こんにちは、iOSエンジニアの前田(@naoya_maeda ) 、早川(@hykwtmyk )、三好、岐部(@beryu )、Androidエンジニアのみかみ(@mono33 )です。
2024年3月22-24日に渋谷で開催されたtry! Swift Tokyoに、タイミーもGOLDスポンサーとして協賛させて頂きました。
特に気になったセッション(前田編)
僕が特に気になったセッションは、リルオッサさんによる「SF Symbolsの芸術的世界:限りない可能性を解き放つ」です。
リルオッサさんは、iOSDC Japan 2022でもSF Symbolsアートの可能性 についてお話されており、今回のセッションでは、アニメーションを交えたダイナミックなSF Symbolsアートを紹介されていました。
SF Symbolsは、Appleが提供するアイコンおよびシンボルのセットです。
WWDC 2019で初めて開発者に公開され、iOS 、macOS、watchOSで使用可能になりました。
SF Symbolsは、定期的にアップデートが行われ、新しいアイコンやシンボルの追加、パフォーマンスの改善が行われています。
SF Symbols 5では、5000を超えるアイコンおよびシンボルが提供されています。さらに、わずか数行のコードでアニメーションエフェクトを実現することができるようになりました。
「SF Symbolsの芸術的世界:限りない可能性を解き放つ」では、さまざまなアイコンやシンボル、そしてSF Symbols 5で追加されたアニメーション機能をフルに活用し、ダイナミックなSF Symbolsアート作品が紹介されています。
VIDEO www.youtube.com
普段何気なく使用しているSF Symbols達が組み合わされていき、一つのSF Symbolsアート作品になる様は圧巻でした!
また、SF Symbols 5には、様々なアニメーションエフェクトが用意されていると知ることができ、タイミーアプリ内でもSF Symbolsを活用していきたいと感じました。
今回ご紹介しきれなかった作品はGitHubで公開されているので、ぜひ一度ご覧ください!
github.com
ご登壇資料
www.docswell.com
特に気になったセッション(早川編)
今回、自分が気になったセッションは「コード署名を楽しく乗り切る方法 」です。
このセッションではCertificate、Provisioning Profile、Application Identifierなど、アプリをリリースする上で必要なコード署名の要素を分かりやすくパズルに見立てて解説していました。
また、パズルに見立てることによってどこにエラーが起きているのかが分かりやすくなり解決するための要素の推測も容易になったかなと思います。
下の図で言うとProvisioning ProfileはCertificateとは問題なく結びついていますが、Application Identifierと正しく結びついていないためエラーが起きています。
解決するには「Provisioning Profileに結びついているApplication Identifierと一致するようにアプリ側のApplication Identifieを設定しなおす」か、「Provisioning Profileをアプリ側に設定されているApplication Identifierに合わせて作成しなおす」かになります。
