレスト (Breiman and Schapire 2001)
- Boosted Decision Tree
- 2010 年の Yahoo! Learning to Rank Challenge ではすべてのトップチームが Tree Ensemle の手法の組み合わせを使った
Yahoo! Learning to Rank Challenge
- [Chapelle and Chang, 2011]
- 以下のような Yahoo! Webscope のデータセットを使って行われた
- クエリ数:36,251
- 文書数:883k
- 特徴量:700種類
- ランキング:5段階
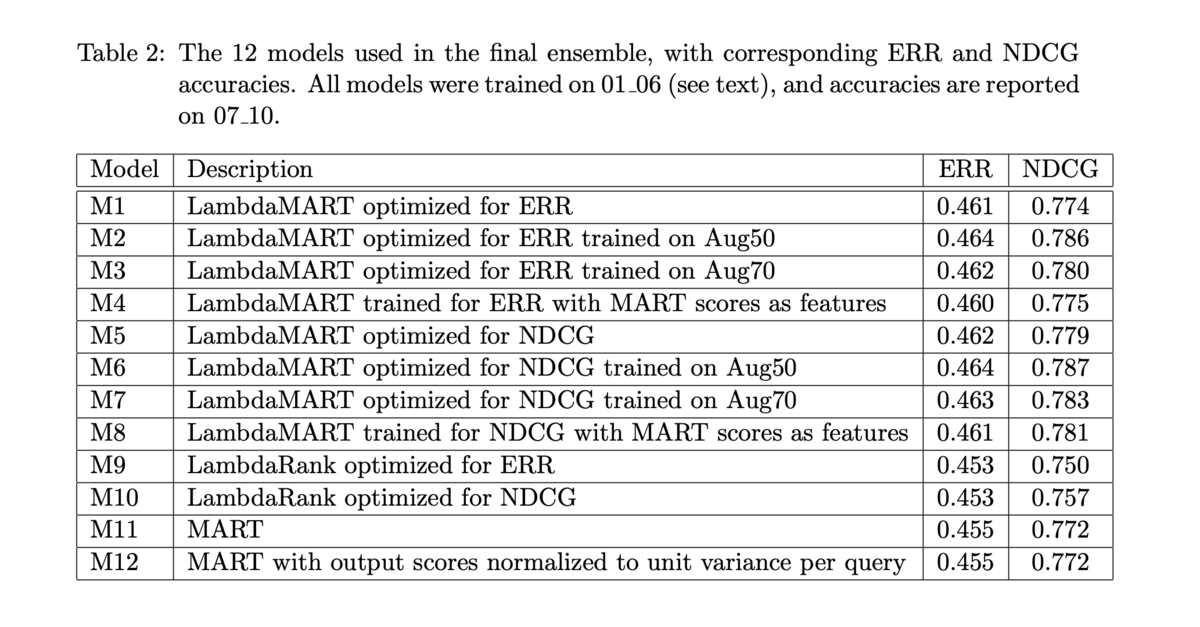
- 優勝したモデル (Burges et al. 2011) は 12 のモデルの線形結合だった:
- 8 つの Tree Ensemble (LambdaMART)
- 2 つの LambdaRank ニューラルネットワーク
- 2 つのロジステック回帰
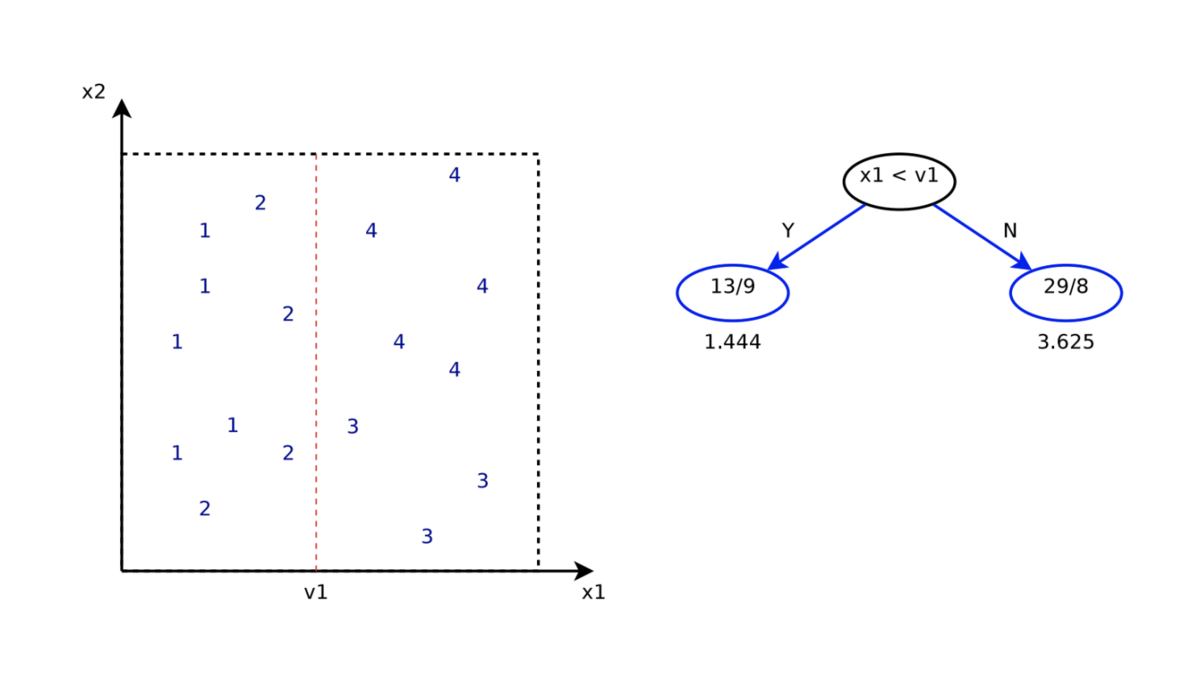
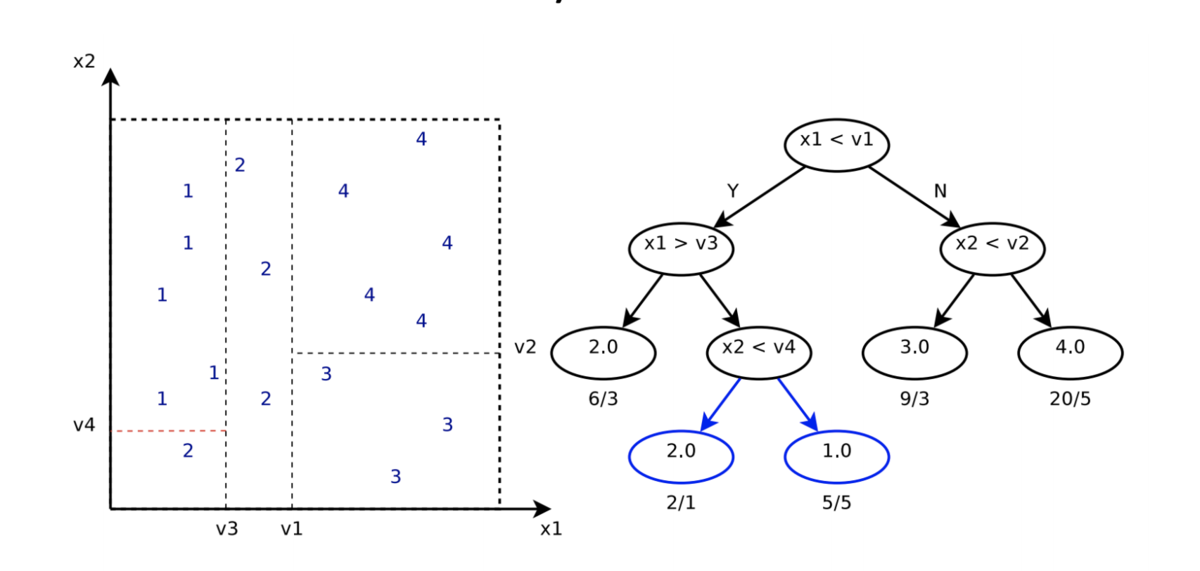
回帰木
- 回帰木 (regression tree) は、実数を予測できる決定木
- 葉ノードには、その葉ノードに含まれるすべてのサンプルの平均値 (mean) を保持する
- 分割規準:標準偏差 (standard deviation; SD) の最小化
- 学習時には、分割する変数
と、その変数上での分割点
を探索する
- それらは予測誤差
を最小化するように選ぶ
- それらは予測誤差
勾配ブースティング
ブースティングのモチベーション
- Q:「独立な弱い (weak) 分類器を組み合わせて、高い精度の分類器を構築できるか?」
- 古典的なアプローチ: AdaBoost
- すべての木の重み付きの投票で分類する
ブースティングによる関数の推定
- ほしいもの:損失関数
の期待値を最小化する、以下のような関数
- ブースティングでは、
を以下のような形で近似する
は
でパラメータ化された関数
は重み係数
- 関数のパラメータはイテレーションにより訓練データにフィットさせる
勾配ブースティングの学習
- 勾配ブースティング (gradient boosting) は、任意の微分可能な損失関数に対して関数
を推定できる
- 関数
- ただし
は「疑似残差 (pseudo-residual)」であり
Gradient Boosted Regression Tree (GBRT)
- Gradient Boosted Regression Tree (GBRT) は、この勾配ブースティングのアプローチを回帰木 (regression tree) に適用する
- それぞれの回帰木は通常 1-8 の分割しか持たない
- GBRT の学習
- 最初に、すべての
- 訓練データの誤差を最小化する定数
- 木のルートノードの値
を探索する
- 最小二乗法によりルートノードを分割する
- さらに誤差を最小化する木を追加する
- 最初に、すべての
MART
- Multiple Additive Regression Trees (MART) [Friedman 1999]

RankNet
- RankNet [Burges et al. 2005] はニューラルネットによる ranker
- モデルパラメータ w に対して微分可能な関数
をスコア関数とする
が
- クエリ q に対して、各文書の組
に対するランキングのクラスの確率
が
はシグモイド関数の傾きを決めるパラメータ
- 損失関数 C はクロスエントロピー損失
は実際の確率(各カテゴリに対して0/1で与えられる適合性の判定)
- ただし、
RankNet の Lambda
- これを使って損失関数の
に対する微分は以下のようにできる
- この式を使って重み
は、文書
- クエリ-文書ベクトル
の総和
を定義する
- この
- (a) は最適なランキング
- (b) は 10 のペアワイズ誤差をもつランキング
- (c) は 8 のペアワイズ誤差をもつ
- 青の矢印は最後の文書の勾配
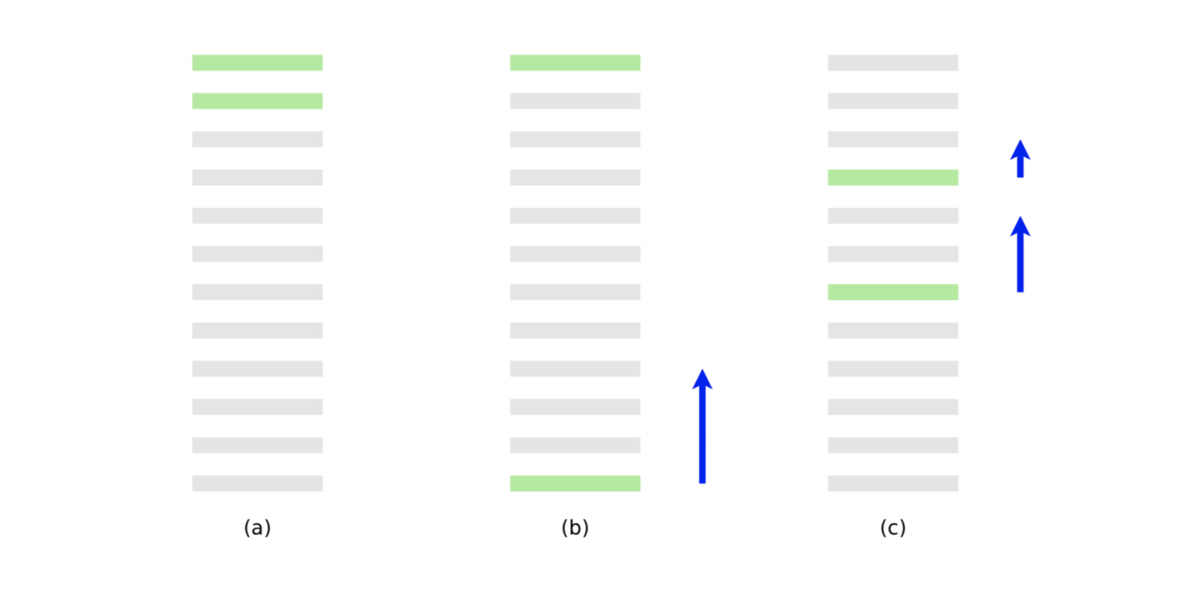