各要素をパズルのピースに見立てることで、相互の結びつきが視覚的に解像度高く理解できました。
登壇者のJosh Holtz さんの発表内容も相まってコード署名を楽しく感じることができました笑
特に気になったセッション(みかみ編)
特に印象に残ったセッションは「マクロをテストする」です。今回のtry! Swiftでも注目を集めていたTCA を開発する、Point-Free のStephenさんとBrandonさんによる発表です。
github.com
マクロはSwift 5.9から導入されたコンパイル時にソースコードの一部を生成する機能です。主にボイラープレートを減らすことを目的に利用されます。iOSアプリ開発の世界ではSwiftUIのプレビューを簡潔に行う「#Preview」や新しいデータ永続化のフレームワークであるSwiftDataのモデル定義を簡略化する「@Modelマクロ」などの標準のマクロが数多く用意されています。
マクロは有益ではあるもののマクロによって生成されるコードが多ければ多いほどエラーが発生する可能性は高まります。特にマクロを実装する場合は生成されるコードも対象に、Swiftの文法のあらゆるエッジケースを考慮して多くのテストを行うことが望ましいです。
しかし、マクロのテストも多くの課題があります。例えばマクロで生成されたコードのエラーや警告がXcode上からわかりにくく、 Apple標準のマクロのテストヘルパーの文字比較の判定がシビアでフォーマットなどの本質的ではない部分でテストが落ちてしまうという問題があります。また、マクロの実装が変わった場合はテストを修正する必要がありメンテナンスも大変です。
そこでPoint-Freeがswift-macro-testing というテストライブラリを公開しています。swift-macro-testingは検証したいマクロのソースコードをassertMacro()に書き込むだけでどのように展開されるかを自動でテストコードに反映します。
途中でライブデモがあったり、黒魔術的に生成されるテストコードを披露されたりとなんとなく会場も賑わっていた気がします。Androidにおいて自動生成を行うコードはたまに書くのですが、自動生成のコードをテストするというのは個人的に盲点で面白いなと思いました。
特に気になったセッション(三好編)
今回気になったセッションは、平和に大規模なコードベースを移行する方法 です。
数あるセッションの中では、割と実用的ですぐに活用できるような内容でした。
セッション資料はこちら
drive.google.com
破壊的変更を避ける方法
デフォルトパラメータを利用
メソッドを拡張するときに、パラメータを増やすとそれを利用する側すべての修正が必要になる
デフォルトパラメータを利用することで、利用する側の変更なく機能拡張することができる
protocol extensionを利用
プロトコルのメソッドを増やすと、それに準拠したclassやstructではそのメソッドを必ず実装する必要がある
protocol extensionを利用し、デフォルトの実装を定義することで、利用する側は変更なく機能拡張することができる
@availableの利用
命名変更も破壊的変更になるため
Diagnosticのwarningを利用
enumの利用
caseが増えると、利用側でdefault実装がない場合変更が必要になる