- 青の矢印でペアワイズ誤差は減り、2値の適合性評価指標は改善する
- しかし、NDCG や ERR のような、上位により大きい重みをつける指標では、以下の赤の矢印のような勾配のほうが望ましい
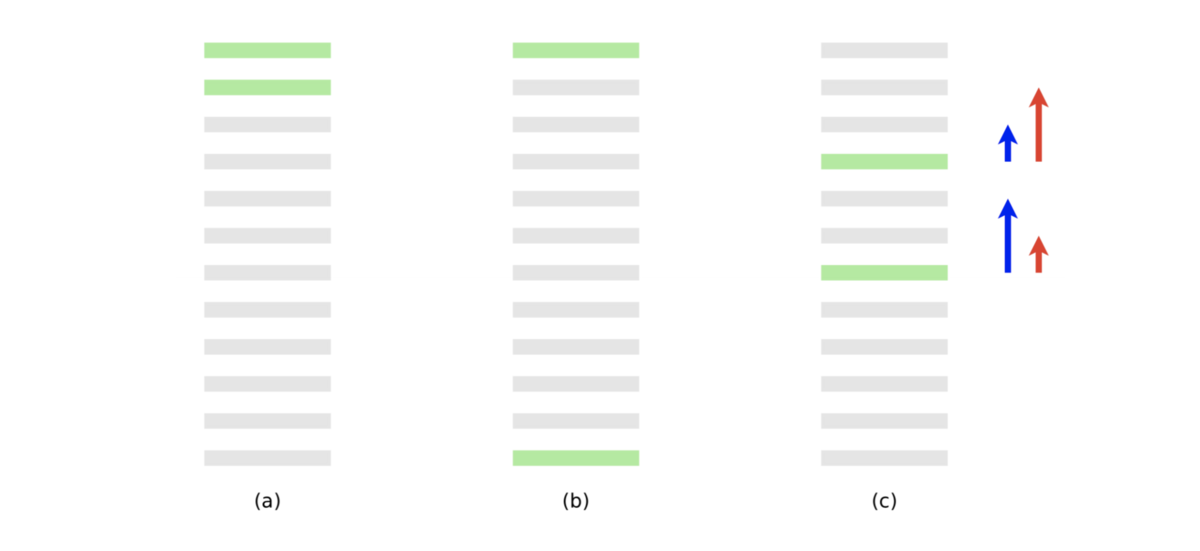
LambdaRank
- LambdaRank [Burges et al. 2006]
- RankNet のようなペアワイズ誤差ではなく、NDCG の効果を入れる
- アイデア:
を
倍する
は、文書
(NDCG の変化)を使って
を以下のようにする
- Burges et al. は、この変更によって NDCG に対して十分に最適化できることを示した
LambdaMART
- LambdaRank は勾配をモデル化している
- MART は勾配(勾配ブースティング)によって学習できる
- この2つを組み合わせたのが LambdaMART [Burges 2010]
- MART に LambdaRank の勾配を入れた

- 前述の通り、Yahoo! Learning to Rank Challenge で LambdaMART (と他のモデルとの線形結合)を使ったチームが優勝 [Burges et al. 2011]
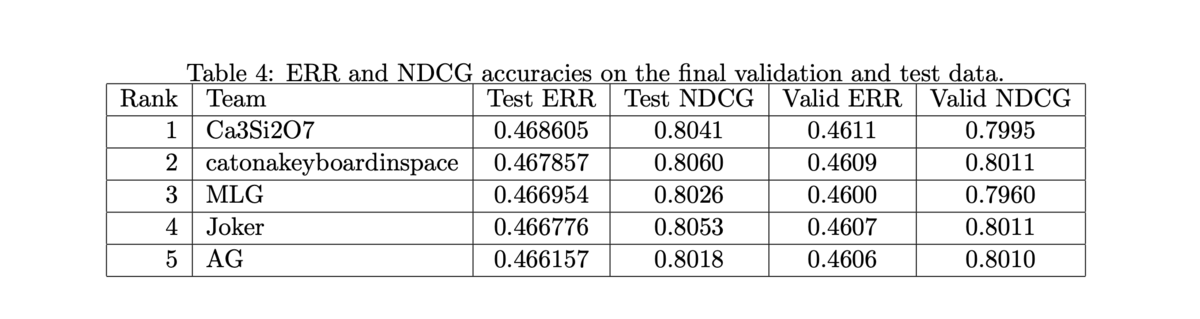