non-frozen enumだと、@unknown defaultの定義が必要なので、破壊的変更は避けられる
しかし、non-frozen enumは開発者に提供されておらず利用できない
enumのcaseそれぞれをstatic letで利用できるようにする
Disfavoured Overload
@_disfavoredOverloadを使う
デフォルトパラメータを減らすなど
機能削減での破壊的変更を避ける目的で使えそう
Finding Problem
swift package diagnose-api-breaking-changes [ブランチ名]
上記コマンドで、指定したブランチの間で破壊的変更があるか教えてくれる
いつ破壊的変更を行うのか
技術的負債とユーザーのイライラを天秤にかけた際に大きな偏りが生まれたとき
@_disfavoredOverload等存在自体知らなかったので、とても勉強になりました。
来年の開催すると思うので、ぜひ皆さんも参加してみてください。
特に気になったセッション(岐部編)
try! Swiftは4回目(2016,2018,2019,2024)の参加でした(2017年の記憶が曖昧なので、5回目かもしれない…)。
どのセッションも有意義でしたが、私は特に「Accessibility APIを使ってアプリケーションを拡張する」のセッションが非常に興味深く、サンプルアプリまで作りました。
1分にまとめたショート動画を用意したのでご覧ください。
VIDEO
時間の関係で動画中では詳細に触れていませんが、Accessibility APIを通して取得できる AXUIElement インスタンスには大きな可能性を感じました。このクラスのインスタンスには起動中の全アプリについての以下のようなウィンドウ情報が詰まっています。
他のアプリのUIに自分のアプリが直接的に作用できるこの考え方は、Sandboxのcapabilityを取り除けるmacOSならではでとても面白いと感じました。
実際にユーティリティアプリ作る際は、以下のような手順で行いました。
Xcodeプロジェクト新規作成、macOSアプリを選択
まずはスライドにある設定を実施
ContentViewを開いて雑に実装
他ウィンドウの情報を埋める構造体と配列
他ウィンドウの情報を集めるメソッド
指定したウィンドウをアクティブにするメソッド
ウィンドウの背景を透明にするView
ホットキーを監視するメソッド
これらを組み合わせて完成
以下のGitHubリポジトリで公開してあるので、ぜひ触ってみてください。
github.com
最後に
try!Swiftは世界中からiOSエンジニアが集まるイベントなので久しい友人に会えるのはもちろん、タイミーのエンジニアはフルリモートで働いているので普段WEBカメラ越しにしか話していない同僚とも対面で会話できて非常に楽しい期間でした。
この場を用意してくださった運営チームの皆さん、および会場でお話ししてくださった皆さんに心から感謝します。
上記で紹介したセッション以外にも非常に興味深いセッションが多くありました。
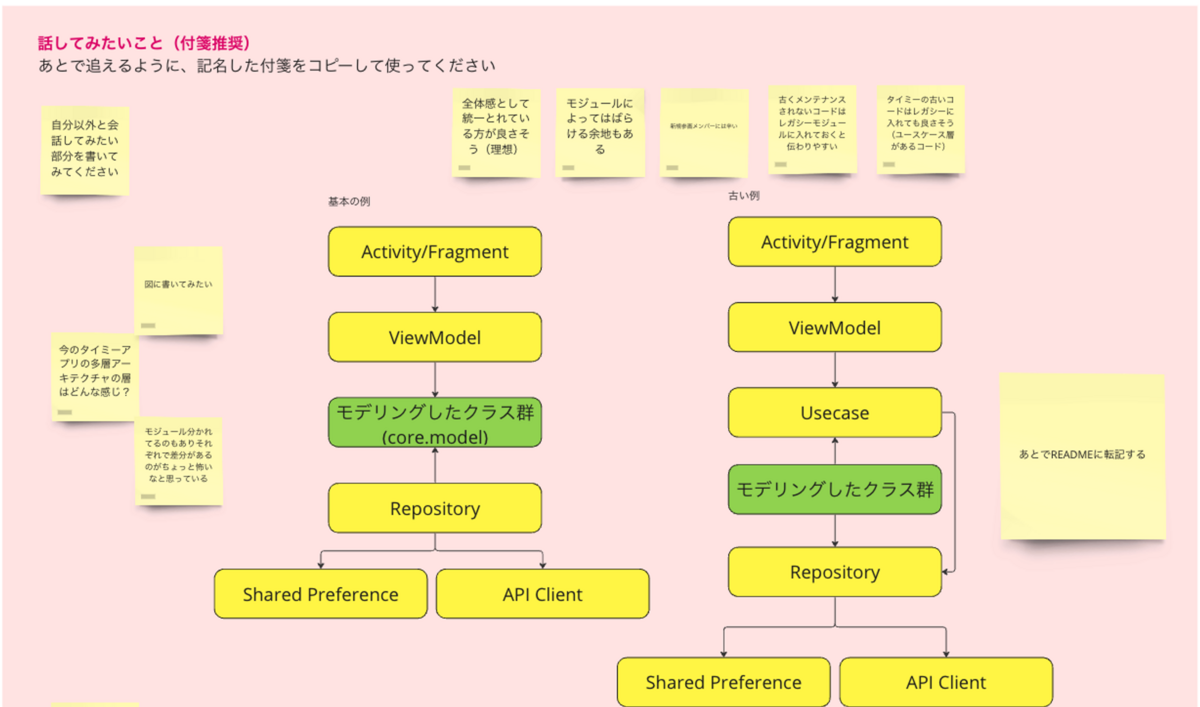
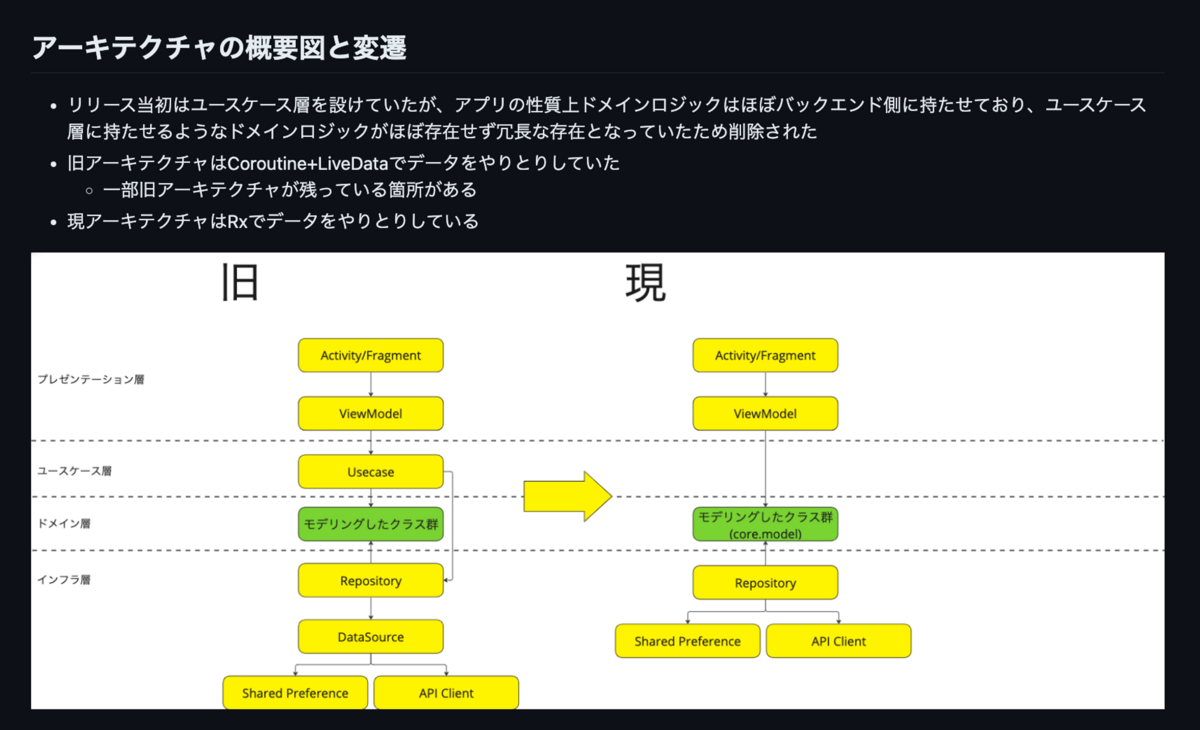
記事にある内容や、その他の内容についても、もしタイミーのエンジニアと話したいという方がいらっしゃればぜひお気軽にお話ししましょう!
product-recruit.timee.co.jp