- 結合されたモデルと、それぞれの単体でのスコアは以下の通り
- 多くのモデルを組み合わせなくても十分に高い性能を示す
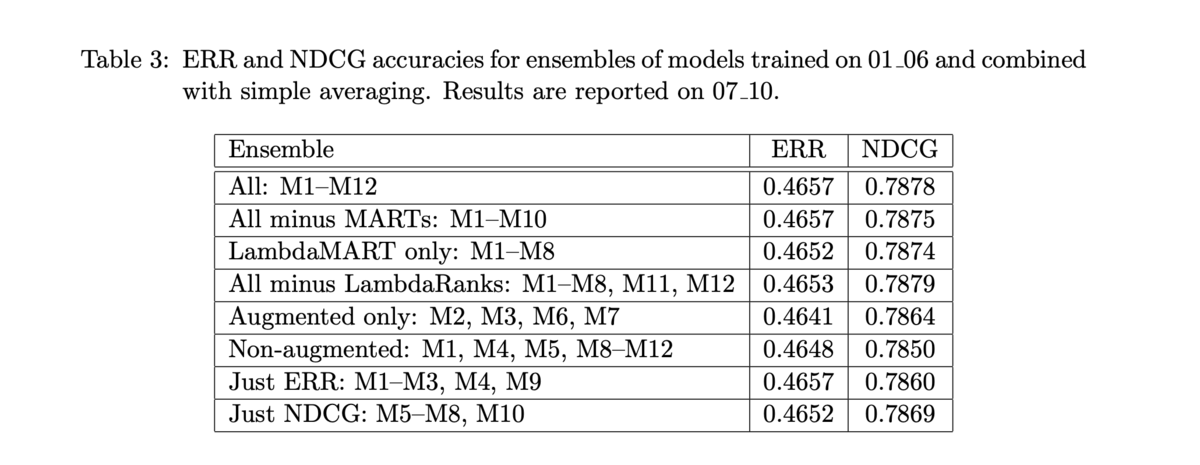
- 他のチームも僅差
- ペアワイズの Logistic Rank もいい結果を残している
講義資料
参考資料
- IIR sections 6.1.2-6.1.3
- IIR section 15.4
- Discriminative models for information retrieval (Nallapati 2004)
- Adapting ranking SVM to document retrieval (Cao et al. 2006)
- A support vector method for optimizing average precision (Yue et al. 2007)
- LETOR benchmark datasets
- C. J. C. Burges. From RankNet to LambdaRank to LambdaMART: An Overview. Microsoft TR 2010.
- O. Chapelle and Y. Chang. Yahoo! Learning to Rank Challenge Overview. JMLR Proceedings 2011.
- Why is machine learning used heavily for Google's ad ranking and less for their search ranking? What led to this difference? - Quora
- Raw example of xgboost for ranking with LambdaMART
- Statistical Consulting: Multiple Additive Regression Trees (MART)
Information Retrieval and Web Search まとめ(19): 分散表現
前回は決定木によるテキスト分類について説明した。今回は、情報検索での分散表現の利用について解説する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の19日目の記事です。
単語の表現
- ユーザの検索意図をどうやって頑健にマッチするか?
- クエリを(字面通りではなく)理解 (understand) したい
- クエリが
Dell notebook battery sizeだったとき、Dell laptop battery capacityに言及している文書にマッチさせたい - クエリが
Seattle motelだったとき、Seattle hotelを含む文書にもマッチさせたい
- クエリが
- キーワードベースの情報検索システムでは難しい
- スペル訂正、ステミング、小文字への正規化 (case folding) 役立つときもあるが限定的
- クエリを(字面通りではなく)理解 (understand) したい
- クエリ拡張 (query expansion)
- 単語の類似度を使うことができる
- 手で構築されたシソーラス(類語辞書)
- 単語類似度の尺度
- 大規模なコレクションから計算されたもの
- Web などのクエリログから計算されたもの
- 単語の類似度を使うことができる
- 文書拡張 (document expansion)
- Web ページにおけるアンカーテキスト (anchor text) でシノニムを解決できるかもしれない
- Web ページによっては使えないこともあるし、ハイパーリンクのないコレクションでは不可能
- Web ページにおけるアンカーテキスト (anchor text) でシノニムを解決できるかもしれない
検索ログによるクエリ拡張
- 文脈のないクエリ拡張は失敗する
wet ground~wet earthなので、ground-->earthと拡張すると...ground coffee(挽いたコーヒー豆) !=earth coffee
- 同じユーザの context-specific なクエリ書き換えのログから学習することはできる
Hinton word vectorHinton word embedding- この文脈では
vector~embedding
シソーラスの自動生成
- 文書のコレクションを解析することでシソーラスを自動生成することができる
- シンプルなものだと、タームの共起行列から計算する方法がある

タームの関係性の表現
- 標準的な符号化方法だと、各タームはそれぞれ1つの次元に対応する
- 異なるタームは関係がないものとして扱われる
- たとえば、
hotelを 3 つ含む文書と、motelを 1 つ含む文書があったとして、それらの文書ベクトルは直交するので内積をとっても 0 になってしまう
- Query translation model [Berger and Lafferty (1999)]
- 基本的な情報検索のスコアリングは
- スコアリングを
と修正して、W のパラメータを学習する
- しかし、その行列 W が疎であるという問題は解決しない(W の次元は
以上)
- 基本的な情報検索のスコアリングは
- 解決策:低次元密ベクトル
- アイデア:固定長の低次元密ベクトルに、最も重要な情報を詰め込む
- 通常、 25 - 1000 次元
- 高次元の疎なカウントベクトルから、低次元の「単語埋め込み (word embedding)」へと変換する
- 古典的な方法:潜在意味インデキシング/潜在意味解析 (latent semantic indexing/analysis)
ニューラル埋め込み
- 単語を密ベクトルで表現する
- そのベクトルは、その文脈で登場する他の単語を予測できるようなものが選ばれる
- 他の単語もベクトルで表現されている
ニューラルネットワークと単語埋め込み
基本的なアイデア
- 中央の単語 (center word)
から、周辺の単語 (context word) を予測するモデルを定義する
- この上に損失関数を定義し、大規模なコーパスからモデルを学習する
- t の位置をずらしながら学習していく
- この損失関数を最小化するような単語のベクトル表現が学習される
低次元の単語ベクトルの学習
- 逆伝搬誤差 (back-propagating error) によってベクトル表現を学習 [Rumelhart et al., 1986]
- 古い方法
- ニューラル確率言語モデル [Bengio et al., 2003]
- NLP from Scratch [Collobert & Weston, 2008]
- 非線形かつ遅い
- Word2vec(よりシンプルで速いモデル) [Mikolov et al. 2013]
- バイリニア (bilinear) で速い
- GloVe(matrix factorization と接続) [Pennington, Socher, and Manning 2014]
- バイリニア (bilinear) で速い
- ELMo、ULMfit、BERT(トークンごとのベクトル表現、Deep contextual word representation)
- 現在の stage of the art
Word2vec
- Word2vec は、ある単語 (center word) とその周辺の単語 (context words) を予測するモデル
- 2つのアルゴリズムがある
- Skip-gram (SG)
- (ポジションに対して独立な)ターゲットの単語から周辺の単語を予測する
- Continuous Bag of Words (CBOW)
- bag-of-words の文脈から、ターゲットの単語を予測する
- Skip-gram (SG)
- 訓練方法
- 階層的ソフトマックス (hierarchical softmax)
- ネガティブサンプリング
- ナイーブソフトマックス (naive softmax)
Skip-gram
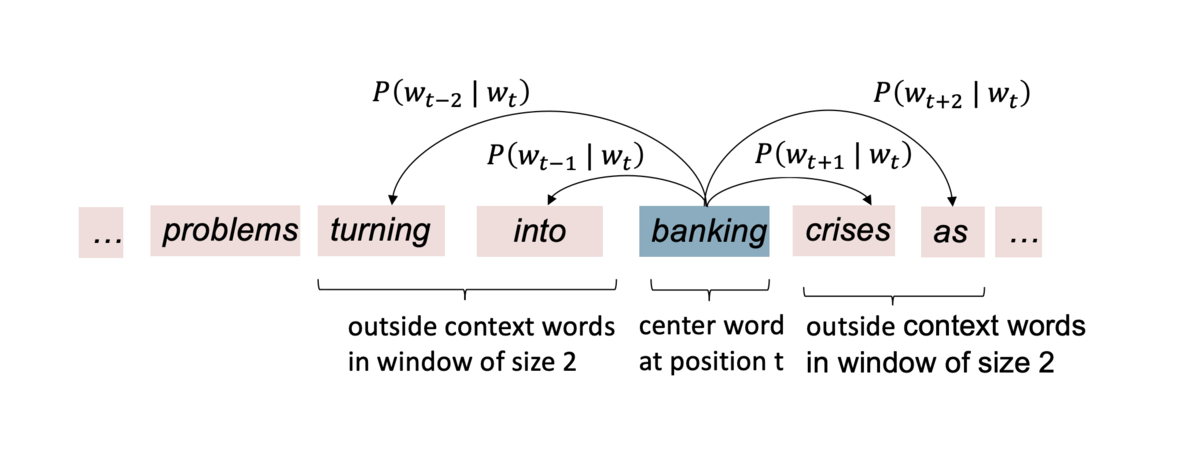
- Skip-gram で
を計算する例
bankingが center word- ウィンドウサイズは 2
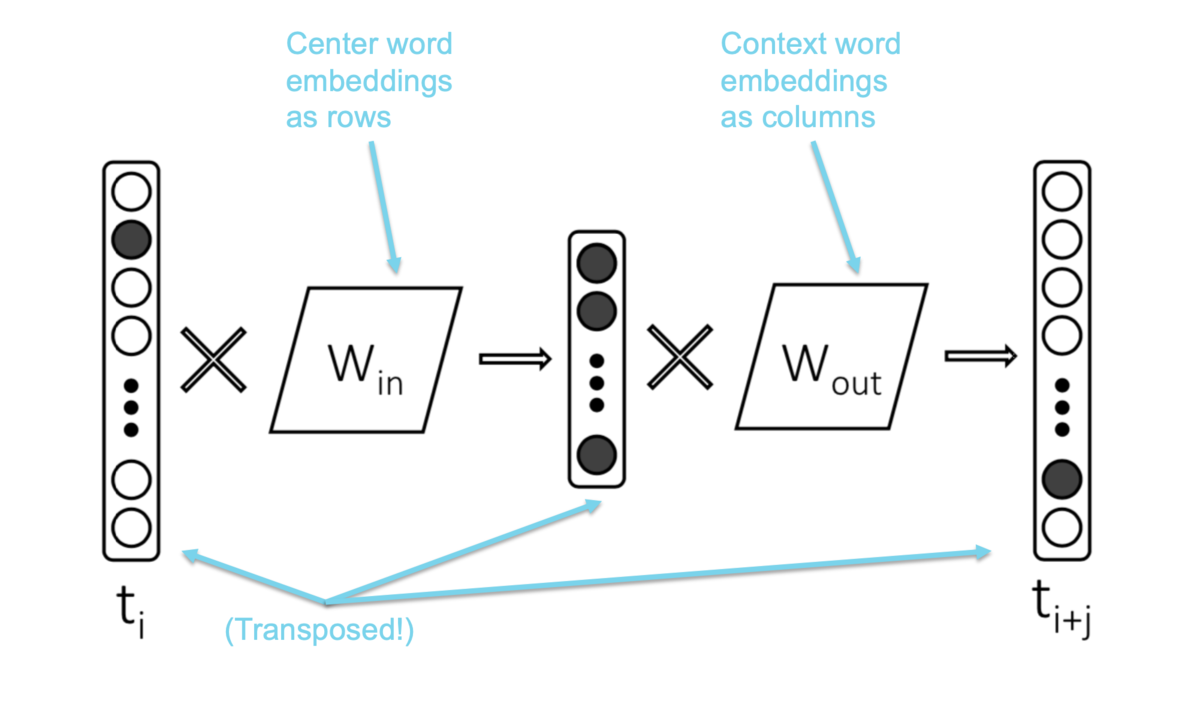
- 2つのパラメータ行列
は center word の埋め込みとなる(行が単語を表す)
は context word の埋め込みとなる(列が単語を表す)
Word2vec の線形性
- Word2vec による単語のベクトル表現は、類似度と類似度の次元を、とてもうまくエンコードする
構文的な関係性
意味的な関係性 [Semeval 2012 task 2]
情報検索への応用
- 分散表現の情報検索への応用は、まだ始まったばかり
- Google RankBrain
- Google Turning Its Lucrative Web Search Over to AI Machines - Bloomberg
- 検索結果のリランキングシステム
- 3番目に大きいランキングシグナル
- SIGIR Neu-IR workshop (2016-)
- Google RankBrain
ニューラルネットによるリランキング
- ニューラルネットを教師ありのリランカーとして使う
- クエリと文書それぞれの埋め込みネットワークがあるとする
- また、クエリと文書とその適合度の組
(q, d, rel)のデータがあるとする - ニューラルネットワークを教師あり学習し、
(q, d)の組の適合度を予測する
Dual Embedding Space Model (DESM)
- Nalisnick, Mitra, Craswell & Caruana. 2016. Improving Document Ranking with Dual Word Embeddings. WWW 2016 Companion.
- Mitra, Nalisnick, Craswell & Caruana. 2016. A Dual Embedding Space Model for Document Ranking.
- BM25 の "aboutness" のアイデアから作られたモデル
- aboutness を表すのは、タームの繰り返しだけではない
- クエリタームと、文書に出現するすべてのタームとの関連性 (relationship) も aboutness を表す


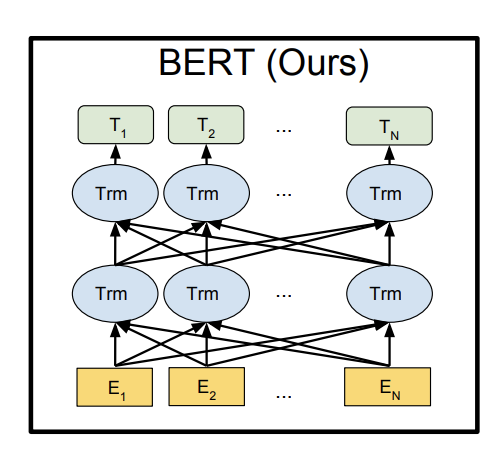
BERT
- BERT: Devlin, Chang, Lee, Toutanova (2018)
- Transformer ベースの DNN
- トークンごとの表現を(コンテキストありで)出力する
- クエリや文書の表現も同様に作れる
- もしくはクエリと文書を同時に埋め込み、適合スコアを求める
- 非常に効果的